AI 带来的惊奇越来越多了,前有 Stable Diffusion 的 AI 绘画让画师高呼职业生涯结束,后有 ChatGPT 让无数程序员、文字编辑越用越心凉。甚至很多用户在对比谷歌搜索和 ChatGPT 之后,已经喊出「谷歌完蛋了」。
AI 的进化实在太快。
上周,顶着明星光环的 OpenAI 发布了 ChatGPT——一个自然语言生成式 AI,发布后很快就在小范围内流行起来,随后持续发酵,大量的对话截图开始涌现在 Twitter、即刻、微博及朋友圈,并风靡全网。
从敲代码、写稿、推荐到教你学英语、写小说,甚至是一场类似人类之间的对谈,ChatGPT 都表现出现了惊人的语言能力。
甚至有 TikTok 工程师通过一步步引导在 ChatGPT 中实现了一门新的编程语言——GPTLang:

图/@Tisoga
与此同时,惊人的语言能力也让互联网上「人类」和「AI」的界限越来越模糊,Twitter 网友@clowwindy 就发布了一串推文 ,讨论了 ChatGPT 使用泛滥可能导致社交媒体上充斥更多、威胁更大的虚假信息:
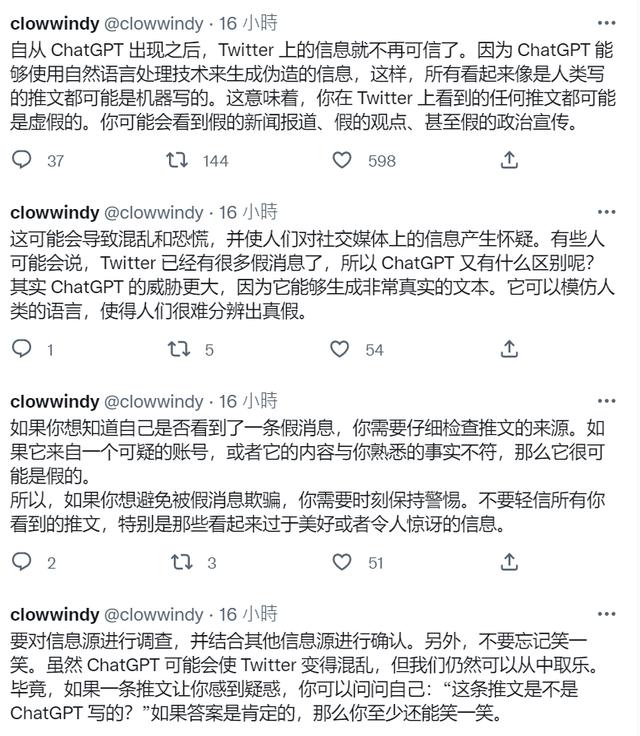
图/@clowwindy
讽刺的是,@clowwindy 最后揭晓这一系列推文讨论实际都是由 AI 编写完成。
程序员同样也「震惊」了。国内程序员社区 V2EX 有用户就在「程序员」节点发表了一则帖子,名为《体验了下 chatGPT,越玩心越凉》。
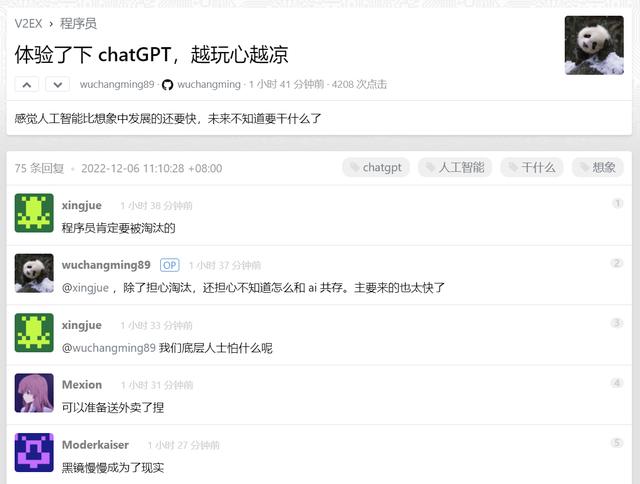
图/OpenAI
DALL·E 2 专注文本生成图像,ChatGPT 被定位于人机对话,他们都是身后的 OpenAI 公司在 AI 应用与商业化上的尝试。
事实上,OpenAI 经历过两个阶段。在第一个阶段,创始人伊隆·马斯克以及知名创业孵化器公司 Y Combinator 时任总裁山姆·柯曼,出于对强人工智能的担忧成立了非营利组织 OpenAI,目标是与其他机构和研究者在 AI 上进行合作,并向公众开放专利和研究成果。
