乾明 边策 一璞 发自 凹非寺
量子位 报道 | 公众号 QbitAI

刚刚,华为业界算力最强的AI芯片正式商用。
并且宣布自研AI框架MindSpore开源,直接对标业界两大主流框架——谷歌的Tensor Flow、Facebook的Pytorch。
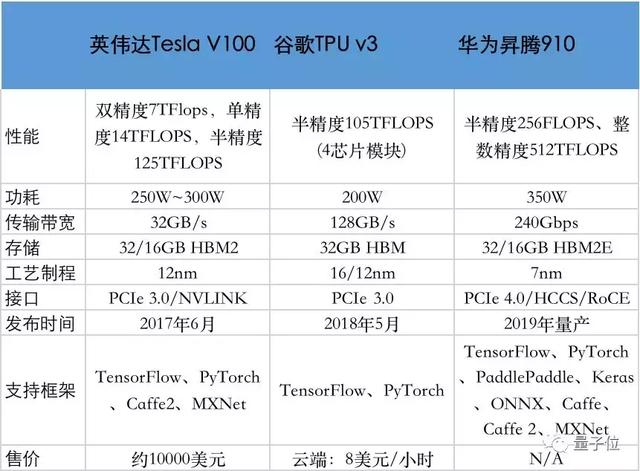
华为AI芯片昇腾910之前已经发布,现在正式商用,对标英伟达Tesla V100,主打深度学习的训练场景,跑分性能2倍于英伟达。
华为轮值董事长徐直军说,这是华为全栈全场景AI战略的实践体现,也希望进一步实现华为新愿景:打造“万物互联的智能世界”。
但毫无疑问,华为入局,自研AI计算架构,肯定会进一步影响AI基础技术和架构格局,特别是美国公司的垄断。
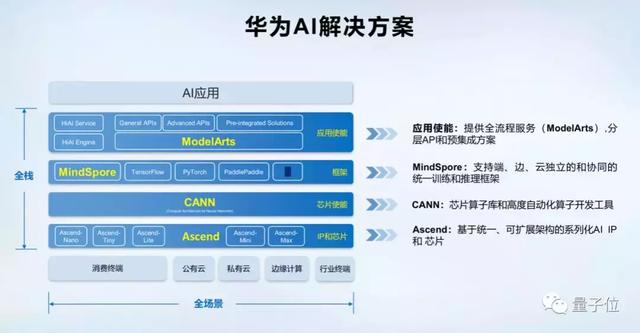
MindSpore发布后,华为已经实现了完整的AI生态链,加上此前发布的ModelArts开发平台、Atlas计算平台,囊括了从芯片、框架、部署平台到应用产品完整层级。
在当下这个大环境中,这些动作也具备了自立自强、不受人掣肘的寓寄。
如今现状,AI领域的关键技术,比如算力、框架、算法等等,主要还是由少数几家美国公司提供。
比如训练芯片,主要由英伟达(GPU)、Google提供(TPU);框架则是Google的Tensor Flow、Facebook的Pytorch等成主导;原创AI算法的发明,也只是在少数几个厂商或者研究机构手中。
这直接导致一些企业想要介入AI的时候,发现门槛很高,除了需要大量数据之外,还需要面临算力稀缺、硬件昂贵、人才难找等问题。
现在,华为要用实际行动改变这一现状。
AI领域的“鸿蒙OS”MindSpore,与其他主流的框架不同,这是一款全场景的AI计算框架,也是一款“操作平台”。
不仅仅可以用于云计算场景,也能够应用到终端、边缘计算场景中。
也不仅仅是一款推理(部署)框架,也可以用来训练模型。
徐直军表示,这背后可以实现统一架构,一次训练,到处部署,可降低部署门槛。

从这个角度来看,MindSpore也可以视为AI领域的“鸿蒙OS”。
此外,这一框架面相的也不仅仅是开发者,也面向领域专家、数学家、算法专家等等在AI中角色越来越重要的人群。
徐直军介绍,MindSpore的界面上也更加友好,在表达AI问题求解的方程式时,更加便利,更易于算法的开放与创新,推动AI应用的普及。
用MindSpore可降低核心代码量20%,开发门槛大大降低,效率整体提升50%以上。
通过MindSpore框架自身的技术创新及其与昇腾处理器协同优化,有效克服AI计算的复杂性和算力的多样性挑战,实现了运行态的高效,大大提高了计算性能。

