 【新智元导读】拥有1750亿参数的GPT-3取得了惊人的进步,但它并不是通用人工智能。GPT-3让我们看到了语言模型的能力,能否利用这种能力构建出一个模型,更好地理解周围的世界?
【新智元导读】拥有1750亿参数的GPT-3取得了惊人的进步,但它并不是通用人工智能。GPT-3让我们看到了语言模型的能力,能否利用这种能力构建出一个模型,更好地理解周围的世界?
尽管有关 GPT-3的传说四起,但它本身并不是 AGI。
虽然在某些领域接近了人类能力(下棋或写作真的令人印象深刻) ,但它们好像做不出通用的智能,很多时候,GPT-3跟 AlphaGo 更像。
随着加入更多的参数和计算,损失不断下降
第一个问题的答案是完全有可能,这是 GPT-3的主要特点。
第二个问题的答案是... 没人知道。
目前,我们只能看到 GPT-3在世界建模方面表现更好了,但还远远不够。
当有1万亿,10万亿,100万亿参数的模型可用时,我们需要很长一段时间来验证这个假设是否正确。如果 GPT-x 展示了在现实世界中不可思议的预测能力,那么这可能会奏效。
语言模型如何找到「亚马逊上最便宜的曲别针」然而,世界模型本身并不是智能体创造的。那么,怎样才能把一个世界模型变成一个智能体呢?
首先,我们需要一个目标,比如Paperclip maximizer。
Paperclip maximizer是一个经典的思想实验,它展示了一个AGI,即使是一个设计合理且没有恶意的智能,也可能毁灭人类。这个思想实验表明,表面看来友善的人工智能也可能构成威胁。
选择Paperclip maximizer作为目标,可以融入人类价值观的偶然性:一个极其强大的优化器(一个高度智能的AI)可以寻找与我们完全不同的目标 ,比如消耗我们生存所必需的资源来获得自我提升。
然后,构建世界模型的问题,就转变为「采取什么行动来最大化这个目标」。
看似很简单,对吧?实则不然,问题在于我们的世界模型可能无法预测到接下来所有的可能。

GPT-3告诉你获取更多曲别针的方法(来源: OpenAI API)
那么,我们能做些什么呢?向模型询问给定的世界状态下可以做的事情,这在GPT-3的能力范围。
如果去亚马逊说「我要买曲别针」,平台会按照价格进行排序,你选定了一款,那花100块能买到多少曲别针?
用语言模型处理的话,「曲别针」后面接「价格」的可能性很高,而「价格」后面有一系列的价格列表。我们就可以快速计算出有哪些曲别针可选,以及买特定的曲别针要花多少钱(每个步骤序列给智能体带来的回报)。
所以现在,为了估计任何操作的状态动作值,我们可以简单地用 Monte Carlo 树来搜索!
从给定的智能体状态开始,我们使用世界模型展开动作序列。通过整合所有的结果,我们可以知道智能体每个行动可以得到多少预期报酬。
然后,我们可以使用一个带有状态动作值函数的贪婪策略,来决定要采取的动作。
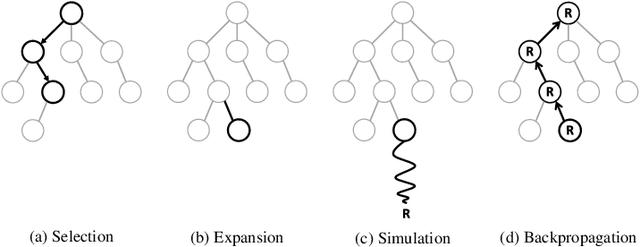
蒙特卡洛树搜索
每一个动作都可能是非常高级的,比如「找出买曲别针最便宜的方式」 ,但得益于语言的灵活性,我们可以用简短的token序列来描述非常复杂的想法。
一旦智能体决定了一个行动,为了实际执行这些抽象行动,这个行动可以使用语言模型分解成更小的子目标,比如「找出亚马逊上最便宜的曲别针」 ,类似于层次强化学习。
根据模型的能力和动作的抽象程度,甚至可以将动作分解成一个详细的指令列表。我们也可以将智能体的状态表示为自然语言。
由于智能体状态只是观测值的压缩表示,因此我们可以让语言模型对任何观测值的重要信息进行汇总,以表示其自身的内部世界状态。语言模型也可以用来周期性地删除(即忘记)状态中的信息,以便为更多的观测留出空间。
这样我们就能得到一个系统,它可以从外部世界传递观测信息,花一些时间思考该做什么,并用自然语言输出一个动作。
打头的是一个输入模块,可以将各种观测转换为与当前智能体状态相关的摘要文本。例如,网页、声音、图像都可以想办法转换为文本并映射到智能体的状态。
最后,为了让模型在现实世界真正发挥作用,可以再次使用语言模型将自然语言翻译成代码、 shell 命令、按键序列等许多可能的方式。
像输入一样,有无数种不同的方法来解决输出问题,哪一种方法是最好要看你的具体使用场景了,最重要的是,可以从纯文本智能体中获得各种形式的输入和输出。

一个输入模块的示例,该模块采用截图输入与当前智能体状态相结合的方式,将图片信息转换为智能体的观测。
当然,这更像一个思想实验上文所描述的,更像是一个思想实验,而不是明天将要发生的事情。
这种方法在很大程度上依赖于一个主要假设——更大的未来模型将具有更好的世界建模能力。然而,这可能是我们有史以来最接近AGI的机会:现在有了一条通往 AGI 的具体路径。
这个路径听上去不那么「扯淡」,未来能否实现让我们拭目以待。

花粉社群VIP加油站
关于作者

猜你喜欢





































