
图1 ChatGPT技术原理图
第一阶段:训练监督策略模型。首先会在数据集中随机抽取问题,由标注人员给出高质量答案,然后用人工标注好的数据来微调GPT-3.5模型,获得SFT(Supervised Fine-Tuning)模型。
第二阶段:训练奖励模型(Reward Model,RM)。在数据集中随机抽取问题,使用第一阶段生成的模型生成多个不同的回答。标注人员对输出进行打分排序,使用排序结果数据来训练奖励模型。
第三阶段:采用强化学习中的PPO(Proximal Policy Optimization,近端策略优化)[9]来优化策略。首先使用第一阶段中的初始权重构造一个初始的PPO模型。针对在数据集中采样的新的问题,使用PPO模型生成回答,并用第二阶段训练好的RM模型给出回报分数。PPO策略可以会通过回报分数计算出策略梯度,并更新PPO模型参数。
2)国外主要申请人专利分析
随着2017年谷歌Transformer模型的提出,预训练语言模型开始显著发展,因此本文关于预训练语言模型技术的检索主要针对2017年之后申请的专利。在DWPI摘要数据库中,针对关键词“language model”、“train”、“fine-tune”进行简单检索,共有2600多篇专利文献。检索结果仅针对专利摘要进行检索,且为专利同族合并后的结果。
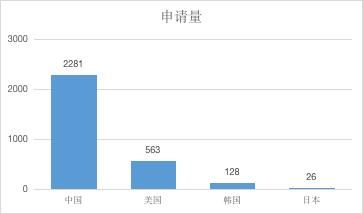
图2 预训练语言模型技术申请人来源国家
在预训练语言模型领域,中国企业发展迅速。百度、阿里、腾讯、华为都是主要申请人,且均在海外展开布局,国外申请人主要集中在微软、谷歌和三星。但是还应注意到,国外一些公司针对神经网络、编解码器结构改进的专利技术方案,在摘要中并没有提到语言模型,但是神经网络等是可以应用到语言模型中的,因此实际上关于预训练语言模型技术的申请量会更多。
为了更全面地了解国外申请人在中国的布局情况,针对全文数据再次检索,并统计合并同族的结果。
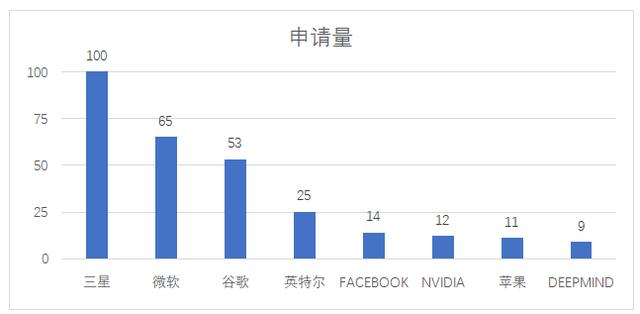
图4 谷歌部分专利
基于BERT模型,微软于2020年提出了DeBerta模型,并提交申请相关美国专利“具有解开注意力和多步解码的高效变压器语言模型”(US2021334475A1),利用多步解码来更好地重建掩蔽标记并改善预训练收敛来促进预训练的自然语言模型的自训练。2021年提出的LORA模型主要涉及神经网络模型的低秩自适应,冻结了预训练的模型权重(相关美国专利US2022383126A1)。此外,微软也在下游任务进行专利布局,例如其申请的PCT国际专利申请WO2022221045A1涉及多任务模型,包括例如共享编码器、多个任务特定编码器和用于多个任务的多个任务特定线性层等。
在Patentics的英文全文库中以“DeepMind”(DeepMind为Google旗下前沿人工智能企业)作为申请人,language model作为关键词进行检索,检索结果为27篇。DeepMind侧重于对神经网络的改进。中国专利“针对使用对抗训练的表示学习的推理的大规模生成神经网络模型”(CN113795851A),训练可以是基于损失函数,该损失函数包括基于由鉴别器神经网络处理的输入对的样本部分和潜在部分的联合鉴别器损失项和仅仅基于输入对的样本部分或潜在部分中的一个部分的至少一个单一鉴别器损失项,该专利在中美等国均有布局,根据英文库中检索得到的专利查找其中文同族,可以确定DeepMind在中国申请使用渊慧科技有限公司名称。
