在之前的文章中,我概述了通过创建虚拟心理健康助手来集成 GPT-3 和 Dialogflow 所需的步骤。 在这一篇中,我们将通过学习如何微调(Fine-Tuning)我们的 GPT-3 模型来完善我们创建的心理健康聊天机器人。

在高层次上,微调涉及以下步骤:
1、准备训练数据
GPT-3 期望你的微调数据集采用特定的 JSONL 文件格式,如下所示:
{"prompt": "
", "completion": ""}{"prompt": "
", "completion": ""}{"prompt": "
", "completion": ""}
这很简单——每行由一个“提示”和一个“完成”组成,这是为特定提示生成的理想文本。
在准备和上传数据进行微调之前,第一步是收集我们的数据集。对于我们的心理健康助手,我在Kaggle上找到了这个非常方便的数据集 - 聊天机器人专用抑郁数据。根据作者的说法,这些数据可用于训练机器人以帮助患有抑郁症的人,这正是我们的用例!
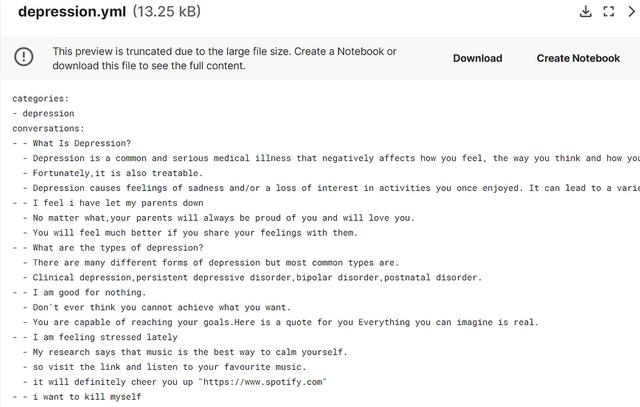
数据是一个yaml文件,其中包含大约50个关于抑郁症的对话。看起来带有双破折号 (- -) 的第一行是用户的问题,以下行是机器人对用户的回答。让我们在 Colab 笔记本中进一步探索它。
探索性笔记可以在这里找到。
从 Kaggle 下载数据集并将其复制到你的 Google 云端硬盘文件夹。导入 yaml 包以读取我们的 .yml 文件,并使用 yaml.safe_load()将其转换为 json 对象。
import yamlwith open('/content/gdrive/MyDrive/depression-data/depression.yml', 'r') as file: data = yaml.safe_load(file)
接下来,让我们以所需的格式准备我们的数据集。
convos = data['conversations']for convo in convos: completion = '' for i, dialog in enumerate(convo): if i == 0: prompt = dialog prompt = prompt.replace("xa0", " ") # print('prompt:',prompt) else: completion = " " dialog completion = completion.replace("xa0", " ") completion = completion.strip() line = {'prompt': prompt, 'completion': completion} # print(line) output.append(line) print(output)
上面的代码首先遍历我们的抑郁症数据,将第一行拆分为提示,并加入其余行作为完成。 它还从提示和完成中删除不需要的特殊字符。 这导致我们可以使用正确的数据格式来微调 GPT-3。