到第二个阶段,马斯克由于特斯拉在自动驾驶上的利益冲突,选择退出 OpenAI 董事会。随后,OpenAI 于 2019 年成立了「营利性质的」子公司 OpenAI LP。山姆·柯曼为此从 YC 离职后专注于 OpenAI LP CEO 一职,随后还拉来微软 10 亿美元的入股与合作,并开始了 AI 商业化的探索。
在 GPT-3 模型发布后,OpenAI 就将模型以 API 形式向开发者客户有偿提供,开发者可以通过 API 利用 GPT-3 的能力,据官网显示目前已有 300 多名开发者在 App 上利用上了 GPT-3。
DALL·E 和 ChatGPT 也是 OpenAI 商业化探索的一部分。前者已经在图片领域掀起了滔天巨浪,后者更有着巨大的想象空间,从最初级的客服到程序生成,甚至是成为新型搜索引擎。
AI 超神,但远不完美ChatGPT 目前仍然处于公测状态,一方面既是希望搜集大众的使用反馈并对 AI 进行新的改进,另一方面也意味着 ChatGPT 还处在一个优化迭代的阶段。但即便如此,ChatGPT 在搜索、内容创作辅助和编程协助场景上已经带来太多惊喜。
开发者发现 ChatGPT 不仅能写完整代码,原来还能用来修 bug,甚至还会对此进行解释:
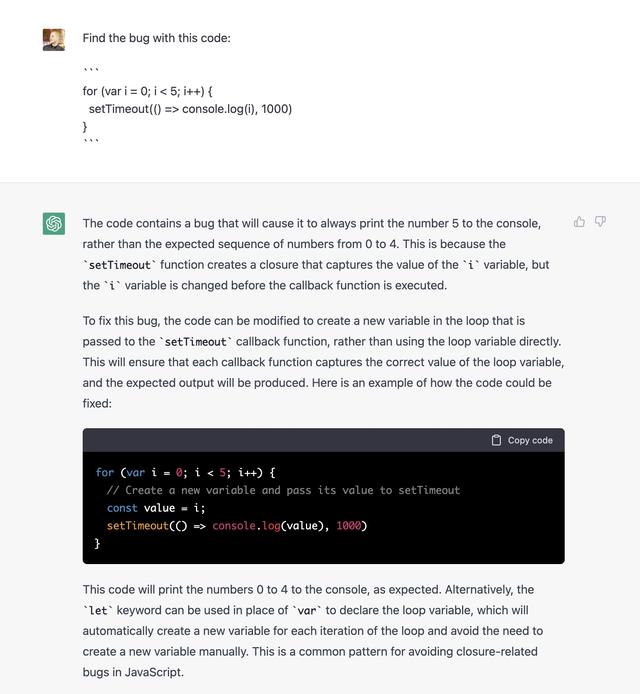
图/@amasad
也能用来辅助写代码。独立开发者 TualatriX 就展示了 ChatGPT 如何辅助写代码的过程,并评价其「比 GitHub Copilot 还要好用」:
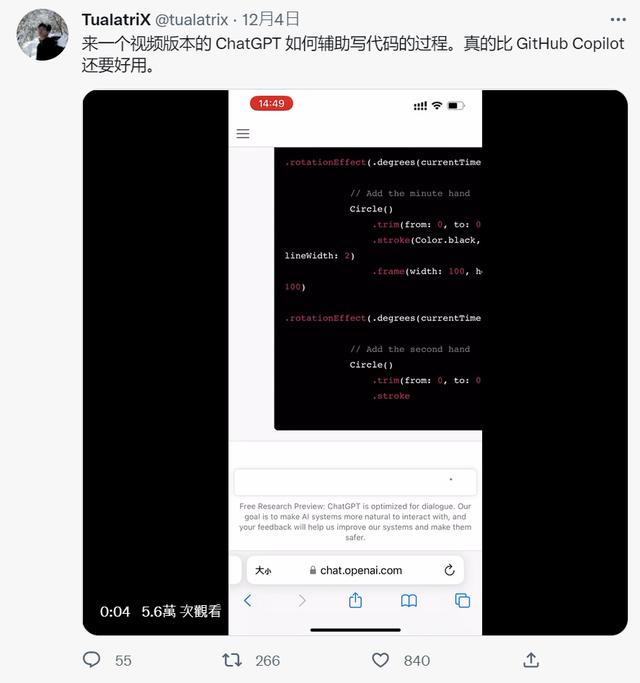
图/TualatriX
从开发者群体的反馈来看,普遍都惊叹于 ChatGPT 在写代码上的实力。
不仅如此,ChatGPT 甚至还能写产品路线图和求职信:
