关键词:Bard;Bing;ChatGPT;Claude;A800;A100;H100;LLAMA、LLM、AIGC、CHATGLM、LLVM、LLMs、GLM、NLP、AGI、HPC、GPU、CPU、CPU GPU、英伟达、Nvidia、英特尔、AMD、高性能计算、高性能服务器、蓝海大脑、多元异构算力、高性能计算、大模型训练、通用人工智能、GPU服务器、GPU集群、大模型训练GPU集群、大语言模型、深度学习
摘要:当今人工智能行业蓬勃发展,众多科技公司纷纷推出功能强大的聊天机器人。在众多选择中,哪款产品的实力更强、能够给用户带来最佳体验呢?下面,将对四款主流聊天机器人进行全面评测:Bard、Bing、ChatGPT和Claude。
在评测之后,还将探讨大模型训练中的常见问题。此外还会分享有关ChatGPT训练算力的估算,澄清维基百科上关于“1万块A100 GPU”的误传。中小创企业也有突围的机会。
为何大型模型训练仅能使用特定的硬件,如A100、A800、H100和H800?这些硬件具备哪些高性能和优化的架构,能够支持大规模模型训练所需的计算需求?作为一个新兴平台,蓝海大脑的大模型训练平台将为用户提供哪些具体的大规模模型训练的解决方案?本文将详细阐述。
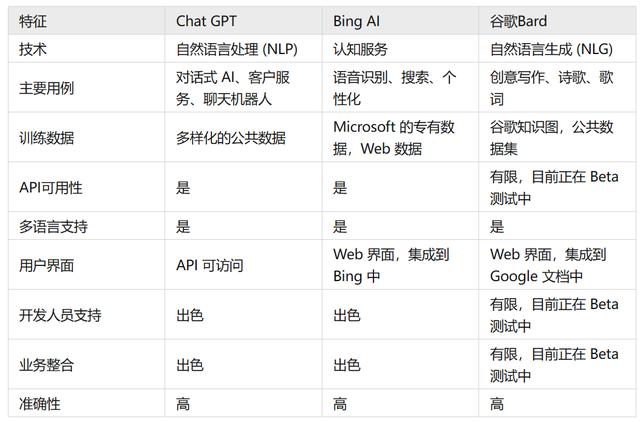
人工智能聊天机器人大比拼:Bard vs. Bing vs. ChatGPT vs. Claude经过全面深入评测,对四款主流聊天机器人产品从用户体验、交互逻辑、语言模型能力和产品定位四个维度进行综合对比。结果显示,Claude在以上四个方面表现出色。其具备超强的语言理解和知识表达能力,为用户提供广泛深入且流畅的体验,是高端用户追求最佳体验的首选产品。同时ChatGPT也展现出优秀的实力,以其个性化表现力著称,能够提供轻松有趣的互动体验,适合中高端用户注重个性化体验的需求。然而,Bing和Bard的能力相对较弱,更适合处理简单的语言交互和信息查询,适用于入门级用户和基本使用。
在数据量方面,预训练阶段需要大量的数据,但对数据质量要求不高;而后面的三个阶段则需要高质量的数据。
训练方法方面,预训练和监督微调使用相同的方法,即预测下一个单词。奖励模型则采用二元分类学习,而强化学习阶段则鼓励模型生成得分较高的回答。
在训练所需资源方面,预训练阶段需要大量的资源,包括数千颗GPU和数月的时间,占据总训练时间的99%。而后面的三个阶段只需要数十颗GPU,并且训练时间约为数天。
通过以上过程可以看到预训练阶段的资源消耗非常巨大,只有大型公司才具备进行的能力。如果资源有限,应该将重点放在其他阶段。
二、没有大数据,就没法训练模型吗?