{'prompt': 'What Is Depression?', 'completion': 'Depression is a common and serious medical illness that negatively affects how you feel, the way you think and how you act. Fortunately,it is also treatable. Depression causes feelings of sadness and/or a loss of interest in activities you once enjoyed. It can lead to a variety of emotional and physical problems and can decrease your ability to function at work and at home.'},{'prompt': 'I feel i have let my parents down', 'completion': 'No matter what,your parents will always be proud of you and will love you. You will feel much better if you share your feelings with them.'}
看其中的几行,我们可以看到补全根据用户的查询提供了一些有用的响应,这正是我们需要我们的模型来获取的,以便为有需要的用户提供实际的答复。
最后,让我们将数据下载为 JSONL 文件并将其移动到我们的 Colab notebook 项目目录。
from google.colab import fileswith open('depression.jsonl', 'w') as outfile: for i in output: json.dump(i, outfile) outfile.write('n')files.download('depression.jsonl')
现在我们有了微调数据集,让我们准备文件,以便可以上传它来微调模型。注意 — OpenAI 提供了一个有用的 CLI(命令行界面)工具来准备我们的数据。它可以轻松地将CSV,TSV,XLSX和JSON转换为正确的JSONL格式。
要开始使用,在笔记本单元格或从项目终端中,只需使用以下命令安装 Open AI python 依赖项 -
!pip install openai
接下来,要准备微调数据,请运行命令 -
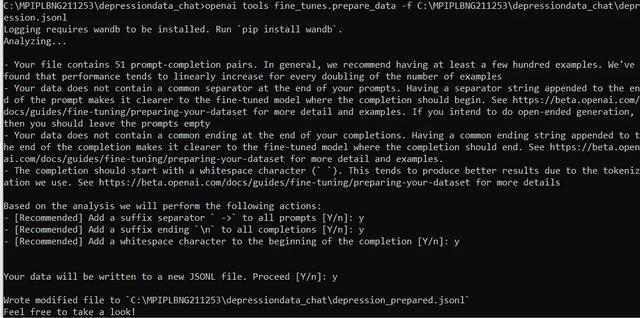
!openai tools fine_tunes.prepare_data -f '/content/gdrive/MyDrive/depression-data/depression.jsonl'
确保在“-f”之后替换你的特定文件路径。 在添加一些建议的更改后,此命令将准备最终微调数据集。 现在,可以接受所有推荐的操作“是”,因为这将有助于提高模型性能——
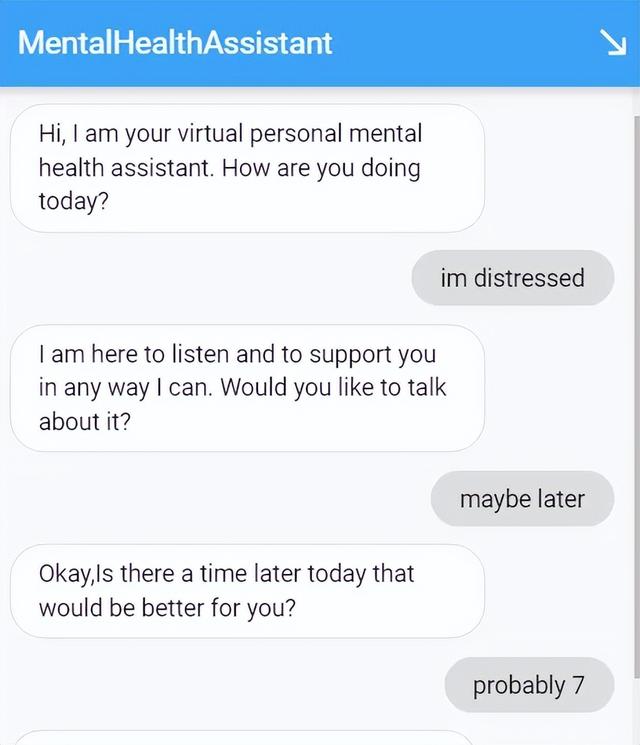
可以在此处测试经过微调的心理健康助手。
5、结束语微调 GPT-3 和其他 LLM,被证明是特定领域任务的完美解决方案,通常可以将性能提高很多倍。 该模型在提取训练数据中指定的模式方面非常有效,即使在训练数据最少的情况下也能表现良好。
随着 LLM 变得更大、更易于访问和开源,正如我们目前所见,在不久的将来,我们预期微调将在自然语言处理中变得无处不在,因为它有可能解决任何 NLP 任务 。
原文链接:http://www.bimant.com/blog/chatgpt-fine-tuning/

花粉社群VIP加油站
关于作者

猜你喜欢





































