 “AIIADNN benchmark V0.5”评估的标准较为严苛,包含四大典型场景和两大类评测指标等,指标包含速度(fps)和算法性能,如top1 、top5、mAP、mIoU、PSNR等。同时,这也是深度学习处理器领域首次区分整型和浮点对比的Benchmark。福州瑞芯微电子的RK3399开发板展现出抢眼数据。
“AIIADNN benchmark V0.5”评估的标准较为严苛,包含四大典型场景和两大类评测指标等,指标包含速度(fps)和算法性能,如top1 、top5、mAP、mIoU、PSNR等。同时,这也是深度学习处理器领域首次区分整型和浮点对比的Benchmark。福州瑞芯微电子的RK3399开发板展现出抢眼数据。
 采用28nm工艺的福州瑞芯微电子RK3399开发板,在评估中展现出超强性能。评估数据显示,在浮点模型不需要定点化重新训练的情况下,int8计算以精度损失最大为1%的代价,达到相对于浮点计算两倍的性能。
采用28nm工艺的福州瑞芯微电子RK3399开发板,在评估中展现出超强性能。评估数据显示,在浮点模型不需要定点化重新训练的情况下,int8计算以精度损失最大为1%的代价,达到相对于浮点计算两倍的性能。
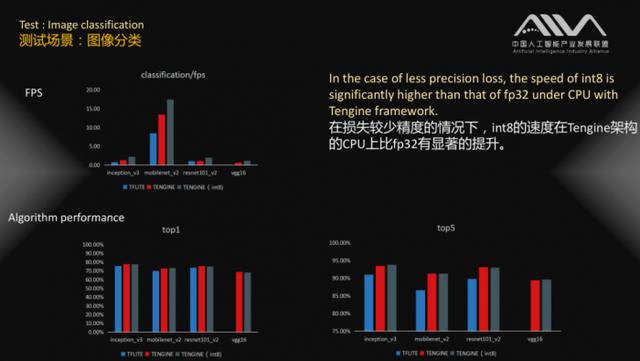 此外,在Interpretation评测中AIIA第一次尝试在基准测试中将量化和浮点模型分开评测。而福州瑞芯微电子RK3399开发板同样取得多项优异数据,在业内处于前列水平。
此外,在Interpretation评测中AIIA第一次尝试在基准测试中将量化和浮点模型分开评测。而福州瑞芯微电子RK3399开发板同样取得多项优异数据,在业内处于前列水平。
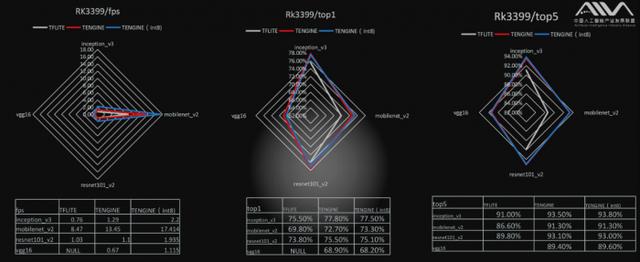 值得一提的是,福州瑞芯微电子RK3399开发板数据抢眼的背后,离不开前沿技术的支持。比如RK3399融入了Tengine,后者是由OPEN AI LAB开发的一款轻量级模块化高性能神经网络推理引擎。Tengine专门针对Arm嵌入式设备优化,且无需依赖第三方库,可跨平台使用支持Android、Liunx等。
Tengine支持各类常见卷积神经网络,包括SqueezeNet,MobileNet,AlexNet,ResNet等,支持层融合、8位量化等优化策略。通过调用针对不同CPU微构架优化的HCL库,能将Arm CPU的性能充分挖掘出来。而RK3399的Cortex-A72单线程运行移动端常用的MobileNet,一次只需要111ms。
在IoT设备、智能交互设备、个人电脑、机器人等人工智能设备的创新与研发上,福州瑞芯微电子已经在技术上展现出领先优势,除了RK3399以外,旗舰级人工智能芯片RK3399Pro同样极具看点,其首次采用CPU GPU NPU的硬件结构设计。这一芯片集成的NPU(神经网络处理器)融合了福州瑞芯微电子在机器视觉、语音处理、深度学习等方面的关键技术,片上NPU运算性能高达3.0TOPs,具备高性能、低功耗、开发易等优势。
值得一提的是,福州瑞芯微电子RK3399开发板数据抢眼的背后,离不开前沿技术的支持。比如RK3399融入了Tengine,后者是由OPEN AI LAB开发的一款轻量级模块化高性能神经网络推理引擎。Tengine专门针对Arm嵌入式设备优化,且无需依赖第三方库,可跨平台使用支持Android、Liunx等。
Tengine支持各类常见卷积神经网络,包括SqueezeNet,MobileNet,AlexNet,ResNet等,支持层融合、8位量化等优化策略。通过调用针对不同CPU微构架优化的HCL库,能将Arm CPU的性能充分挖掘出来。而RK3399的Cortex-A72单线程运行移动端常用的MobileNet,一次只需要111ms。
在IoT设备、智能交互设备、个人电脑、机器人等人工智能设备的创新与研发上,福州瑞芯微电子已经在技术上展现出领先优势,除了RK3399以外,旗舰级人工智能芯片RK3399Pro同样极具看点,其首次采用CPU GPU NPU的硬件结构设计。这一芯片集成的NPU(神经网络处理器)融合了福州瑞芯微电子在机器视觉、语音处理、深度学习等方面的关键技术,片上NPU运算性能高达3.0TOPs,具备高性能、低功耗、开发易等优势。


花粉社群VIP加油站
关于作者

猜你喜欢






































