
Dali代表作《记忆的永恒》和机器人总动员海报。
在博客上,OpenAI也大秀了一把DALL·E的“超强想象力”,随意输入一句话,DALL·E就能生成相应图片,这个图片可能是网络上已经存在的图片,也可能是根据自己的理解“画”出的。

输入文本分别是:穿芭蕾舞裙遛狗的萝卜、牛油果形状的扶手椅、将上部的图片素描化
DALL·E是如何实现先理解文字,再创造图片的呢?
那首先要从理解token开始,语言学中对token的定义是词符,或者标记。对于英语来说,每个字母就是一个token,每一个单词就是一个tokens。
但在NLP中,tokens并不一定代表完整的单词,如re、ug等没有实际意义的字母组合也算一个tokens。
在最早提出Transformer架构的论文《Attention is all you need》里,就提到了BPE(Byte-Pair Encoding)编码方法,简单来说,BPE就是通过分析训练集中每个单词的组成,创建一个基础词汇表,词汇表里涵盖了一定数量最常用的tokens。
模型中tokens的数量是超参数,也就是训练模型中人为规定的。
DALL·E同时包含着BPE编码的文本和图像词汇表,分别涵盖了16384、8192个tokens。
当需要生成图片时,它以单一数据流的形式,接收1280个文本和图像的tokens(文本256个tokens,图像1024个tokens),建立回归模型。
与大多数Transformer模型一样,DALL·E也采用自注意力机制(Self-Attention),分析文本内部的联系。
在DALL·E的64层自注意层中,每层都有一个注意力mask,就是为了使图像的每个tokens都能匹配文本tokens。
OpenAI也表示,更具体的架构和详细训练过程会在之后的博客中公布。
二、普适的DALL·E:从改变物体关系到创造“不存在”比起长篇累牍地描述自己模型的优越性,OpenAI则是用大量实测案例证明了自己。
1、改变单个物体的某个属性
如动图所示,我们可以通过简单地改变按钮选项,将钟改为花盆,再将绿色改为黄色,再将三角形改为正方形。

原输入文本:特写图下,在草地的水豚
除了二维图像理解,DALL·E也能将某些类型的光学畸变(Optical Distortions)应用到具体场景中,展现出“鱼眼透视”或“球形全景态”图等效果。
4、内外部结构