除了昇腾处理器,MindSpore同时也支持GPU、CPU等其它处理器。
与此同时,MindSpore也采用新AI编程语言,单机程序可分布式运行,是一个全场景框架。全场景是指MindSpore可以在包括公有云、私有云、各种边缘计算、物联网行业终端以及消费类终端等环境上部署。
而且,这一框架将会开源开放,可灵活扩展第三方框架和芯片平台。
当然,徐直军说,如果用华为的昇腾系列芯片,效果会更好,可进行全离线模式执行运算,充分发挥神经网络芯片算力,实现最佳性能搭配。
毕竟,MindSpore作为华为全栈全场景AI解决方案中的核心步骤,是首个Ascend Native开源AI计算框架,会更适合达芬奇架构的AI芯片,尤其是昇腾910。
而且MindSpore针对现在越来越大的训练模型做了更多的优化,用户无需了解并行运算的细节,只需了解单芯片部署,就可以在计算集群上进行并行计算。
徐直军表示,MindSpore会在明年第一季度正式开源。
 昇腾910正式商用
昇腾910正式商用昇腾910,在2018年10月华为全连接大会期间曝光,采用华为自研的达芬奇架构,号称“算力最强的AI处理器”,采用7nm工艺制程,最大功耗为350W,实测310W。
此次发布用于上市商用,直接对标英伟达Tesla V100,主打深度学习的训练场景,主要客户面向AI数据科学家和工程师。
主要性能数据如下:
半精度为(FP 16):256 Tera FLOPS;
整数精度(INT 8):512 Tera FLOPS,128通道 全高清 视频解码器- H.264/265。
在去年全连接大会上,华为就和友商对比了一下,battle的参赛选手包括谷歌TPU v2、谷歌TPU v3、英伟达 V100和华为的昇腾910。
“可以达到256TFLOPS,比英伟达 V100还要高出1倍!”
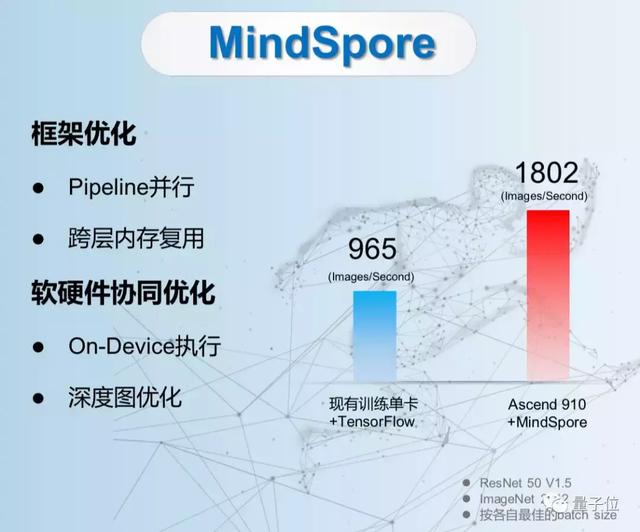
相同的功耗下,昇腾910的算力是V100的两倍,训练速度更快,用户需要得出训练产出的时间会更短。在典型案例下,对比V100,昇腾910的计算速度可以提升50%-100%。
在典型的ResNet50 网络的训练中,昇腾910与MindSpore配合,与现有主流训练单卡配合TensorFlow相比,显示出接近2倍的性能提升。
而且徐直军还在会后明确表示:价格还没定,但肯定不会高!
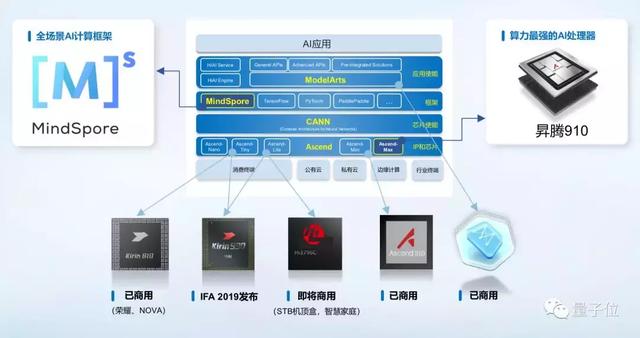
全球格局下的华为AI进展2018年10月,在华为全连接大会上,徐直军公布了华为全栈全场景 AI 战略计划,将数据获取、训练、部署等各个环节囊括在自己的框架之内,主要目的是提升效率,让AI应用开发更加容易和便捷。