如果进行预训练模型的训练,确实需要大量的数据。虽然对数据质量的要求不高,但通常还是需要进行数据清洗,以减少垃圾数据的影响。
但是如果只是进行监督微调、建立模型或强化学习阶段的训练,就不需要大量的数据。尤其是在监督微调阶段,数据量范围在10K-100K之间。也就是说,只需要几十个或几百个高质量的数据,就可以对模型进行微调并取得不错的效果。显然,在监督微调阶段,数据质量比数据量更重要。
三、模型的 Token 数量是多少?
在模型训练时,一般会先将文本转换为token,作为模型的输入。相比单词,token通常更短一些。以GPT-3模型为例,一个token相当于0.75个单词,而对于中文而言,一个汉字通常对应两个token。
当前大型语言模型(LLM)的token数量通常在数万级别。例如,GPT-3模型有50257个token,而LLaMA模型则有32000个token。

四、如何设置训练参数,如Batch-Size、Learning rate等?
除训练方法之外,深度学习模型训练的性能还受训练参数设定影响,GPT-3和LLaMA模型在训练过程中使用一些参数,例如批量大小(Batch Size)、学习率(Learning Rate)以及所需的GPU数量等。
可以观察到在预训练阶段,批量大小非常大,范围在0.5M到4M之间。此外,还可以注意到学习率设定较小,并且随着网络规模的增大,学习率逐渐减小。
五、参数量大是模型能力强的唯一指标吗?
参数量并不是衡量模型能力的唯一指标,训练数据量也是一个非常重要的因素。在OpenAI的创始人之一,大神Andrej Karpthy的演讲中,他提到LLaMA模型,尽管只有650亿个参数,但其性能却与拥有1750亿个参数的GPT-3模型相媲美。这主要是因为LLaMA模型使用1.4万亿的训练数据,而GPT-3只有3000亿。
六、GPU资源有限时有什么机会?
如果GPU资源有限,那么在专业领域可能有更多机会。训练通用模型(如ChatGPT)需要大量的训练数据和GPU资源,并且需要对许多常见任务进行优化和评估。这不仅训练成本高,还需要大量人力资源来准备和整理数据。
在资源有限的情况下,可以将重点放在后三个阶段,如可以对模型进行微调,针对自己熟悉的专业领域进行优化。利用公开的预训练模型,根据专业领域的需求或客户的需求来训练特定任务的模型。
七、四个训练阶段的模型中哪些适合部署?
除了最终模型,预训练模型和监督微调模型也可以不被直接用于实际应用。
以下是三种模型的特点:
- 预训练模型:预训练模型通常不会直接回答问题。当向它提问时,可能会以更多的问题作为回应。虽然可以通过一些技巧使其回答问题,但回答通常不够可靠。然而,这种基础模型具有更高的熵,能够生成许多不同的输出,因此更适合产生多样化的内容。
- 监督微调模型:监督微调模型可以很好地回答问题,目前公开的大多数模型都属于这一类。
- 强化学习与人工反馈(RLHF)模型:目前最优秀的模型。与监督微调模型相比,RLHF模型的输出结果变化较小。
八、RLHF模型为什么优秀?
根据UC Berkeley发布的AI助手的ELO排名,前三名模型属于强化学习与人工反馈(RLHF)模型,其他模型主要是监督微调(SFT)模型。目前对于为什么RLHF模型优秀并没有定论。
在人工标注数据时,对几个答案做出选择要比写出几个备选答案简单的多。因此,由判断标签构成的数据库质量更高,使得训练出的奖励模型非常有效。在强化学习训练中,优化判别结果更为容易。

四、其他考量与建议
1、除了之前提到的并行训练方法降低GPU数量要求之外,还有其他优化技巧可以进一步减少所需的GPU数量。然而,以上估算并未考虑这些优化技巧的累积效果。
2、实际的算力需求与测算规模之间的关系通常呈非线性。一般情况下,随着模型规模的增加,算力利用率会降低。本次测算按照从高到低的顺序进行,以全面评估小规模情况下的成本。
3、对于创业企业而言,建议考虑使用规模为6B的模型,只需22台配备8块GPU的服务器。硬件购置成本大致相当于1-2年的云服务训练成本。如果未来采用存算一体技术的训练卡,可能只需要1-4台服务器就足够。此外,根据OpenAI的论文,ChatGPT和InstructGPT-1.3B的效果都优于规模为175B的GPT-3。因此,未来私有化ChatGPT的算力也是可行。

一、为什么需要大模型?
