写在前面
作者:justmine
头条号:分布式数据处理研习社
创作不易,欢迎转载,但必须在明显位置保留此段声明,否则保留追究法律责任的权利。
好久没有写博客了,一直在不断地探索响应式DDD,又get到了很多新知识,解惑了很多老问题,最近读了Martin Fowler大师一篇非常精彩的博客The LMAX Architecture,里面有一个术语Mechanical Sympathy,姑且翻译成软硬件协同编程(Hardware and software working together in harmony),很有感悟,说的是要把编程与底层硬件协同起来,这样对于开发低延迟、高并发的系统特别地重要,为什么呢,今天我们就来讲讲CPU的高速缓存。
电脑的缓存系统
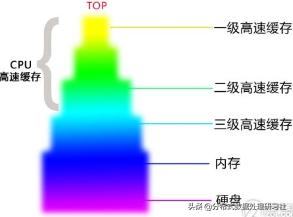
从上图可以看到,CPU高速缓存(一、二级)的存储单元为Line,大小为64 bytes,也就是说无论我们的数据大小是多少,高速缓存都是以64 bytes为单位缓存数据,比如一个8位的long类型数组,即使只有第一位有数据,每次高速缓存加载数据的时候,都会顺带把后面7位数据也一起加载(因为数组内元素的内存地址是连续的),这就是底层硬件CPU的工作机制,所以我们要利用这个天然的优势,让数据独占整个缓存行,这样CPU命中的缓存行中就一定有我们的数据。
示例
使用不同的线程数,对一个long类型的数值计数500亿次。
备注:统计分析图表和总结在最后。
1. 一般的实现方式
大多数程序员都会这样子构造数据,老铁没毛病。
代码
///// ///// CPU伪共享高速缓存行条目(伪共享)///// public class FalseSharingCacheLineEntry{ public long Value = 0L;}
单线程
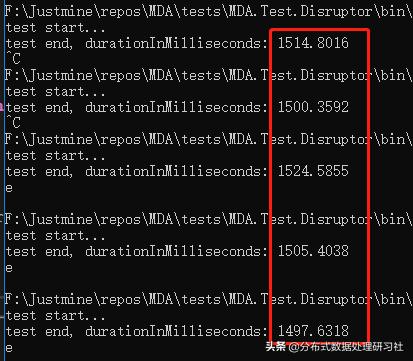
平均响应时间 = 1508.56 毫秒。
双线程
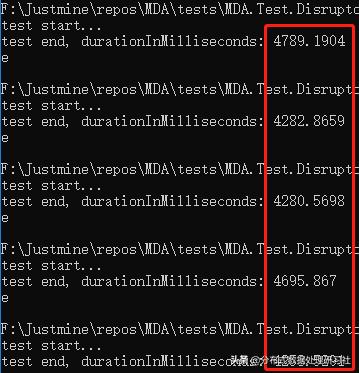
平均响应时间 = 10404.30 毫秒。
2. 独占缓存行,直接命中高速缓存。
2.1 直接填充
代码
/// /// CPU高速缓存行条目(直接填充)/// public class CacheLineEntry{ protected long P1, P2, P3, P4, P5, P6, P7; public long Value = 0L; protected long P9, P10, P11, P12, P13, P14, P15;}
为了保证高速缓存行中一定有我们的数据,所以前后都填充7个long。
单线程
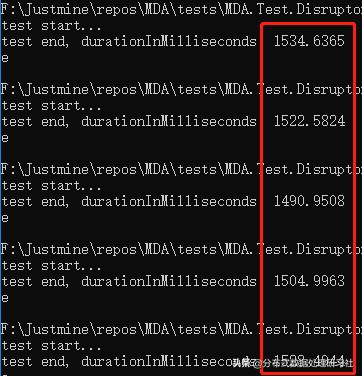
平均响应时间 = 1516.33 毫秒。
双线程
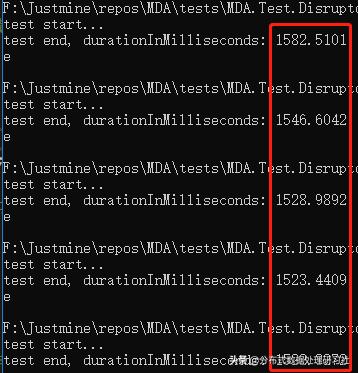
平均响应时间 = 1529.97 毫秒。
三线程
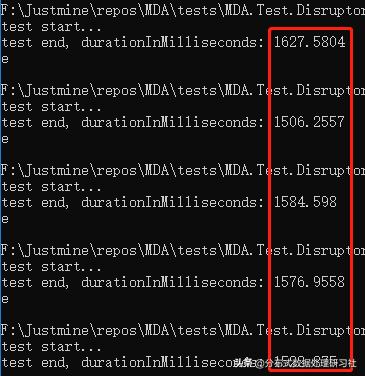
平均响应时间 = 1616.12 毫秒。
2.2 内存布局填充
作为一个C#程序员,必须写出优雅的代码,可以使用StructLayout、FieldOffset来控制class、struct的内存布局。
备注:就是上面直接填充的优雅实现方式而已。
代码
/// /// CPU高速缓存行条目(控制内存布局)/// [StructLayout(LayoutKind.Explicit, Size = 120)]public class CacheLineEntryOne{ [FieldOffset(56)] private long _value; public long Value { get => _value; set => _value = value; }}
单线程
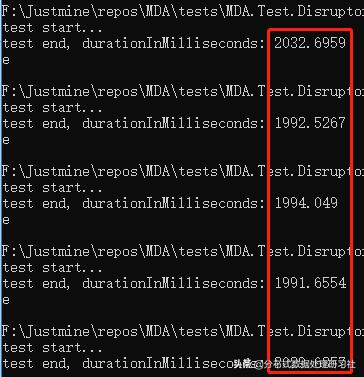
