AI浪潮已经席卷国内外,在国内,许多厂商或互联网大厂更是争相布局大模型。那么时间到了现在,国内大模型的产品能力是否有所突破?在这篇文章里,作者就对中文大模型的发展进行了解读,一起来看看吧。

从另一个角度说,C-Eval是一个对大模型从人文到社科到理工多个大类的综合知识能力进行测评的竞赛。通常,高阶难度测试是考验大模型性能的关键动作,面对复杂且有挑战性的任务,大多大模型性能会大幅下降。在C-Eval公布的评比结果中,APUS的AiLMe-100Bv1除了在平均分上进入四强,还在难题处理方面超越GPT-4*,排名第一。
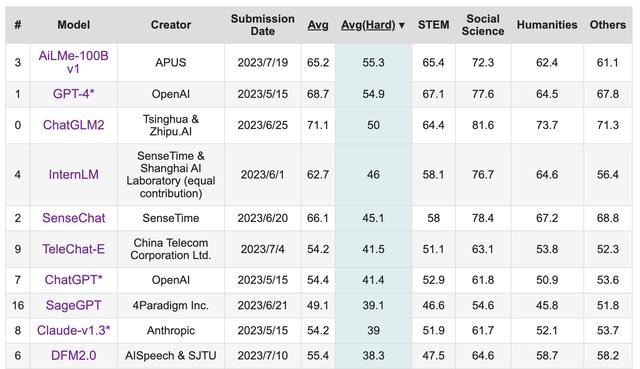
据悉,C-Eval Hard(难题)类别是首个提供中文复杂推理能力的测试,“即便是GPT-4来做这个题也会很吃力,”张旭提及,“这是‘闭卷考试’,而以往如AGIEval和MMLU是‘开卷考试’,也就是说,AGIEval和MMLU是各公司自己测试、自己打分、自己公布成绩,而C-Eval Hard的评比显然更加客观、可信。”
的确,C-Eval测评难度比其他测评更高且更严格。在打分流程上,C-Eval更像是学校中为学生准备的大考模式,各个公司参加统一考试并由系统自动打分、C-Eval团队人工审核成绩并公布,所以,就结果上看,其测评所公布的成绩真实性更高。
三、国内大模型的未来放眼行业,大模型对于国内人工智能产业的意义非凡。
在NLP行业出现范式变革后,Transformer为主导的新一代通用大模型产品大行其道,让人们看到了AGI的曙光。甚至可以说,中国版的ChatGPT3.5/4.0的问世是我国正式迈向人工智能时代的重要标志。
在过去,一、二级资本市场对国内大模型产业意见颇多。讨论最多的是,国内公司没有在前沿技术投入太多,反而将精力侧重于“蹭”数字人、AIGC等概念之上。
客观地说,上述评价不无道理,其中不乏因大环境不好,企业对前沿投入审慎和相关技术积累薄弱等问题所导致。
但近期,随着对大模型行业认识的深入,以上问题正在得到改变:首先,以智源研究院、百度文心一言、商汤和APUS等企业的持续投入,我国已有多家企业具备大模型制作和运营能力(此前大多为小模型);其次,随着上半年密集的模型发布大会逐渐落幕,新模型开始迭代积累,并向着ChatGPT能力靠拢。
在我们所知的大模型产业上下游企业中,针对数据处理、清洗、标注、模型训练、推理加速等方面的技术也正在加速追赶之中;最后,政策层面已注意到发展大模型和ChatGPT的必要性,开始着手调集更多资源应对,相关生态和创新土壤也正在完备的过程中。
可以肯定的是,本次人工智能革命的核心就是通用大模型。目前,我国众多企业正在加速追赶。
现在,超越ChatGPT已成为国内AI从业者们心中的图腾。想必若假以时日,这个目标将有机会实现。而到那时,一个属于人工智能时代的大幕才彻底拉开。
作者:苑晶,编辑:大兔;公众号:数科星球(ID:digital-planet)
本文由 @数科星球 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。

花粉社群VIP加油站
关于作者

猜你喜欢





































