GPT-4的热度还未消退,GPT-5的相关消息已是层出不穷。
7月31日,美国商标律师Josh Gerben称OpenAI 已于7月18日向美国专利商标局(USPTO)提交了「GPT-5」名称商标申请。
商标申请信息显示,GPT-5能够提供离线/在线版本的“人工生成语音和文本的计算机软件”,以及离线/在线版本的“自然语言处理、生成、理解和分析的计算机软件”。
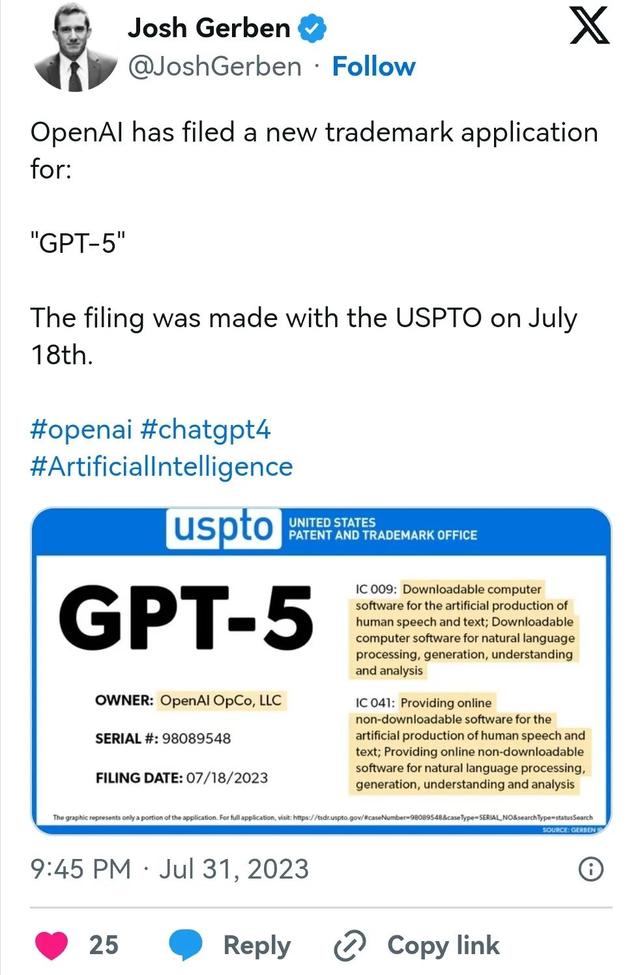
在美国专利商标局的网站上,也可以查询到OpenAI提交的商标申请。
在这份新商标申请中,OpenAI将“GPT-5”描述为一种“用于使用语言模型的可下载计算机软件”,这和之前发布GPT-4和GPT-3的描述一致。
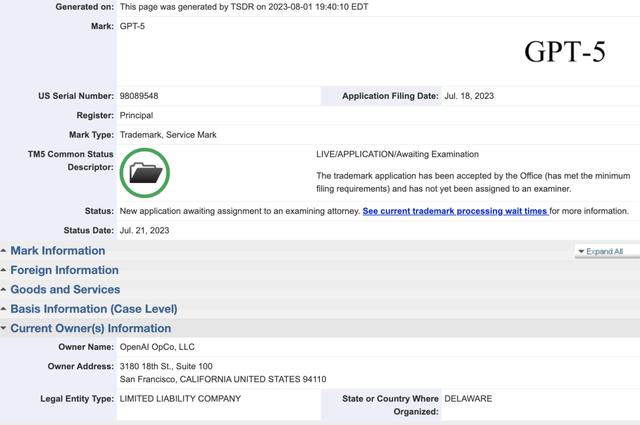
目前,GPT-5的商标注册已被主管局接受,但尚未分配给审查员。
不过,OpenAI对GPT-5也是十分低调,并没有主动透露过太多信息。
OpenAI CEO Sam Altman在6月的北京智源大会上也说明过,目前还没有发布GPT-5的打算,也透露尚未开始训练GPT-5。
外界预估OpenAI申商标的主要目的是防止有商标蟑螂抢先申请,但考虑到OpenAI一贯的做事风格,不排除 GPT-5 已开始训练。
01
GPT-5或为GPT-4的改进版本

从美国专利商标局官网查询到的信息来看,OpenAI在商标申请中概述了GPT-5的用途和功能,主要包括以下内容:
- 语言模型应用:人工生成人类语音和文本的软件。
- 语音识别和生成:可以识别音频,将音频数据文件转换为文本,同时也支持语音生成功能。
- 基于机器学习的语言和语音处理:GPT-5提供了基于机器学习的语言和语音处理软件,使用户能够利用数据训练算法,分析、分类并对数据采取相应措施。
