
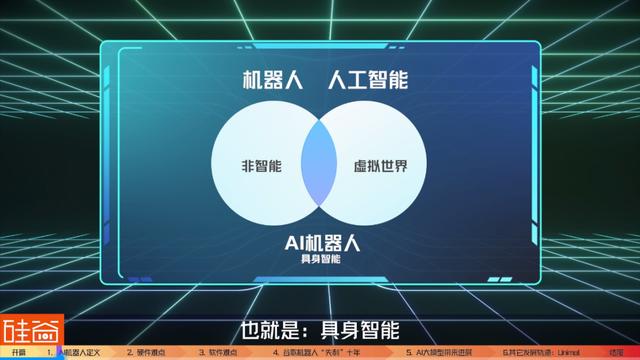
AI机器人和机器人有什么不同呢?或者换个问法,AI机器人和AI有什么不同呢?
这幅图就能简单解答这两个问题:机器人可以分别两类,一类是非智能机器人,一类是有智能机器人,AI机器人。同时人工智能也有两类,一个是虚拟世界中的,比如说ChatGPT,还有一个就是有手有脚能在真实世界中交互的。这幅图就是机器人和人工智能交接的这个赛道,就是有智能的AI机器人,也就是:具身智能。
我们再来分拆一下机器人的软件部分:当我们给机器人一个任务的时候,比如,从一堆娃娃的袋子里去拣起其中一个特定的娃娃,机器人的软件系统一般要经历以下的三层:
第一层:理解任何需求和环境(perception)
机器人会通过传感器了解周围环境,搞明白,装娃娃的袋子在哪里?袋子在桌上还是地上,整个房间长什么样?我要去挑的娃娃长什么样子?
第二层:拆解成任务(behavior planning)和路径规划(motion planning)
明白任务之后,机器人需要将任务拆解成:先去走过去,举起手臂,识别娃娃,捡起来,再把娃娃放在桌上。同时,基于拆分好的步骤,计划好,我应该用轮子跑多远,机械臂该怎么动,怎么拿取物体,使多大劲儿等等。
第三层:驱动硬件执行任务(execution)
把运动规划转变成机械指令发到机器人的驱动系统上,确定能量、动量、速度等合适后,开始执行任务。

所以,数据是人工智能的根基,就算是世界最顶级的AI公司,也会为机器人领域没有数据发愁。不管是文字、图片、视频、还是编程的大语言模型,都有全互联网海量的数据用来训练,才能在今天实现技术的突破。但是机器人用什么数据训练呢?那需要在真实世界中亲自采集数据,并且目前不同机器人公司、不同机器人的训练数据还不能通用,采集成本也非常高。
比如你要训练机器人擦桌子,人类要远程操控这台机器人给它演示,配上这个动作的文字描述,成为一个个数据点。你以为一个任务演示一遍就行了吗?当然不是,你运行的时候得从各个角度、各个不同的传感器采集数据,甚至不同的光影效果的数据也都得采集,不然你的机器人就只能白天擦桌子,晚上擦不了,左边能擦,右边擦不了。
再比如说,训练谷歌的RT-1模型用的数据集有700个任务的13万个数据点,13台机器人花了17个月才采集完,时间花了这么多,但采集的效率非常的低下。
做个对比,ChatGPT的训练数据估计有3000亿个单词,13万和3000亿,这个对比是不是太明显了。也难怪当年OpenAI放弃机器人,去All in语言大模型了,因为明显后者的数据参数更好采集。
人的交互过程中有55%的信息通过视觉传达,如仪表、姿态、肢体语言等;有38%的信息通过听觉传达,如 说话的语气、情感、语调、语速等;剩下只有7%来自纯粹的语义,所以ChatGPT这样的人工智能聊天助手能输入的部分仅占人类交互中的7%。而要让人工智能达到具身智能,那么剩下的信息,视觉,肢体,听觉,触摸等方式的数据采集,是需要给到机器人去学习的。