在众多数据集上,CLIP都有着可以与ResNet50升级版ResNet101媲美的精度,其中ObjectNet数据集代表模型识别物体不同形态和背景的能力,ImageNet Rendition和ImageNet Sketch代表模型识别抽象物体的能力。
虽然二者在ImageNet测试集上的表现相差无几,但非ImageNet设置更能代表CLIP优秀的泛化能力。
为了识别出未曾见过的类别(图像或文本),Zero-shot这一概念可以追溯到十年前,而目前计算机视觉领域应用的重点是,利用自然语言作为灵活的预测空间,实现泛化和迁移。
在2013年,斯坦福大学的Richer Socher教授就曾在训练CIFAR-10的模型时,在词向量嵌入空间中进行预测,并发现该模型可以预测两个“未见过”的类别。
刚刚登上历史舞台、用自然语言学习视觉概念的CLIP则带上了更多现代的架构,如用注意力机制理解文本的Transformer、探索自回归语言建模的Virtex、研究掩蔽语言建模的ICMLM等。
四、详细解析,CLIP的“足”与“不足”在对CLIP有一个基本的认识后,我们将从四个方面详细剖析CLIP。
1、从CLIP流程,看三大问题如何解决
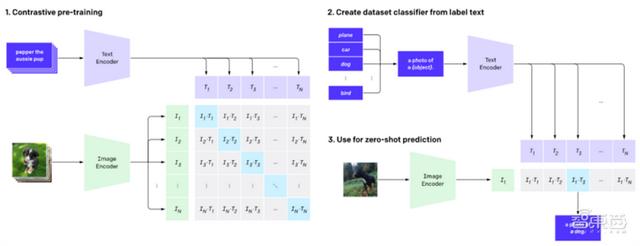
简单来说,CLIP的任务就是识别一张图像所出现的各种视觉概念,并且学会它的名称。比如当任务是对猫和狗的图片进行分类,CLIP模型就需要判断,目前处理的这张图片的文字描述是更偏向于“一张猫的照片”,还是一张狗的照片。
在具体实现上,有如下流程:预训练图像编码器和文本编码器,得到相互匹配的图像和文本,基于此,CLIP将转换为zero-shot分类器。此外,数据集的所有类会被转换为诸如“一只狗的照片”之类的标签,以此标签找到能够最佳配对的图像。
3、实际应用性能不佳:基准测试中表现好的模型在实际应用中很可能并没有这么好的水平。就像学生为了准备考试,只重复复习之前考过的题型一样,模型往往也仅针对基准测试中的性能进行优化。但CLIP模型可以直接在基准上进行评估,而不必在数据上进行训练。
2、CLIP的“足”:高效且灵活通用。
CLIP需要从未经标注、变化多端的数据中进行预训练,且要在“zero-shot”,即零样本的情况下使用。GPT-2/3模型已经验证了该思路的可行性,但这类模型需要大量的模型计算,为了减少计算量,OpenAI的研究人员采用了两种算法:对比目标(contrastive objective)和Vision Transformer。前者是为了将文本和图像连接起来,后者使计算效率比标准分类模型提高了三倍。
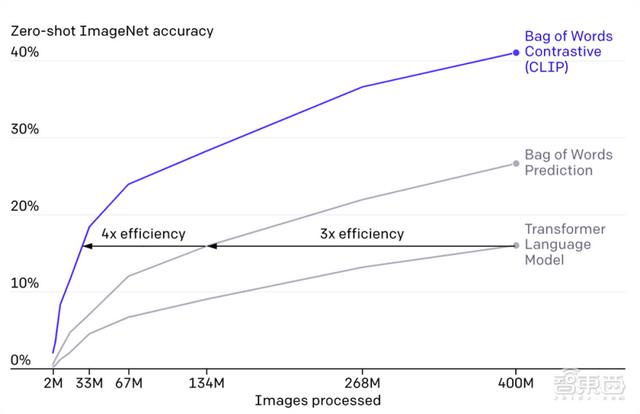
CLIP模型在准确率和处理图像大小上都优于其他两种算法。
由于CLIP模型可以直接从自然语言中学习许多视觉概念,因此它们比现有的ImageNet模型更加灵活与通用。OpenAI的研究人员在30多个数据集上评估了CLIP的“zero-shot”性能,包括细粒度物体分类,地理定位,视频中的动作识别和OCR(光学字符识别)等。
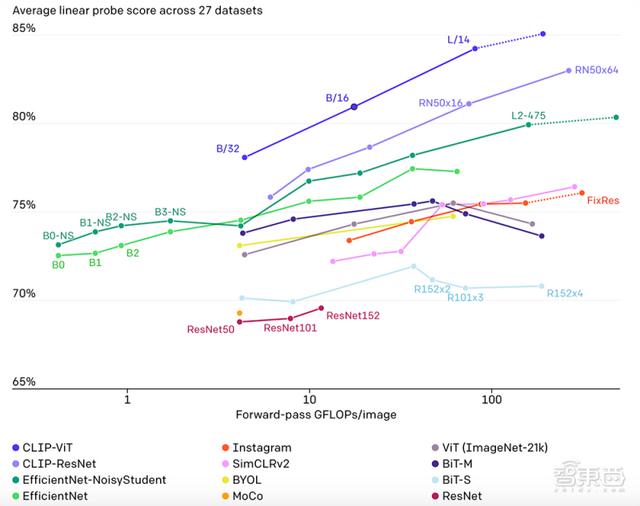
下图也展示了12种模型在27种数据集准确率和处理图像大小的比较。CLIP-ViT和CLIP-ResNet两类CLIP方法都遥遥领先。

花粉社群VIP加油站
关于作者

猜你喜欢





































