机器之心报道
编辑:小舟
Google Deepmind 可能早就意识到了这个问题。
今年,大型语言模型(LLM)成为 AI 领域最受关注的焦点,OpenAI 的 ChatGPT 和 GPT-4 更是爆火出圈。GPT-4 在自然语言理解与生成、逻辑推理、代码生成等方面性能出色,令人惊艳。
然而,人们逐渐发现 GPT-4 的生成结果具有较大的不确定性。对于用户输入的问题,GPT-4 给出的回答往往是随机的。
我们知道,大模型中有一个 temperature 参数,用于控制生成结果的多样性和随机性。temperature 设置为 0 意味着贪婪采样(greedy sampling),模型的生成结果应该是确定的,而 GPT-4 即使在 temperature=0.0 时,生成的结果依然是随机的。
在一场圆桌开发者会议上,有人曾直接向 OpenAI 的技术人员询问过这个问题,得到的回答是这样的:「老实说,我们也很困惑。我们认为系统中可能存在一些错误,或者优化的浮点计算中存在一些不确定性......」
值得注意的是,早在 2021 年就有网友针对 OpenAI Codex 提出过这个疑问。这意味着这种随机性可能有更深层次的原因。
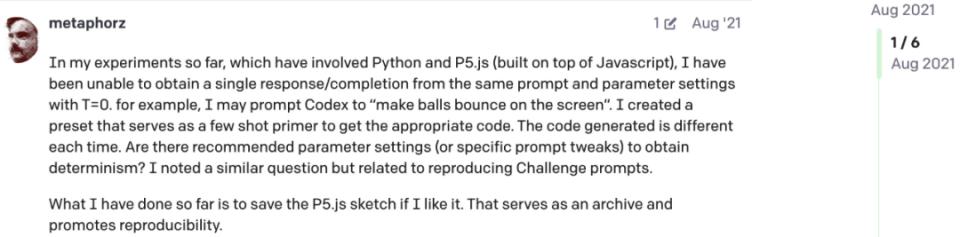
图源:https://community.openai.com/t/a-question-on-determinism/8185
现在,一位名为 Sherman Chann 的开发者在个人博客中详细分析了这个问题,并表示:「GPT-4 生成结果的不确定性是由稀疏 MoE 引起的」。
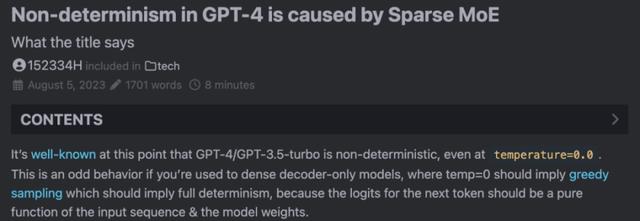
Sherman Chann 博客地址:https://152334h.github.io/blog/non-determinism-in-gpt-4/
Sherman Chann 这篇博客受到了 Google DeepMind 最近一篇关于 Soft MoE 的论文《From Sparse to Soft Mixtures of Experts》启发。

还有开发者分析道:「按照 Soft MoE 论文的说法,稀疏 MoE 不仅引入了不确定性,还可能会使模型的响应质量取决于有多少并发请求正在争夺专家模块的分配」。

对此,你怎么看?
参考链接:
https://news.ycombinator.com/item?id=37006224

花粉社群VIP加油站
关于作者

猜你喜欢





