有没有什么低成本的数据采集方法呢?现在的做法是:在虚拟世界中训练机器人,也就是模拟,Simulation。
目前,大多机器人公司的路径都是先在模拟器中训练机器人,跑通了再拿到真实事件中训练。比如说谷歌之前的EveryDay Robots就大量运用了模拟技术,在他们的模拟器中有2.4亿台机器人在接受训练,在模拟的加持下,训练机器人拿东西这个任务,原来需要50万个数据,在模拟的帮助下现在只需要5000个数据了。各个角度、不同光影的数据也可以被自动化,不用一个一个采集了。
但是,Simulation也不是万能的解决方案,首先它本身的成本也不低,需要大量的算力支持;其次虚拟世界和真实世界依旧存在着巨大的差距,在虚拟世界跑通的事儿,到了真实世界可能会遇到无数的新问题,所以,数据收集的挑战依然是巨大的。
所以讲到这里,我们总结一下,数据采集难,三层任务AI化难,再加上对硬件的控制和整合,其中的统一性和准确性都是非常严峻的难题。在过去十年,AI机器人的发展并没有人们一度想象中那么乐观。并且,在实验室中看似已经解决的问题,到了实验室外的商用探索中,又出现了各种新的问题。
讲到这里,我们就不得不说说谷歌十年押注AI机器人但最终没能成功的故事,其实也反映了AI机器人上的发展困境。
04 AI谷歌十年“整合”AI机器人的失利
讲谷歌失败的的机器人发展线并不仅仅是因为谷歌的办公室政治和性丑闻,而是想说明AI机器人行业发展的一个缩影:AI机器人在软件和硬件上还都需要解决的问题太多、挑战太大。
而现在,重要的问题来了,ChatGPT的出现,能否打破这个僵局呢?
05 最新AI热潮能带来进展
所以,这篇论文得到的结论是,DERL深度进化强化学习使得大规模模拟成为现实,通过学习形态智能的进化过程可以加速强化学习。而李飞飞博士也表示:“具身的含义不是身体本身,而是与环境交互以及在环境中做事的整体需求和功能”。也就是说,将进化论放进人工智能领域,用“具身智能”而非纯粹的“算法智能”,来加快人工智能机器人的进化速度,也许是能更快推进具身智能前进的方式。
目前,研究依然还是非常早期的阶段,所有训练也还只在的模拟器中,但这已经让之后的具身智能发展充满了各种悬念:最终出现在我们面前的具身智能,可能不是我们想象中的机器人形态,更有可能是一种浑身插满各种木棍儿的小人也说不定。
所以,我们这个视频在结尾得到的结论就是:AI机器人,也就是具身智能的发展,没那么容易。这个赛道还没有等到自己的ChatGPT时刻,我们开头描述的那些场景距离实现还早着呢,所以大家既不用担心终结者很快到来、也不用兴奋很快会有AI机器人能帮我们去遛狗排队买咖啡。
但是,具身智能的出现,是“机器人”Robot这个词最开始发明的时候,就在人类的想象中的。
大家猜猜英文Robot是怎么来的?
这个词最早其实出现在1920年捷克文学家卡雷尔·恰佩克的三幕剧《罗素姆万能机器人》(Rossum's Universal Robots),而Robot这个词源于捷克语的“robota”,意思是“苦力”和“奴隶”的意思,之后成为了机器人的专有名词。
而这个三幕剧讲的什么故事呢?
这个故事讲述的是,罗素姆这个工厂大规模制造和生产机器人,本来初衷是完成所有人类不愿做的工作和苦差事,从而解放人类投身于更美好、更高的事物。但后来,机器人发觉人类十分自私和不公正,终于造反了,因此消灭了人类。但是,机器人不知道如何制造自己,认为自己很快就会灭绝,所以它们开始寻找人类的幸存者,但一直没有找到。最后,一对感知能力优于其它机器人的男女机器人相爱了。这时机器人进化为人类,世界又起死回生了。
100多年前,机器人Robot这个词诞生的时候,小说家卡雷尔·恰佩克似乎就觉得终有一天,具身智能会来到人类世界,并且和人类的关系变得破朔迷离,机器人可以消灭人类,也可以进化为人类。我不知道是否有一天,这个幻想的故事会真实抵达我们的世界,但稍微能安抚大家的是,至少在现在,我们依然距离这个故事还很遥远。
文 |Jeremy Bao Junwu Zhang 陈茜
编辑|陈茜
排版|何源清

花粉社群VIP加油站
关于作者

猜你喜欢





