全场景包括:消费终端 (Consumer Device)、公有云 (Public Cloud) 、私有云 (Private Cloud)、边缘计算 (Edge Computing)、IoT行业终端 (Industrial IoT Device) 这5大类场景。
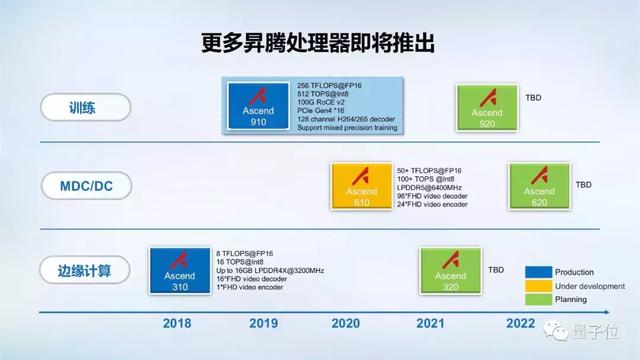
重点在于全栈,包含基于达芬奇架构的昇腾系列芯片(Max、Lite、Mini、Tiny、Nano)、高度自动化的算子开发工具CANN、MindSpore框架和机器学习PaaS (平台即服务) ModelArts。
随着昇腾910正式商用以及MindSpore框架正式推出,华为全栈全场景AI解决方案愈发完善,竞争力也会随之上升。
而且,华为之AI,也不仅仅是关乎华为本身业务,也应该从更加宏观的角度去审视。
当下,AI落地已经成为无可争议的大趋势,大方向。
但中美关系日趋紧张的情况下,中国到底如何,也引发了更多关注。
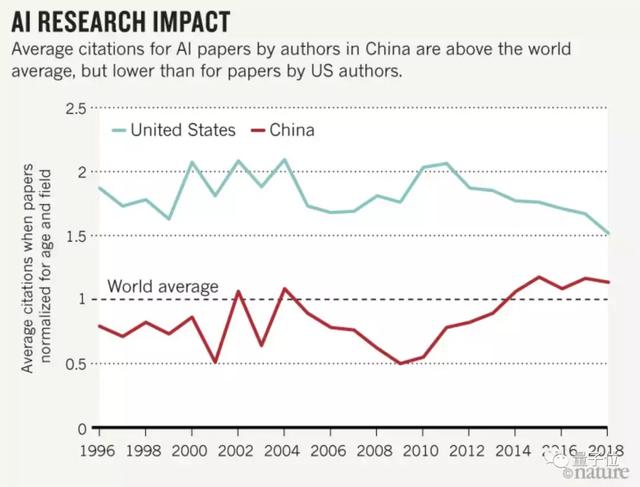
近日,Nature最新发表了一篇,名为“Will China lead the world in AI by 2030?”,提出问题的同时,也审视了中国AI发展的现状。
文章中援引艾伦人工智能研究所数据显示,在最顶级的10%高引用论文中,中国作者占比在2018年已经达到26.5%,非常接近美国的29%。如果这一趋势持续下去,中国将在今年超过美国。
需要场景?数据?金钱?人才?等等,这些都不差。
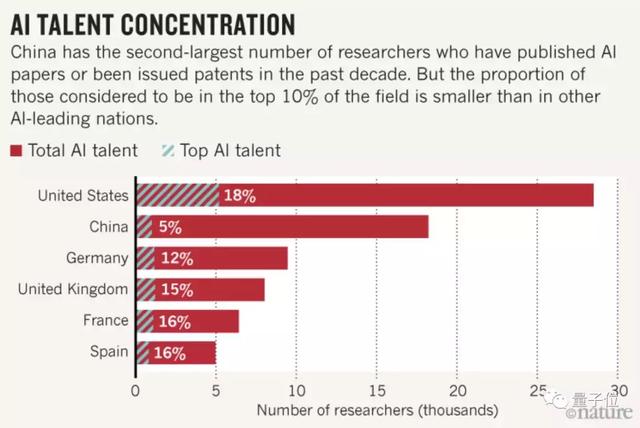
但为什么,卡脖子隐忧,AI领域依然存在。
核心还在于算力(芯片)与基础技术。
Nature文章就指出,中国在人工智能的核心技术工具方面仍然落后。目前全世界的工业和学术界广泛应用的开源AI平台TensorFlow和Caffe,由美国公司和组织开发。
框架方面,百度的PaddlePaddle飞桨也不断突破,虽然发展势头非常好,却还是显得势单力簿。
更关键的是,中国在AI硬件方面的落后非常明显。全球大多数领先的AI半导体芯片都是由美国公司制造的,如英伟达、英特尔、谷歌和AMD等。
中国工程院院士、西安交通大学人工智能与机器人研究所所长郑南宁,接受Nature采访时说:“我们在设计可支持高级AI系统的计算芯片方面也缺乏专业知识。”
虽然国内也有不少公司在努力,比如阿里、百度、依图、地平线等等,都涉足了AI芯片领域,但大部分都聚焦在终端SoC和推理上面,用于训练的大型算力芯片并不多。
郑南宁预计,中国可能需要5到10年才能达到美国和英国基础理论和算法的创新水平,但中国会实现这一目标。
来自柏林智库的政治学者Kristin Shi-Kupfer也表示,基础理论和技术方面的贡献,将是中国实现长期AI目标的关键所在。
她同时强调,如果没有在机器学习上没有真正的突破性进展,那么中国在人工智能领域的增长,将面临发展上限。
所以,Nature的问题:中国AI,到2030年能够领先全球吗?
今天华为给出一种解法,但一切还只是开始。
你怎么看?
— 完 —
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。
量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态

花粉社群VIP加油站
关于作者

猜你喜欢






