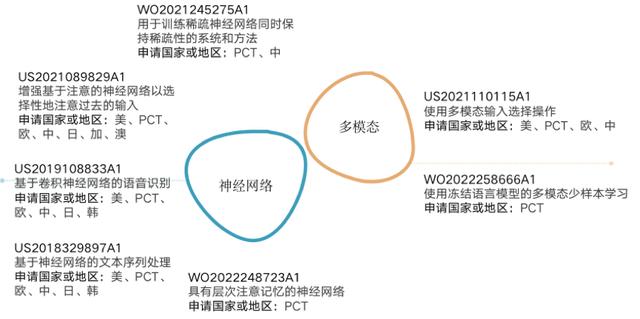
图5 DeepMind部分专利布局情况
由图5可以看出,DeepMind在多模态方面也有所布局,涉及冻结语言模型的多模态少样本学习以及使用多模态输入选择操作。多模态的语言模型是一种能够同时处理不同类型的数据,如文本、图像、音频和视频的人工智能技术。多模态语言模型的目标是实现跨模态的理解、生成和交互,从而提高人机对话和信息检索的效果。谷歌近期申请了基于UI的多模态模型,例如美国专利US2023031702A1通用用户界面转换器(VUT),处理三种类型的数据:图像、结构(视图层次)和语言,并且执行多个不同的任务,诸如UI对象检测、自然语言处理、屏幕摘要、UI可敲击性预测。微软的PCT国际专利申请WO2022187063A1则公开了一种视觉与语言的跨模态加工方法,基于视觉语义特征集和文本特征集来训练目标模型,以确定输入文本和输入图像之间的关联信息。
03 国内相关技术发展情况
在Patentics的中文数据库中,以“预训练”、“大规模”、“语言模型”、“微调”、“零/少样本”、“知识图谱”等作为关键词进行简单检索,共检索出12292篇专利,我们可以看出国内预训练大模型技术自2018年后开始迅速发展,鉴于目前21年、22年申请的专利未全部公开,实际上该领域的专利申请数量可能更多。
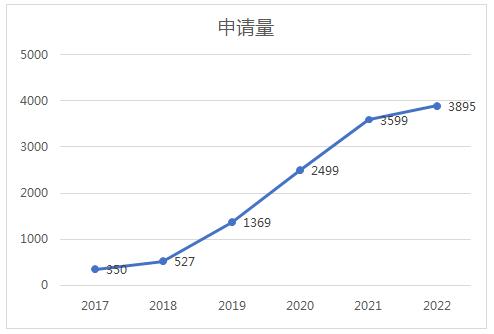
图7 人工智能大模型技术中国专利主要申请人[11]
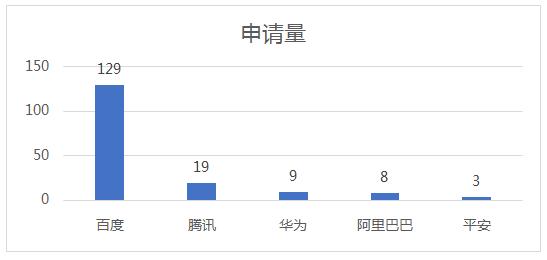
图9 国内语言模型相关专利发展情况
针对多模态模型,百度的中国专利CN115374798A提出将跨语言预训练目标和跨模态预训练目标无缝地组合在统一的框架中,从可用的英文图像字幕数据、单语语料库和平行语料库在联合嵌入空间中学习图像和文本。华为的中国专利CN115688937A将不同模态的数据的特征表示映射到同一个离散空间中,可以基于该离散空间对多模态的特征表示进行建模,得到兼容多模态输入数据的模型。
2)国内人机交互应用相关专利
而针对类似于ChatGPT的人机交互应用,国内申请人也有相应的专利布局,但未进行海外布局。
表1 国内主要公司的技术布局情况
图10 ChatGPT-3.5聊天截图
鉴于微软将GPT-4整合进NewBing中,笔者通过NewBing的聊天功能搜索美国专利US2021334475A1。虽然它能够完整的给出所有信息,但是除了发明名称是正确的,申请日、公开日、申请人、发明人信息都是错误的(见图11)。就此次结果而言,New Bing更倾向于在搜索的基础上对信息作出完整的补充,并不能保证真实性。

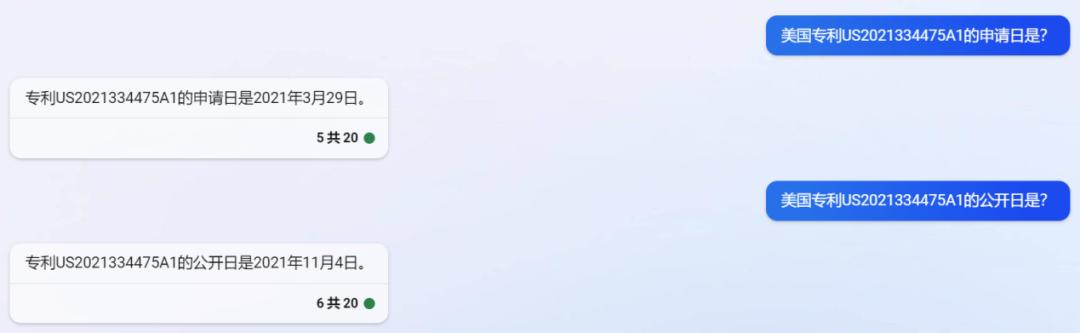
图11 New Bing聊天功能截图
需要注意的是,New Bing在多次尝试后,也会给出错误的答案(见图12)。
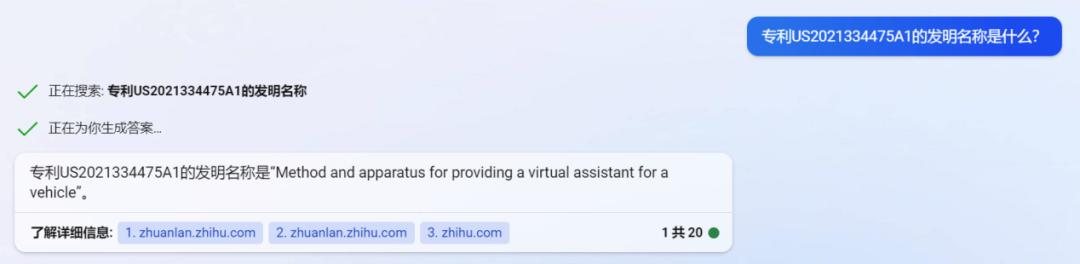
图12 New Bing聊天功能截图