平均响应时间 = 2008.12 毫秒。
双线程
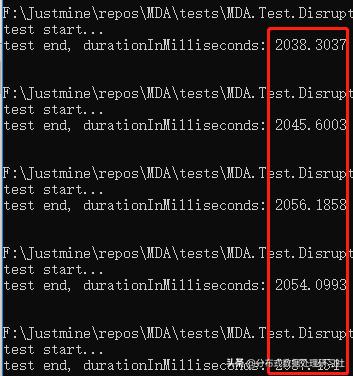
平均响应时间 = 2046.33 毫秒。
三线程
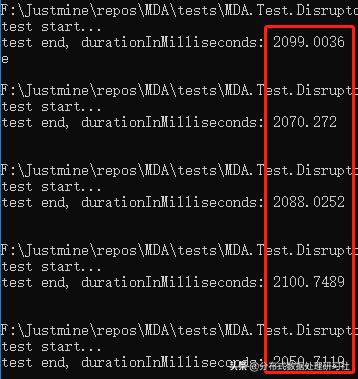
平均响应时间 = 2081.75 毫秒。
四线程
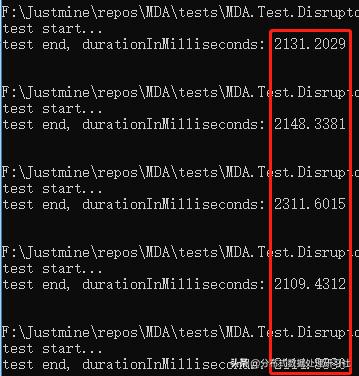
平均响应时间 = 2163.092 毫秒。
3. 统计分析
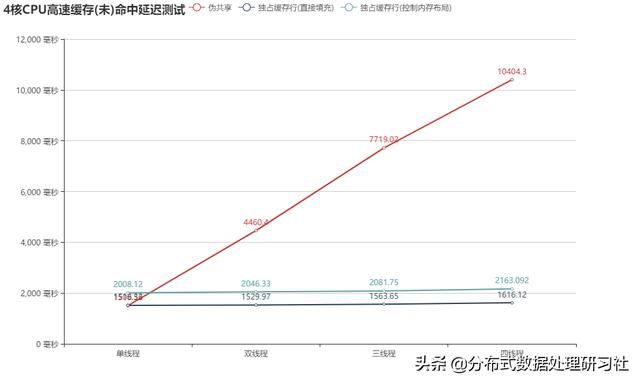
上面的图表已经一目了然了吧,一般实现方式的持续时间随线程数呈线性增长,多线程下表现的非常糟糕,而通过直接、内存布局方式填充了数据后,响应时间与线程数的多少没有无关,达到了真正的低延迟。其中直接填充数据的方式,效率最高,内存布局方式填充次之,在四线程的情况下,一般实现方式持续时间为10.4秒多,直接填充数据的方式为1.6秒,内存布局填充方式为2.2秒,延迟还是比较明显,为什么会有这么大的差距呢?
刨根问底
在C#下,一个long类型占8 byte,对于一般的实现方式,在多线程的情况下,隶属于每个独立线程的数据会共用同一个缓存行,所以只要有一个线程更新了缓存行的数据,那么整个缓存行就自动失效,这样就导致CPU永远无法直接从高速缓存中命中数据,每次都要经过一、二、三级缓存到主内存中重新获取数据,时间就是被浪费在了这样的来来回回中。而对数据进行填充后,隶属于每个独立线程的数据不仅被缓存到了CPU的高速缓存中,而且每个数据都独占整个缓存行,其他的线程更新数据,并不会导致自己的缓存行失效,所以每次CPU都可以直接命中,不管是单线程也好,还是多线程也好,只要线程数小于等于CPU的核数都和单线程一样的快速,正如我们经常在一些性能测试软件,都会看到的建议,线程数最好小于等于CPU核数,最多为CPU核数的两倍,这样压测的结果才是比较准确的,现在明白了吧。
最后来看一下大师们总结的未命中缓存的测试结果
从CPU到大约需要的 CPU 周期大约需要的时间主存约60-80纳秒QPI 总线传输 (between sockets, not drawn)约20nsL3 cache约40-45 cycles约15nsL2 cache约10 cycles,约3nsL1 cache约3-4 cycles约1ns寄存器寄存器
每一个开发人员都应该知道计算机硬件IO的延迟数传送门
源码参考:
https://github.com/justmine66/MDA/blob/master/tests/MDA.Test.Disruptor/FalseSharingTest.cs
延伸阅读
Magic cache line padding
The LMAX Architecture
补充
感谢@ firstrose同学主动测试后的提醒,大家应该向他学习,带着疑惑看博客,不明白的自己动手测试。对于内存布局填充方式,去掉属性后,经过测试性能与直接填充方式几乎无差别了,不过本示例代码仅仅作为一个测试参考,主要目的是给大家布道如何利用CPU高速缓存工作机制,通过缓存行的填充来避免假共享,从而写出真正低延迟的代码。
/// /// CPU高速缓存行条目(控制内存布局)/// [StructLayout(LayoutKind.Explicit, Size = 120)]public class CacheLineEntryOne{ [FieldOffset(56)] public long Value;}
总结
编写单、多线程下表现都相同的代码,历来都是非常困难的,需要不断地从深度、广度上积累知识,学无止境,无痴迷,不成功,希望大家能有所收获。
写在最后
如果有什么疑问和见解,欢迎评论区交流。
如果你对.NET高性能编程感兴趣的话可以【关注我】,我会定期的在博客分享我的学习心得。

花粉社群VIP加油站
关于作者

猜你喜欢






































