
作者 | 黄楠
编辑 | 陈彩娴
9月21日,OpenAI 发布了一个名为「Whisper 」的神经网络,声称其在英语语音识别方面已接近人类水平的鲁棒性和准确性。
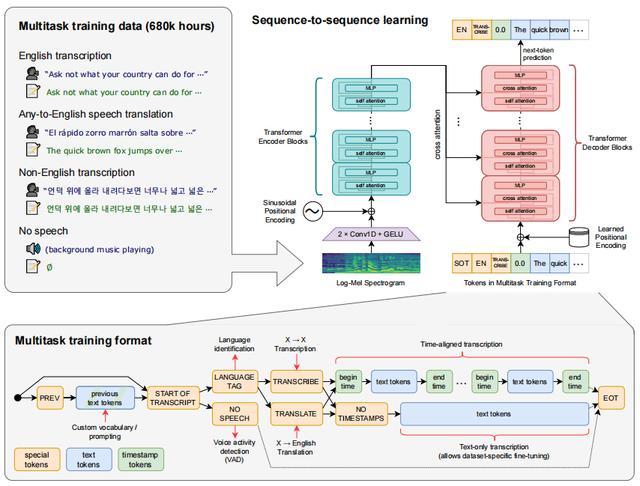
「Whisper 」式一个自动语音识别(ASR)系统,研究团队通过使用从网络上收集的68万个小时多语音和多任务监督数据,来对其进行训练。
训练过程中研究团队发现,使用如此庞大且多样化的数据集可以提高对口音、背景噪音和技术语言的鲁棒性。
此前有不同研究表明,虽然无监督预训练可以显著提高音频编码器的质量,但由于缺乏同等高质量的预训练解码器,以及特定于数据集中的微调协议,因此在一定程度上限制了模型的有效性和鲁棒性;而在部分有监督的方式预训练语音识别系统中,其表现会比单一源训练的模型呈现出更高的鲁棒性。
对此,在「Whisper 」中,OpenAI 在新数据集比现有高质量数据集总和大几倍的基础上,将弱监督语音识别的数量级扩展至68万小时;同时,研究团队还演示了在这种规模下,所训练模型在转移现有数据集的零射击表现,可消除任何特定于数据集微调的影响,以实现高质量结果。
前特斯拉人工智能和自动驾驶部门负责人 Andrej Karpathy 也转发了这一消息称“OpenAI 正处于最好的状态中”。
但对使用 Whisper 上,有不少用户也还存在疑虑。
网友 Vincent Lordier 提出,“此前在 GTP-3 和 Dalle-2 中出现对相关言论禁止行为,是否在使用 Whisper 时也会有, 是否会出现 Whisper 编辑/删除用户语音的情况?”
那么大家怎么看?
参考链接:https://openai.com/blog/whisper/

花粉社群VIP加油站
关于作者

猜你喜欢





































