
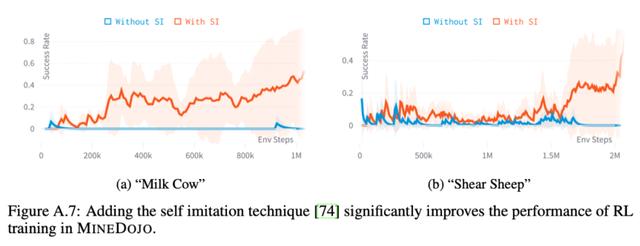
由于RL收敛比较慢,作者也采用了不少方法加速训练,其中很重要的一点是Self-Imitation Learning,直接把拿到高奖励的动作序列保存下来去学习,就像SFT一样去学习,效果提升很明显(红色线):
得到视频预训练模型之后,对于特定的任务,可以直接利用人工标注数据进行精调,同时可以再进行RL,作者发现Pretrain SFT RL三步之后效果奇佳,模型可以完成非常复杂的任务(人类需要20分钟才能完成)。
同时,VPT也尝试了加入字幕、音频转文字后的数据进行多模态训练,但由于数据太少,只展现了微弱的可控性,不过当下再来看文本可控并不是难点,已经有很多成功的工作了。
看完VPT,再来对比一下MineDojo,可以发现LLM范式一个明显的优点,即提升了训练效率和效果天花板,因为纯RL要靠自己探索,其实收敛的很慢,而且有些复杂的任务需要很长的链路,纯RL可能根本探索不到。
通用视频预训练?
虽然VPT证明了LLM的范式在视频预训练同样可行,但个人认为还有两个比较关键的问题:
图像与文本的预训练数据不兼容:目前互联网的语料都是图像或者文字一方占主导,所以后续大概率是和现在一样,两种模态分别预训练,再通过少量数据融合。
VPT的方法不够通用:像NLP一样进行通用领域的视频预训练还有很长的路要走。首先VPT在准备训练语料时,需要定义标签的动作空间,目前只局限在鼠标和键盘,但真实世界中的动作太多了;另外很多领域的监督数据也不一定好获取,比如需要真人出镜的视频成本会很高。
VPT这篇工作在去年推出时并没有引起太大火花,如今想一想,虽然存在上述问题,但在一些垂类场景上已经有落地的可能了,比如在excel上做数据分析、做PPT、操作photoshop等。
再一想,OpenAI居然前年就开始做这些事儿了,真可怕。
参考资料[1]Video-Pre-Training: https://cdn.openai.com/vpt/Paper.pdf
[2]MineDojo: https://minedojo.org/


花粉社群VIP加油站
关于作者

猜你喜欢





