1、模型效果更优
大模型在各场景上的效果均优于普通模型
2、创造能力更强
大模型能够进行内容生成(AIGC),助力内容规模化生产
3、灵活定制场景
通过举例子的方式,定制大模型海量的应用场景
4、标注数据更少
通过学习少量行业数据,大模型就能够应对特定业务场景的需求
二、平台特点
1、异构计算资源调度
一种基于通用服务器和专用硬件的综合解决方案,用于调度和管理多种异构计算资源,包括CPU、GPU等。通过强大的虚拟化管理功能,能够轻松部署底层计算资源,并高效运行各种模型。同时充分发挥不同异构资源的硬件加速能力,以加快模型的运行速度和生成速度。
2、稳定可靠的数据存储
支持多存储类型协议,包括块、文件和对象存储服务。将存储资源池化实现模型和生成数据的自由流通,提高数据的利用率。同时采用多副本、多级故障域和故障自恢复等数据保护机制,确保模型和数据的安全稳定运行。
3、高性能分布式网络
提供算力资源的网络和存储,并通过分布式网络机制进行转发,透传物理网络性能,显著提高模型算力的效率和性能。
4、全方位安全保障
在模型托管方面,采用严格的权限管理机制,确保模型仓库的安全性。在数据存储方面,提供私有化部署和数据磁盘加密等措施,保证数据的安全可控性。同时,在模型分发和运行过程中,提供全面的账号认证和日志审计功能,全方位保障模型和数据的安全性。
三、常用配置
目前大模型训练多常用H100、H800、A800、A100等GPU显卡,以下是一些常用的配置。
1、H100工作站常用配置
英伟达H100 配备第四代 Tensor Core 和 Transformer 引擎(FP8 精度),与上一代产品相比,可为多专家 (MoE) 模型提供高 9 倍的训练速度。通过结合可提供 900 GB/s GPU 间互连的第四代 NVlink、可跨节点加速每个 GPU 通信的 NVLINK Switch 系统、PCIe 5.0 以及 NVIDIA Magnum IO™ 软件,为小型企业到大规模统一 GPU 集群提供高效的可扩展性。
搭载 H100 的加速服务器可以提供相应的计算能力,并利用 NVLink 和 NVSwitch 每个 GPU 3 TB/s 的显存带宽和可扩展性,凭借高性能应对数据分析以及通过扩展支持庞大的数据集。通过结合使用 NVIDIA Quantum-2 InfiniBand、Magnum IO 软件、GPU 加速的 Spark 3.0 和 NVIDIA RAPIDS™,NVIDIA 数据中心平台能够以出色的性能和效率加速这些大型工作负载。
CPU:英特尔至强Platinum 8468 48C 96T 3.80GHz 105MB 350W *2
内存:动态随机存取存储器64GB DDR5 4800兆赫 *24
存储:固态硬盘3.2TB U.2 PCIe第4代 *4
GPU :Nvidia Vulcan PCIe H100 80GB *8
平台 :HD210 *1
散热 :CPU GPU液冷一体散热系统 *1
网络 :英伟达IB 400Gb/s单端口适配器 *8
电源:2000W(2 2)冗余高效电源 *1
2、A800工作站常用配置
NVIDIA A800 的深度学习运算能力可达 312 teraFLOPS(TFLOPS)。其深度学习训练的Tensor 每秒浮点运算次数(FLOPS)和推理的 Tensor 每秒万亿次运算次数(TOPS)皆为NVIDIA Volta GPU 的 20 倍。采用的 NVIDIA NVLink可提供两倍于上一代的吞吐量。与 NVIDIA NVSwitch 结合使用时,此技术可将多达 16 个 A800 GPU 互联,并将速度提升至 600GB/s,从而在单个服务器上实现出色的应用性能。NVLink 技术可应用在 A800 中:SXM GPU 通过 HGX A100 服务器主板连接,PCIe GPU 通过 NVLink 桥接器可桥接多达 2 个 GPU。
