机器之心报道
编辑:小舟、陈萍
谷歌、UC 伯克利等证明 MoE 指令调优起到了 1 1 > 2 的效果。
自 GPT-4 问世以来,人们一直惊艳于它强大的涌现能力,包括出色的语言理解能力、生成能力、逻辑推理能力等等。这些能力让 GPT-4 成为机器学习领域最前沿的模型之一。然而,OpenAI 至今未公开 GPT-4 的任何技术细节。
上个月,「天才黑客」乔治・霍兹(George Hotz)在接受一家名为 Latent Space 的 AI 技术播客的采访时提到了 GPT-4,并称 GPT-4 其实是一个混合模型。具体来说,乔治・霍兹称 GPT-4 采用由 8 个专家模型组成的集成系统,每个专家模型都有 2200 亿个参数(比 GPT-3 的 1750 亿参数量略多一些),并且这些模型经过了针对不同数据和任务分布的训练。
看来 GPT-4 采用混合模型还是有点根据的,MoE 确实能够从指令调优中获得更大的收益:
方法概述
研究者在 FLAN-MOE (是一组经过指令微调的稀疏混合专家模型)模型中使用了稀疏激活 MoE(Mixture-of-Experts)。此外,他们还用 MoE 层替换了其他 Transformer 层的前馈组件。
每个 MoE 层可理解为一个「专家」,然后,使用 softmax 激活函数对这些专家进行建模,得到一个概率分布。
尽管每个 MoE 层有很多参数,但专家是稀疏激活的。这意味着对于给定的输入 token,只使用有限的专家子集就能完成任务,从而为模型提供了更大的容量。
对于具有 E 个专家的 MoE 层,这实际上提供了 O (E^2) 种不同的前馈网络组合,从而实现了更大的计算灵活性。