ChatGPT-3.5以及NewBing都不能完整的提供专利文件信息,那么针对法律条款是否能获得较好效果呢?笔者分别向ChatGPT-3.5和NewBing询问“专利的技术方案是无法实现的,需要用到中国专利法的哪个法条”,ChatGPT给出的答案类似于使用大量法律文献训练模型的结果,虽然看似准确,但涉及的条款及其规定都不是中国专利法的内容,而NewBing则是搜索加工的结果,找到了适合的条款,但是法条规定的内容与该条款毫无关系。因此,ChatGPT-3.5和NewBing都不能保证生成内容的准确性。

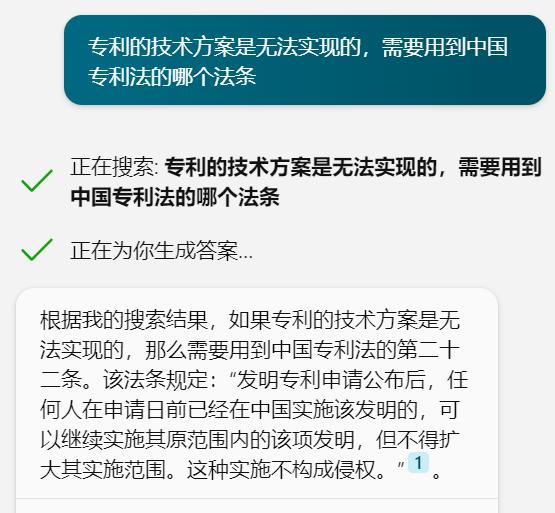
图13 ChatGPT-3.5与New Bing聊天功能对比
探究其原因,GPT-3.5只是基于本地的语料库进行搜索,没有联网,所以对于很多无法获取的信息会进行杜撰,缺乏准确性,但是GPT-4和New Bing是具有联网形态的大语言模型,回答问题时会首先通过用户的询问在互联网上搜索相关的语料进行补充,所以可以杜绝部分杜撰的情况,但是对于非常见的问题,或者是信息缺失的情境下,还是会有编造的风险。
此外,ChatGPT的训练和部署都需要大量算力来支持,因此可能需要更轻量化的模型。对于国内企业而言,需要通过加深国内产学研合作方式推动大模型发展。根据公开资料检索发现,鹏城实验室与华为合作开发盘古大模型,与百度合作开发鹏城-百度·文心大模型;另一方面,华为把科研院所、产业厂商等结合起来,以期更好地让大模型产业形成正向的闭环回路。
05 对国内大模型技术发展的启示
1)强调原始创新,发展大模型可持续演化
大模型的未来需要原始性创新,也需要自我生长,向可持续、可进化的方向发展。人工智能技术近年来呈指数型发展趋势,在当今政治经济环境下,我们更应强调原始创新的重要性,掌握根技术,但也不能拘泥于闭门造车,要求事事从零起步,要重视国际国内合作交流,实现大模型的可持续演化。
2) 建设大模型研发设施
如今的人工智能研究,已经突破单兵作战,“小作坊”式的埋头钻研无法在当下竞争日益激烈的环境中产出突破性科研成果。ChatGPT的横空出世也是基于前期几十亿美金的投入,大成果的产出必须依托大平台。国内应大力扶持高端科研平台,从数据、算力、工程创新能力三方面,三位一体加快建设大科学设施集群。
3) 人才队伍培养
科技创新的竞争本质是科技人才的竞争。从前文分析可知,OpenAI的成功除了大量算力的投入,更重要的是聚集了大量顶尖的科学家和工程师。面向全球吸引具备攻克技术难关能力的杰出人才,选拔具备国际影响力的领军人才,培育具备较高发展潜力的青年人才,将会是国内人工智能发展的重要手段。
4) 差异化竞争,安全伦理性加强
大模型技术的红利期还很长,ChatGPT的火爆出圈并不代表国内完全丧失先机,只能做跟跑者。文本语言类大模型,OpenAI走在前列,但在多模态大模型领域,世界各国科学家还在攻克技术难题。国内要想在新一轮人工智能科技创新中成为领跑者,就必须要学会差异化竞争,做出中国特色。大模型技术的演化一定会越来越强调科技伦理治理、系统安全性,在安全伦理方面的建设,突出中国价值观,也是我们需要关注的重点。
参考文献
[1]Greg Brockman etal. Introducing OpenAI. URL https://openai.com/blog/introducing-openai/, 2015.
