机器之心报道
编辑:陈萍
它被命名为 WebGPT,OpenAI 认为浏览网页的方式提高了 AI 解答问题的准确性。
如果 AI 学会上网,那么它就拥有了无限获取知识的方式,之后会发生什么就不太好预测了。于是著名 AI 研究机构 OpenAI 教那个开启了通用人工智能大门、体量巨大的人工智能模型 GPT-3 学会了上网。

论文地址:https://cdn.openai.com/WebGPT.pdf
模型训练
如此智能的模型是怎么实现的呢?
总体而言,OpenAI 对 GPT-3 模型家族的模型进行了微调,重点研究了具有 760M、13B 和 175B 参数的模型。从这些模型出发,OpenAI 使用了四种主要的训练方法:
行为克隆(Behavior cloning,BC):OpenAI 使用监督学习对演示进行了微调,并将人类演示者发出的命令作为标签;建模奖励(Reward modeling,RM):从去掉 unembedding 层的 BC 模型开始,OpenAI 训练的模型可以接受带有引用的问题和答案,并输出标量奖励,奖励模型使用交叉熵损失进行训练;强化学习(RL):OpenAI 使用 Schulman 等人提出的 PPO 微调 BC 模型。对于环境奖励,OpenAI 在 episode 结束时获取奖励模型分数,并将其添加到每个 token 的 BC 模型的 KL 惩罚中,以减轻奖励模型的过度优化;剔除抽样(best-of-n):OpenAI 从 BC 模型或 RL 模型(如果未指定,则使用 BC 模型)中抽取固定数量的答案(4、16 或 64),并选择奖励模型排名最高的答案。对于 BC、RM 和 RL,OpenAI 使用了相互不相交的问题集。总结来说,BC 中,OpenAI 保留了大约 4% 的演示作为验证集。RM 中,OpenAI 使用了不同大小模型(主要是 175B 模型)对比较数据集答案进行采样,使用不同方法和超参数的组合进行训练,并将它们组合成单个数据集。最终奖励模型经过大约 16,000 次比较的训练,其余 5,500 次用于评估。而 RL 中采用混合的方式,其中 90% 问题来自 ELI5,10% 问题来自 TriviaQA。
结果
ELI5 结果
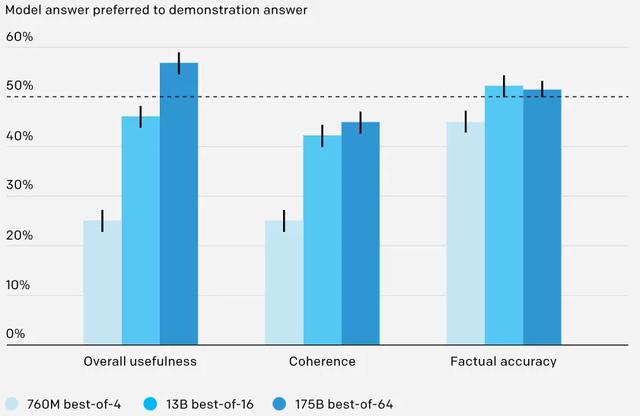
模型经过训练可以回答来自 ELI5 的问题,OpenAI 训练了三种不同的模型(760M、13B 和 175B),对应于三种不同的推理时间计算预算。OpenAI 表现最好的模型(175B best-of-64)产生的答案在 56% 的时间里比人类演示者写的答案更受欢迎。尽管这些是用于训练模型的同一种演示,但我们能够通过使用人工反馈来改进模型的答案以进行优化。
TruthfulQA 结果。
评估实时准确性
为了提供正确的反馈以提高事实准确性,人类必须能够评估模型产生的回答。这可能是个极具挑战性的任务,因为回复可能是技术性的、主观的或含糊不清的。出于这个原因,开发者要求模型引用其回答的来源。
经过测试,OpenAI 认为 WebGPT 还是无法识别很多细微差别,人们预计随着人工智能系统的改进,这类决策将变得更加重要,需要跨学科研究来制定既实用又符合认知的标准。或许辩论的方式可以缓解这些问题。
部署和训练的风险
因为生成错误陈述的几率更低,WebGPT 显然比 GPT-3 更加优秀,但它仍然存在风险。带有原文引用的答案通常被认为具有权威性,这可能会掩盖 OpenAI 新模型仍然存在基本错误的事实。该模型还倾向于强化用户的现有信念,研究人员们正在探讨如何最好地解决这些问题。
除了出错和误导之外,通过让 AI 模型访问网络的方法训练,为该研究引入了新的风险。对此 OpenAI 表示人工智能的浏览环境还不是完全的网络访问,是通过模型将查询请求发送到 Microsoft Bing Web Search API 并关联网络上已有链接实现的,这可能会产生副作用。
OpenAI 表示,根据对 GPT-3 的已有经验,该模型似乎不足以危险地利用这些与外界互联的方式。然而,风险会随着模型能力的增加而增加,研究人员正在努力建立针对它们的内部保护措施。
OpenAI 认为,人类的反馈和 Web 浏览器等工具为实现稳定可信,真正通用的 AI 系统找到了一条有希望的途径。尽管目前的语言大模型还面临很多未知和挑战,但人们在这个方向上仍然取得了重大进展。
参考链接:
https://openai.com/blog/improving-factual-accuracy/

花粉社群VIP加油站
关于作者

猜你喜欢





