由于 FLAN-MoE 是经过指令调优的模型,因而指令调优非常重要,该研究在 FLAN 集合数据集的基础上对 FLAN-MOE 进行微调。此外,该研究将每个 FLAN-MOE 的输入序列长度调整为 2048,输出长度调整为 512。
实验与分析
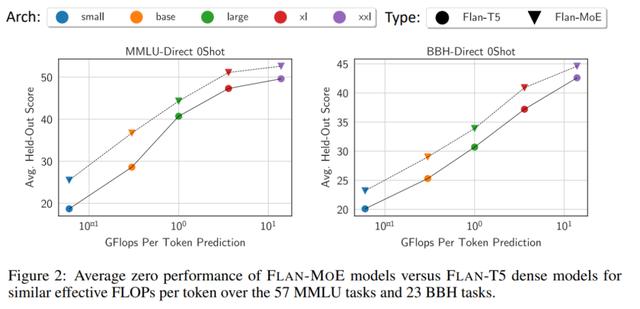
平均而言,在不增加任何额外计算的情况下,Flan-MoE 在所有模型尺度上都优于密集的同类产品 (Flan-T5)。
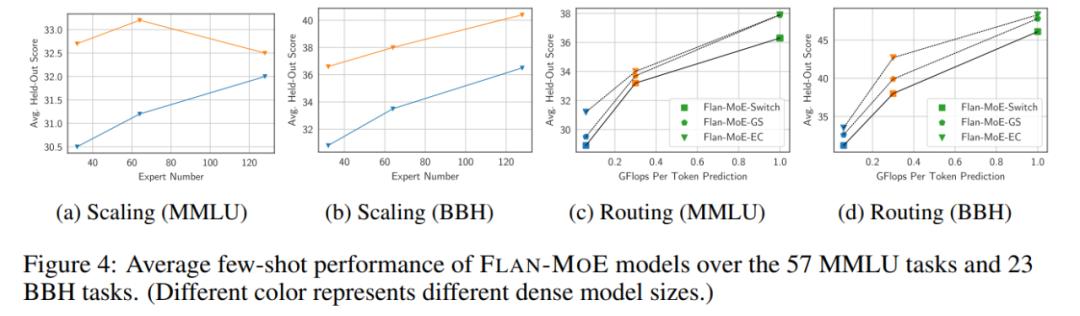
专家数量。图 4 显示,随着专家数量的增加,初始时,模型受益于更丰富的专门子网络,每个子网络能够处理问题空间中的不同任务或方面。这种方式使得 MoE 在处理复杂任务时具有很强的适应性和效率,从而整体上改善性能。然而,随着专家数量的不断增加,模型性能增益开始减少,最终达到饱和点。
当进行模型扩展时,Flan-MoE (Flan-ST-32B) 优于 Flan-PaLM-62B 。
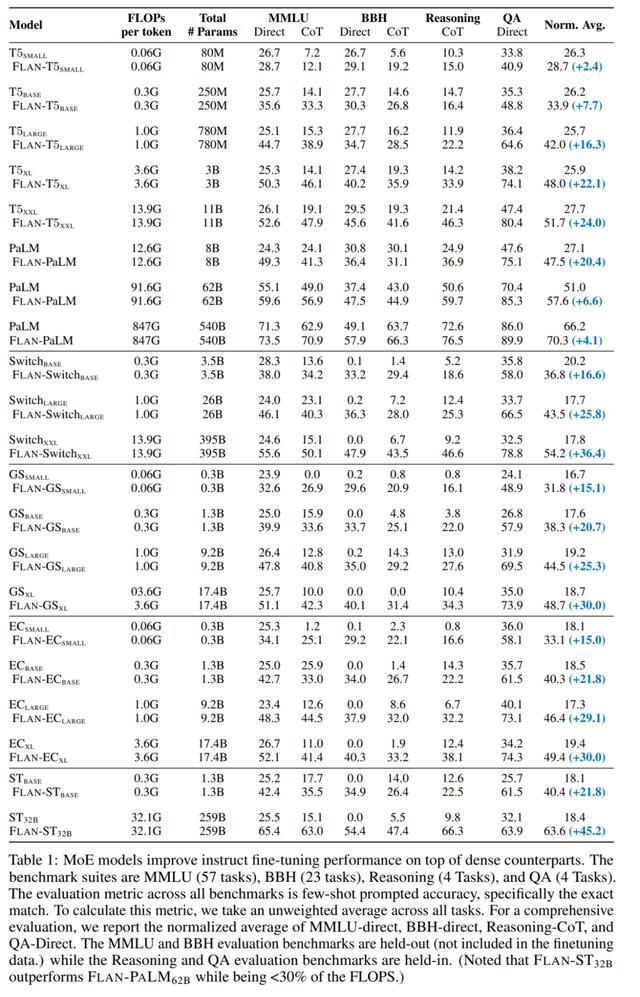
此外,该研究通过 freeze 给定模型的门控函数(gating function)、专家模块和 MoE 参数进行了一些分析实验。如下表 2 所示,实验结果表明,freeze 专家模块或 MoE 组件对模型性能有负面影响。
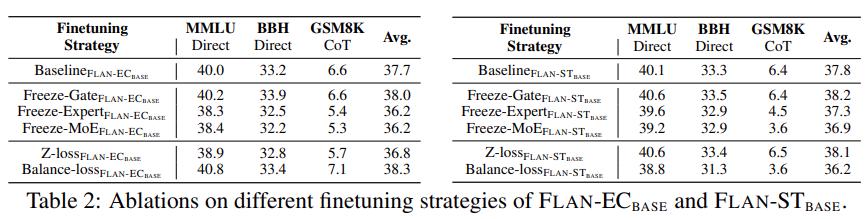
最后,为了比较直接对 MoE 进行微调和 FLAN-MOE 之间的差距,该研究对单任务微调的 MoE、单任务微调的 FLAN-MoE 和密集模型进行了实验,结果如下图 6 所示:
感兴趣的读者可以阅读论文原文,了解更多研究内容。

花粉社群VIP加油站
关于作者

猜你喜欢





































