编辑:好困 yaxin
【新智元导读】古代文人,或一觞一咏,畅叙幽情,或风乎舞雩,咏而归。「吟诗作对」成为他们的标配。刚刚,全球最大人工智能巨量模型「源1.0」发布,能赋诗作词,比人类还像人类。
理科生文艺起来,可能真没文科生什么事儿了。

图源:writeup.ai
数据方面,「源1.0」几乎是把近5年整个中文互联网的浩瀚内容全部「读」完了。通过自研的文本分类模型,获得了5TB高质量中文数据集,在训练数据集规模上领先近10倍。
此外,「源1.0」还阅读了大约2000个亿词。这是什么概念呢?
假如人一个月能读十本书,一年读一百本书,读50年,一生也就读5000本书,一本书假如20万字,加起来也只有10亿字,需要一万年才能读完2000亿词。在如此大规模的数据加持下,「源1.0」的数据集也自然成为了全球最大的高质量中文数据集。
算力方面,「源1.0」共消耗约4095PD(PetaFlop/s-day)。相对于GPT-3消耗3640PD计算量得到1750亿参数,计算效率大幅提升。如果说,让「源1.0」一天24小时不间断「阅读」的话,只需要16天就可以看完近五年中文互联网的几乎全部内容。
嗯?原来已经把近5年的中文互联网内容全学完了?
u1s1,「源1.0」yyds!

当前,语言模型的训练已经从「大炼模型」走向「炼大模型」的阶段,巨量模型也成为业界关注的焦点。
近日,李飞飞等斯坦福研究者在论文中阐述了类巨量模型的意义在于突现和均质。在论文中,他们给这种大模型取了一个名字,叫基础模型(foundation model),并系统探讨了基础模型的机遇与风险。
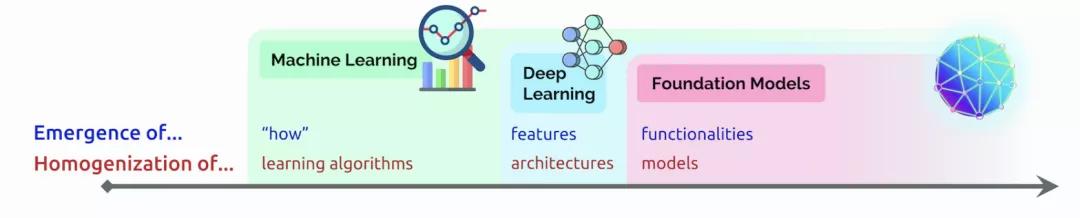
图源:跨象乘云
那么,开发者们能从这块「黑土地」上得到什么?
浪潮源1.0大模型只是一个开始,它只是提供一片广阔的肥沃土壤。
浪潮未来将定向开放大模型API,服务于元脑生态社区内所有开发者,供全球的开发人员在平台上开发应用于各行各业的应用程序。
各种应用程序可以通过浪潮提供的 API进行基于大模型的搜索、对话、文本完成和其他高级 AI 功能。
其实,不管是1750亿参数,还是2457亿巨量参数语言模型,最重要的是它能否真正为我们所用。要说上阵,真正的含义并不是在发布会上的首秀,而是下场去在实际场景中发挥它的作用和价值。
浪潮信息副总裁刘军表示,「首先从大模型诞生本身来说,还有另外一个意义,那便是对于前沿技术的探索,需要有大模型这么一个平台,在这个平台上才能支撑更进一步的创新。」
「其次,在产业界我们很多产业代表提出来的杀手级的应用场景,比如说运营商智能运维,在智能办公场景报告的自动生成,自动对话智能助手。」
「源1.0」大模型能够从自然语言中「识别主题并生成摘要」的能力,让各行各业公司的产品、客户体验和营销团队更好地了解客户的需求。
例如,未来大模型从调查、服务台票证、实时聊天日志、评论等中识别主题、情绪,然后从这个汇总的反馈中提取见解,并在几秒钟内提供摘要。
如果被问到「什么让我们的客户对结账体验感到沮丧?」
大模型可能会提供这样的见解:「客户对结账流程感到沮丧,因为加载时间太长。他们还想要一种在结账时编辑地址并保存多种付款方式的方法。」
未来,浪潮源1.0大模型将推动创新企业及个人开发者基于大模型构建智能化水平更高的场景应用,赋能实体经济智能化升级,促进经济高质量发展。
图灵测试答案对话
问题1
B
问题2
A
问题3
B
问题4
A
对联
问题1
A
问题2
B
问题3
B
问题4
A
诗歌
问题1
A
问题2
B
问题3
B

花粉社群VIP加油站
关于作者

猜你喜欢





