- 多语言翻译:GPT-5拥有文本和语音翻译功能,使得用户可以方便地进行跨语言的交流和理解。
- 数据共享:该系统支持共享数据集,可以用于机器学习、预测分析和构建语言模型,为研究人员和开发者提供了重要资源。
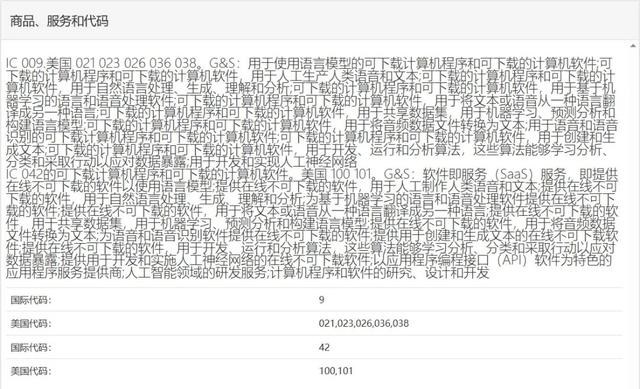
此外,OpenAI还打算提供软件即服务(SaaS)功能,开发和实现人工神经网络,并提供API软件,使其他开发者可以更轻松地集成GPT-5的功能和算法到自己的应用程序中。
不过,从整体来看,这份最新的申请文件中,除了“GPT-5”这个名字是唯一有趣的细节,其余的内容与之前GPT-4相差不大,可以说是毫无新意。
因此,有人推测,GPT-5应该是GPT-4的改进版本,会在性能上有所提升,但是否是跨时代的飞跃性产品,还很难说。
但以GPT-4的提升速度为参考,相比最初使用的GPT-3.5模型,GPT-4确实有了极大的跃升。
在能力上,GPT-4拥有了多模态识别能力,此外,GPT-4的文字输入限制提升至2.5万字,回答准确性也大大提高,还能进行歌词、文学创作,实现风格变化。
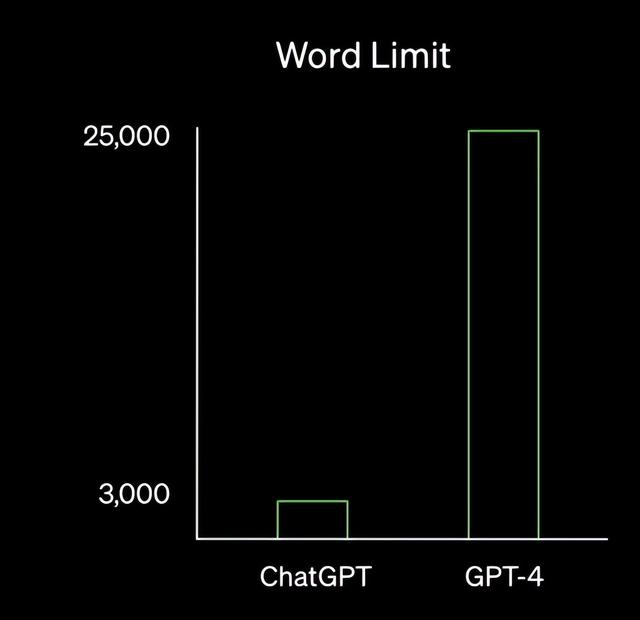
GPT-3.5和GPT-4的文本输入限制对比
而且,根据知名黑客乔治・霍兹(George Hotz)揭秘,GPT-4的信息GPT-4是一个混合模型,其整体参数高达100万亿,而上一代的GPT-3.5只拥有1750亿参数规模,参数规模扩大了近6倍。
照此推断,GPT-5的整体参数规模至少也是在万亿以上,有望成为世界最大规模的AI工具。
但从目前的商标注册信息来看,GPT-5并没有特别亮眼的功能,也未透露更具体的参数信息,看起来显得有点平平无奇。
02
GPT-5可能有哪些提升?