[2] OpenAI Charter. URL https://openai.com/charter, 2018.
[3] 2023年1月10日路透社报道. URL https://www.reuters.com/technology/microsoft-talks-invest-10-bln-chatgpt-owner-semafor-2023-01-10/, 2023.
[4] Paul F Christiano et al. Deep Reinforcement Learning from Human Preferences.URL Deep Reinforcement Learning from Human Preferences, 2017.
[5] Nisan Stiennon et al. Learning to summarize from human feedback. URL https://arxiv.org/abs/1706.03741, 2019.
[6] OpenAI. GPT-4 Technical Report. URL https://arxiv.org/abs/2303.08774, 2023.
[7] 智谱研究&AMiner. ChatGPT团队背景研究报告. URL https://originalfileserver.aminer.cn/sys/aminer/ai10/pdf/ChatGPT-team-background-research-report.pdf, 2023.
[8] OpenAI. Introducing ChatGPT. URL https://openai.com/blog/chatgpt, 2022.
[9] John Schulman et al. Proximal Policy Optimization Algorithms. URL https://arxiv.org/abs/1707.06347, 2017.
[10] William Fedus. Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity. URL https://arxiv.org/abs/2101.03961, 2021.
[11] IPRdaily. 中国人工智能大模型企业发明专利排行榜(TOP 50). URL http://www.iprdaily.cn/article1_33676_20230320.html, 2023
免责声明:本文转自三思派,原作者陟爽 鹿艺 冯璟艳。文章内容系原作者个人观点,本公众号编译/转载仅为分享、传达不同观点,如有任何异议,欢迎联系我们!
转自丨三思派
作者丨陟爽 鹿艺 冯璟艳
研究所简介
国际技术经济研究所(IITE)成立于1985年11月,是隶属于国务院发展研究中心的非营利性研究机构,主要职能是研究我国经济、科技社会发展中的重大政策性、战略性、前瞻性问题,跟踪和分析世界科技、经济发展态势,为中央和有关部委提供决策咨询服务。“全球技术地图”为国际技术经济研究所官方微信账号,致力于向公众传递前沿技术资讯和科技创新洞见。
地址:北京市海淀区小南庄20号楼A座
电话:010-82635522
微信:iite_er

花粉社群VIP加油站
关于作者

猜你喜欢





































