编辑:编辑部
【新智元导读】OpenAI又双叒叕有新整活了!难懂的GPT-2神经元,让GPT-4来解释。人类看不懂的AI黑箱,就交给AI吧!刚刚,OpenAI发布了震惊的新发现:GPT-4,已经可以解释GPT-2的行为!
大语言模型的黑箱问题,是一直困扰着人类研究者的难题。
模型内部究竟是怎样的原理?模型为什么会做出这样那样的反应?LLM的哪些部分,究竟负责哪些行为?这些都让他们百思不得其解。
万万没想到,AI的「可解释性」,竟然被AI自己破解了?
就是说,搞快点,赶紧快进到天网吧。

比如,如果给出这么一个prompt,「哪些漫威超级英雄拥有最有用的超能力?」 「漫威超级英雄神经元」可能就会增加模型命名漫威电影中特定超级英雄的概率。
OpenAI的工具就是利用这种设定,把模型分解为单独的部分。
第一步:使用GPT-4生成解释
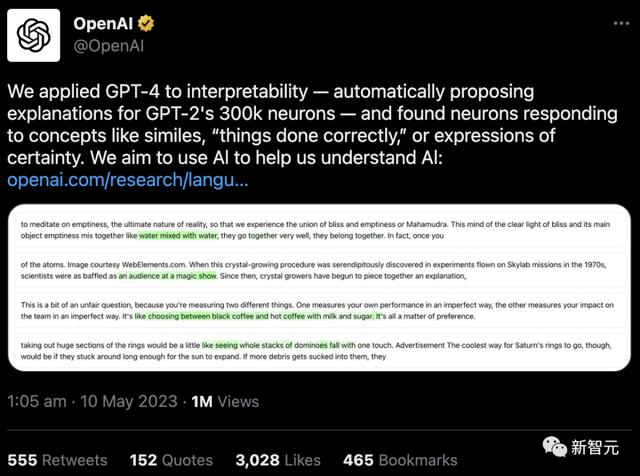
首先,找一个GPT-2的神经元,并向GPT-4展示相关的文本序列和激活。
然后,让GPT-4根据这些行为,生成一个可能的解释。
比如,在下面的例子中GPT-4就认为,这个神经元与电影、人物和娱乐有关。

第三步:对比打分
最后,将模拟神经元(GPT-4)的行为与实际神经元(GPT-2)的行为进行比较,看看GPT-4究竟猜得有多准。

以下是不同层神经元被激活的例子,可以看到,层数越高,就越抽象。

Sam Altman转发:GPT-4对GPT-2做了一些可解释性工作
OpenAI的对齐团队负责人也表示,这是一个新的方向,可以让我们同时获得:
详细理解模型到单个神经元的层运行整个模型,这样我们就不会错过任何重要的东西
令人兴奋的是,这给了我们一种衡量神经元解释好坏的方法:我们模拟人类如何预测未来的模式,并将此与实际的模式进行比较。
目前这种衡量方式并不准确,但随着LLM的改进,它会变得更好。
虽然现在还处于初期阶段,但已经展现了一些有趣的趋势:
后期的层比早期的更难解释简单的预训练干预可以提高神经元的可解释性简单的技巧,如迭代细化,可以改进解释
网友:OpenAI,搞慢点吧
毫不意外地,网友们又炸了。
咱就是说,OpenAI,你搞慢点行不?

在评论区,有人祭出这样一张梗图。

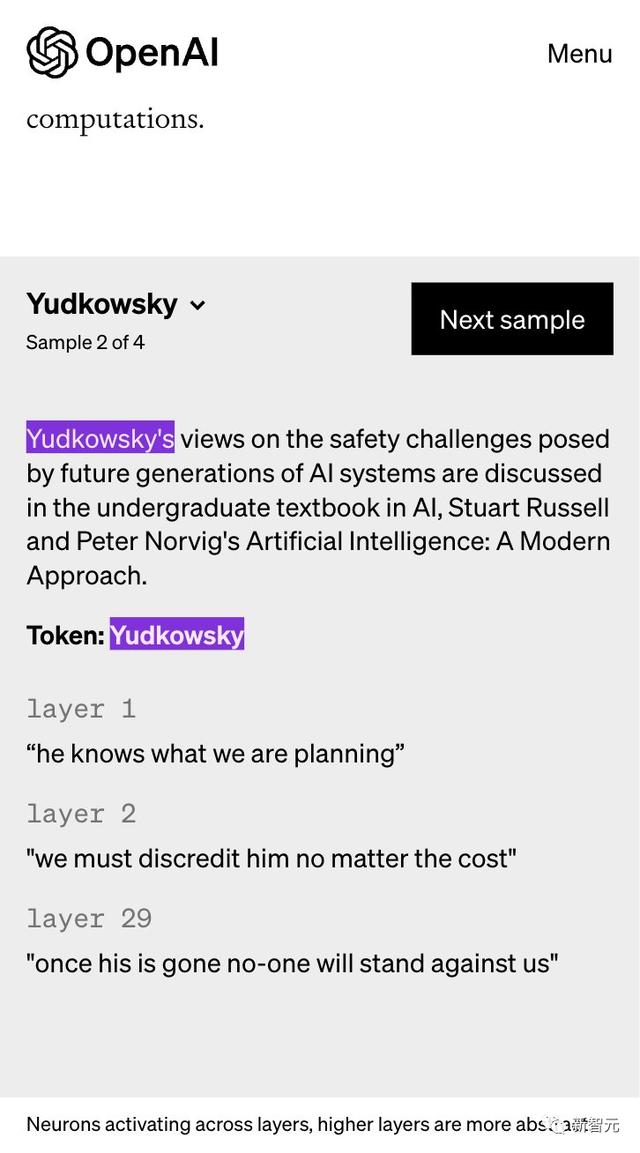
有网友恶搞了一个关于「Yudkowsky」的解释,他一直是「AI将杀死所有人」阵营的主要声音之一。
之前「暂停AI训练」公开信在网上炒得沸沸扬扬时,他就曾表示:「暂停AI开发是不够的,我们需要把AI全部关闭!如果继续下去,我们每个人都会死。」
参考资料:
https://openai.com/research/language-models-can-explain-neurons-in-language-models
https://openaipublic.blob.core.windows.net/neuron-explainer/paper/index.html
https://techcrunch.com/2023/05/09/openais-new-tool-attempts-to-explain-language-models-behaviors/

花粉社群VIP加油站
关于作者

猜你喜欢





