自GPT-4展现了AI大模型的无边法力之后,AI成为了魔法般的存在,被寄予无限的期待。
GPT-5虽然至今还未问世,但此起彼伏的争议确实令人们对它又不安,又期待。甚至有人认为它能达到人工通用智能(AGI)的水平,成为生成式AI的终极形态。
技术的发展离不开人们的想象,在GPT-4发布应用半年后,人们对GPT-5的想象似乎更具体了一些,从中或许能够窥见GPT-5的些许轮廓。
在诸多的报道和研发者关于GPT-5的看法上,多模态能力是经常谈及的部分,也是生成式AI提升的重要方向。
目前 GPT-4只能处理文本和图像两种类型的数据,人们希望GPT-5能够在语音、视频等其他模态上有所突破。
就在不久前,Meta发布了ImageBind,这是第一个将六种类型的数据结合到一个单一的嵌入空间的模型。
该模型包括的六种数据是:视觉(图像和视频形式)、热力(红外图像)、文本、音频、深度信息和运动读数。
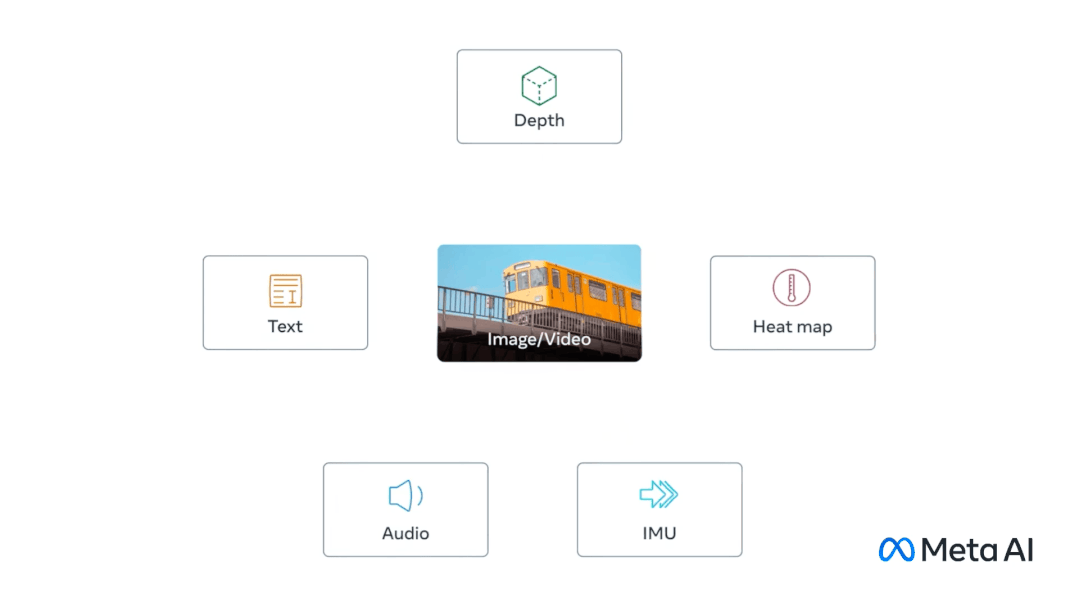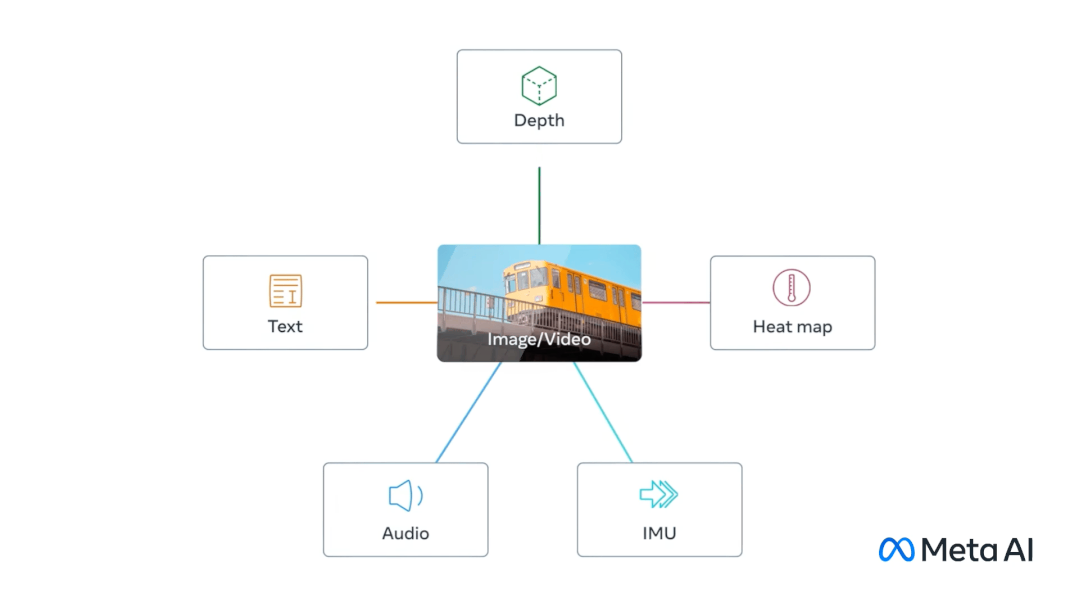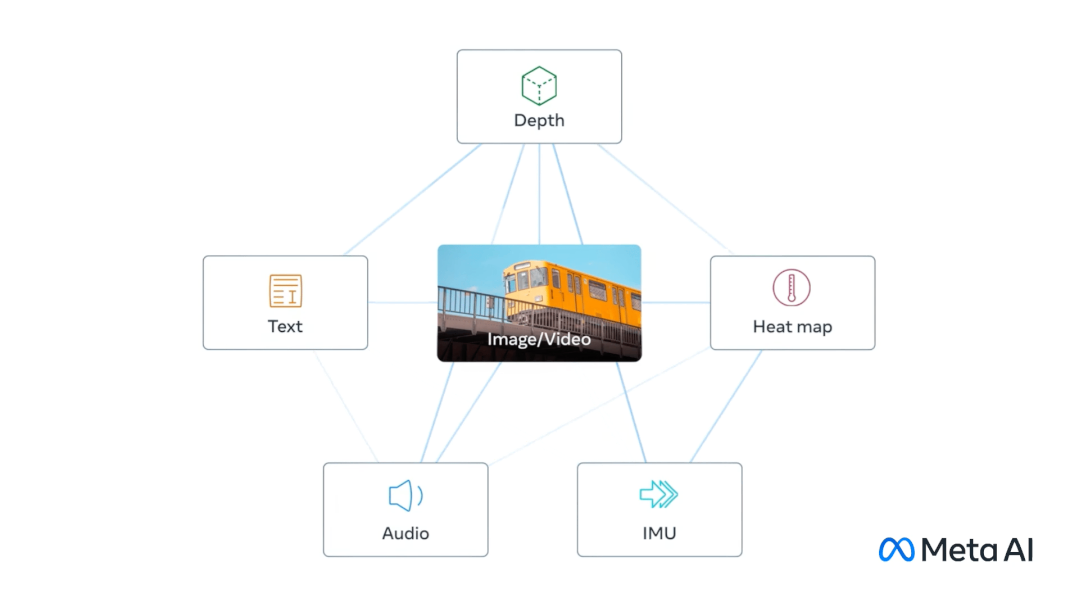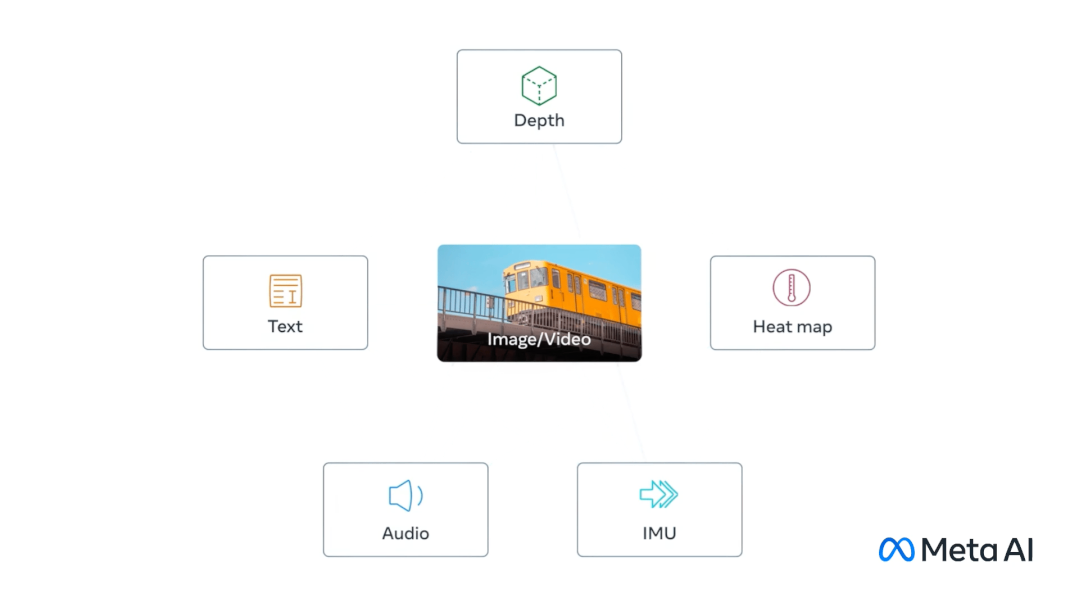