CPU:Intel 8358P 2.6G 11.2UFI 48M 32C 240W *2
内存:DDR4 3200 64G *32
数据盘:960G 2.5 SATA 6Gb R SSD *2
硬盘:3.84T 2.5-E4x4R SSD *2
网络:双口10G光纤网卡(含模块)*1
双口25G SFP28无模块光纤网卡(MCX512A-ADAT )*1
GPU:HV HGX A800 8-GPU 8OGB *1
电源:3500W电源模块*4
其他:25G SFP28多模光模块 *2
单端口200G HDR HCA卡(型号:MCX653105A-HDAT) *4
2GB SAS 12Gb 8口 RAID卡 *1
16A电源线缆国标1.8m *4
托轨 *1
主板预留PCIE4.0x16接口 *4
支持2个M.2 *1
原厂质保3年 *1
3、A100工作站常用配置
NVIDIA A100 Tensor Core GPU 可针对 AI、数据分析和 HPC 应用场景,在不同规模下实现出色的加速,有效助力更高性能的弹性数据中心。A100 采用 NVIDIA Ampere 架构,是 NVIDIA 数据中心平台的引擎。A100 的性能比上一代产品提升高达 20 倍,并可划分为七个 GPU 实例,以根据变化的需求进行动态调整。A100 提供 40GB 和 80GB 显存两种版本,A100 80GB 将 GPU 显存增加了一倍,并提供超快速的显存带宽(每秒超过 2 万亿字节 [TB/s]),可处理超大型模型和数据集。
CPU:Intel Xeon Platinum 8358P_2.60 GHz_32C 64T_230W *2
RAM:64GB DDR4 RDIMM服务器内存 *16
SSD1:480GB 2.5英寸SATA固态硬盘 *1
SSD2:3.84TB 2.5英寸NVMe固态硬盘 *2
GPU:NVIDIA TESLA A100 80G SXM *8
网卡1:100G 双口网卡IB 迈络思 *2
网卡2:25G CX5双口网卡 *1
4、H800工作站常用配置
H800是英伟达新代次处理器,基于Hopper架构,对跑深度推荐系统、大型AI语言模型、基因组学、复杂数字孪生等任务的效率提升非常明显。与A800相比,H800的性能提升了3倍,在显存带宽上也有明显的提高,达到3 TB/s。
虽然论性能,H800并不是最强的,但由于美国的限制,性能更强的H100无法供应给中国市场。有业内人士表示,H800相较H100,主要是在传输速率上有所差异,与上一代的A100相比,H800在传输速率上仍略低一些,但是在算力方面,H800是A100的三倍。
CPU:Intel Xeon Platinum 8468 Processor,48C64T,105M Cache 2.1GHz,350W *2
内存 :64GB 3200MHz RECC DDR4 DIMM *32
系统硬盘: intel D7-P5620 3.2T NVMe PCle4.0x4 3DTLCU.2 15mm 3DWPD *4
GPU: NVIDIA Tesla H800 -80GB HBM2 *8
GPU网络: NVIDIA 900-9x766-003-SQO PCle 1-Port IB 400 OSFP Gen5 *8
存储网络 :双端口 200GbE IB *1
网卡 :25G网络接口卡 双端口 *1

花粉社群VIP加油站
关于作者
猜你喜欢





