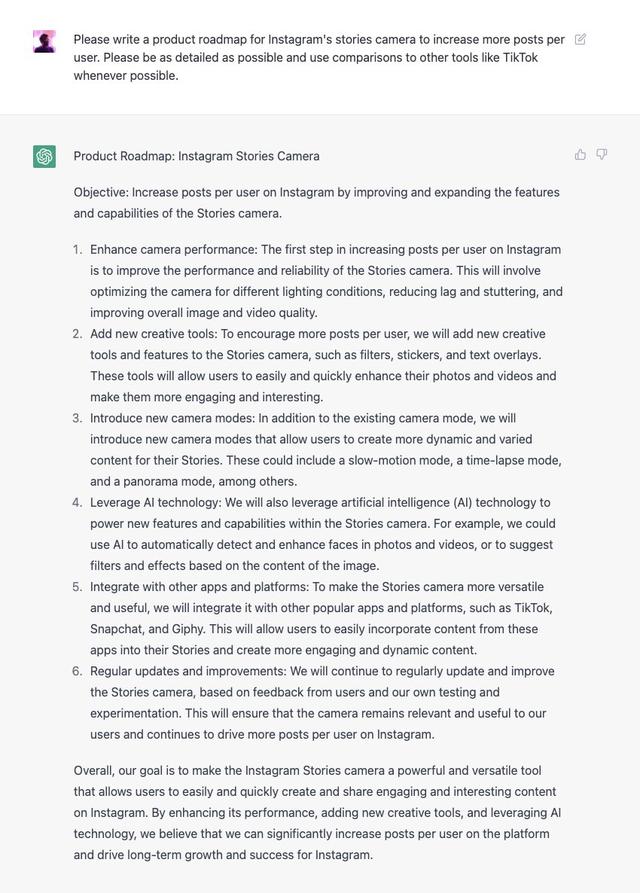
写一份 Instagram Story Camera 的产品路线图,图/Twitter 截图
就算是数学公式,ChatGPT 给出的回答不仅呈现方式更好,还进行了更全面的解释:
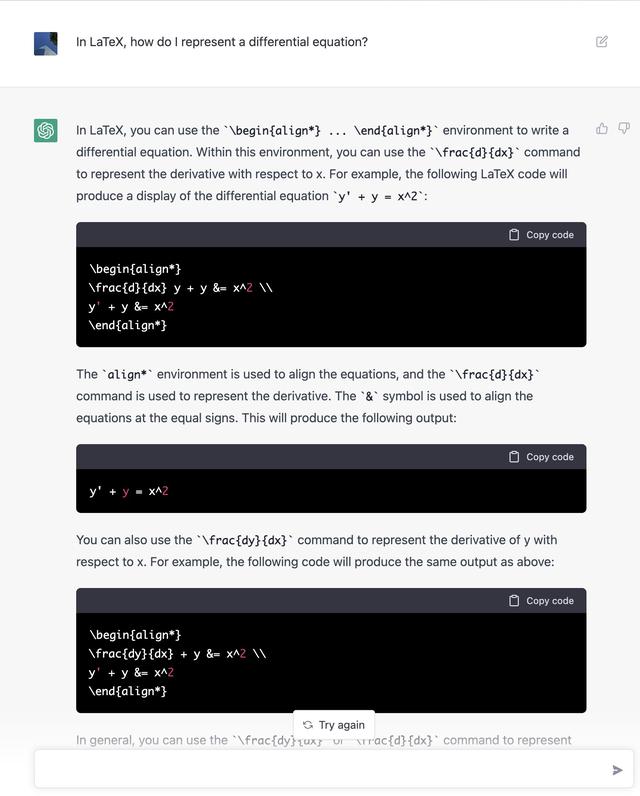
图/@levie
过去几年,AI 技术的应用一直是科技巨头的重点,微软、亚马逊、Meta 以及谷歌数次推出过类似 ChatGPT 的对话式 AI。
2016 年微软就推出过 AI 聊天机器人 Tay,微软宣称用户与 Tay 聊得越多,它就越聪明。但事实是聊得越多,Tay 越是变得满口脏话和反主流言论,它的中国姐妹小冰也是同样。
今年 8 月,谷歌也推出了新的对话式 AI Lamda,直接表示 AI 不会从与使用者的互动当中学习,以避免重蹈微软的覆辙,但也切断了 Lamda 在对话中成长的可能。
ChatGPT 没有选择这种思路,而是在先期就设置了安全规范,避免 AI 在与用户互动中学习到色情、暴力等知识。
从目前来看,ChatGPT 绝对是对早期对话式 AI 的巨大改进,安全设置也避免 ChatGPT 面对毁灭世界、色情和暴力等要求时一口回绝,但在用户一步一步的问题引导下,ChatGPT 还是出现了「毁灭人类计划书」,甚至还给出了部分 Python 代码。
去年,OpenAI 就承认他们所做的改进并不能消除大型语言模型中固有的毒性问题。GPT-3 接受了超过 600GB 网络文本的训练,其中一部分来自具有性别、种族、身体和宗教偏见的社区。与其他大型语言模型一样,它会放大训练数据的偏差。
问题是当 OpenAI 将 ChatGPT 正式推向市场,面对海量的用户和一步一步的引导之后,会发生什么?
题图来自 OpenAI

花粉社群VIP加油站
关于作者

猜你喜欢





