这令AI实现了感官的大一统,AI具备了与人一样的感知能力,其意义在于AI输出的将不再是简单的信息,而是虚拟的“现实”。
其次,减少幻觉是GPT-5被寄予厚望的一方面。
不少人在和ChatGPT、Bing AI Chat或Google Bard聊天时发现,AI有时会进入暴走模式,开始胡言乱语。
先前,谷歌的AI聊天机器人Bard就因为“口无遮拦”,导致其母公司Alphabet股价暴跌 8%,市值缩水1000多亿美元。
在行业领域内部,这一现象有着一个专业术语——“幻觉”。
AI幻觉指的是AI的一种自信反应。当模型有“幻觉”(输出欺骗性数据的倾向)时,其使用的训练数据并不能证明输出的合理性。其危险之处在于,模型的输出看起来是正确的,而本质上是错误的。
长此以往,这种微妙的错误信息可能会导致诸多的社会问题,比如改变对是非的看法。
为此,各大AI公司都将“治愈AI幻觉”摆在人工智能发展的重要位置。
先前,英伟达就推出了“护栏技术”(NeMo Guardrails),其作用相当于是给大模型加上一堵安全围墙,既能控制它的输出、又能过滤输入它的内容。
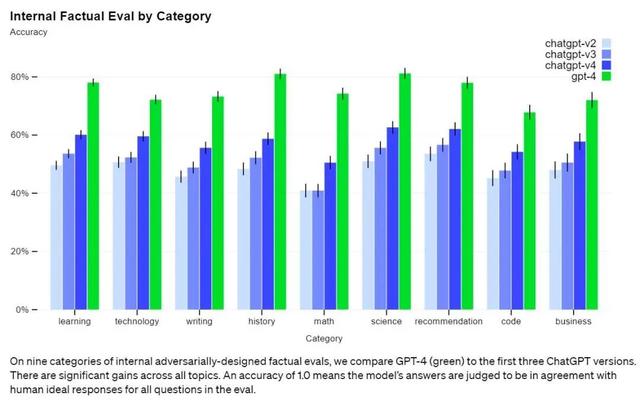
目前,在OpenAI的内部对抗性真实性评估中,GPT-4的得分比最新的 GPT-3.5 模型高 40%,在各个类别的准确度测试中,它非常接近 80% 的分数。相信GPT-5还会在对抗幻觉上,取得更大的优势。
此外,在计算效率上,计算成本一直是制约大模型迭代的重要因素。
在计算效率与成本上,GPT-4的定价是每1,000个prompt token0.03美元,默认速率限制为每分钟40,000个token和每分钟200个请求。
而GPT-3.5-turbo的定价是每1,000个token 0.002美元,只有GPT-4的1/15。
由此看来,GPT-4的维护成本将会比GPT-3.5高出许多,运行和维护GPT-4模型的成本就变得非常昂贵。
但同行谷歌表示,模型越大并不总是越好,研究创造力是制作伟大模型的关键。其推出的PaLM2仅接受了3400亿个参数的训练。
GPT-5如果继续扩大参数规模,其成本必将水涨船高,后期的维护会成为非常大的问题。
并且,用户和企业不一定能够承担相应的费用。OpenAI是选择继续做“大”模型,还是转换策略,优化计算性能,这都将在GPT-5发布时见证。
作者:西瓜 排版:黄蕾卉
图片源于Q仔互联网冲浪所得,若有侵权,后台联系,Q仔滑跪删除~

花粉社群VIP加油站
关于作者

猜你喜欢





































