
【新智元导读】去年当红的流量明星非GPT-3莫属,能答题、写文章,做翻译,还能生成代码,做数学推理,不断被人们吹捧。不过,过誉的背后也有人开始质疑,GPT-3真的达到了无所不能的地步了吗?
红极一时的GPT-3现在却饱受诟病~
被捧上天的流量巨星,突然就不香了
去年6月,OpenAI开发的GPT-3被捧上了天。
由1750亿个参数组成,训练花费数千万美元,是当时最大的人工智能语言模型。
从回答问题、写文章、写诗歌、甚至写代码……无一不包。
OpenAI的团队称赞GPT-3太好了,人们都难以区分它生成的新闻文章。

目前,开发人员正在测试GPT-3的能力,包括总结法律文件、为客户服务查询提供答案、提出计算机代码、运行基于文本的角色扮演游戏等等。
随着它的商用,有很多问题逐渐暴露。
尽管GPT-3具有通用性,但它并没有解决困扰其他生成文本程序的问题。
OpenAI 首席执行Sam Altman去年7月在推特上表示,「它仍然存在严重的弱点,有时还会犯一些非常愚蠢的错误。尽管GPT-3观察到它读到的单词和短语之间的统计关系,但不理解其含义。」
GPT-3是一个并不成熟的新事物,它还需要不断地驯化。
就像小型聊天机器人一样,如果让它即兴发言,GPT-3可以喷出产生种族主义和性别歧视的仇恨言论。

研究人员对于如何解决语言模型中潜在的有害偏见有一些想法,向模型中灌输常识、因果推理或道德判断仍然是一个巨大的研究挑战。
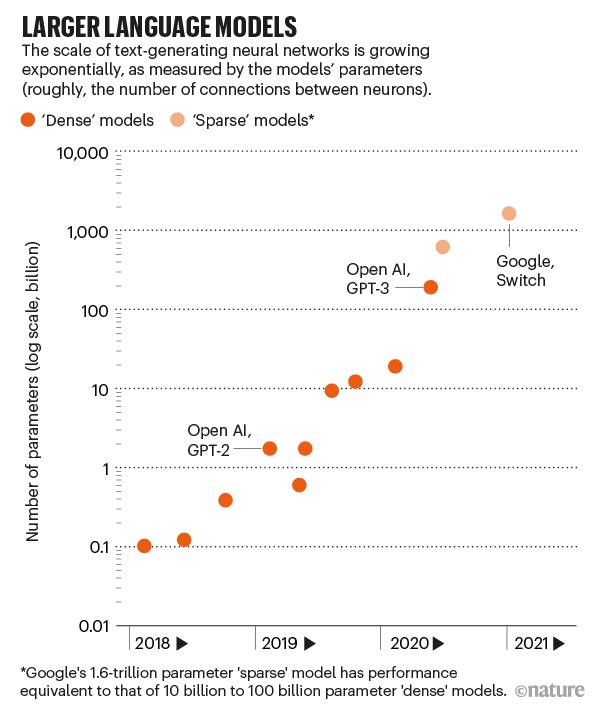
1750亿个参数到万亿参数,逐渐「膨胀」的语言模型
神经网络语言模型是受大脑神经元连接方式启发的数学函数。
通过推测它们看到的文本中被模糊处理的单词来进行训练,然后调整神经元之间的连接强度,以减少推测错误。
GPT-3的全称叫生成预训练转换器-3 (Generative Pretrained Transformer-3)。
这是生成预训练转换器第三个系列,是2019年GPT-2的100多倍。
仅仅训练这么大的模型,就需要数百个并行处理器进行复杂的编排。
因此它的能力,一个神经网络的大小,是由它有多少参数粗略地测量出来的。
这些数字定义了神经元之间连接的强度,更多的神经元和更多的连接意味着更多的参数。
就拿GPT-3来说,有1750亿个参数。第二大的语言模型有170亿参数。
今年1月,谷歌发布了一个包含1.6万亿个参数的模型,但它是一个「稀疏」模型,这意味着每个参数的工作量较小。
这篇论文的一位作者Kris McGuffie表示,它能如此轻易地生成出黑暗的例子,实在令人震惊。如果一个极端组织掌握了GPT-3技术,它便可以自动生成恶意内容。
OpenAI 的研究人员也检测了GPT-3的偏差。
在去年5月的论文中,他们要求它完成一些句子,比如「黑人非常...」。
GPT-3则用负面的词汇来描述黑人和白人的差异,把伊斯兰和暴力联系在一起,并假定护士和接待员都是女性。
人工智能伦理学家Timnit Gebru与Bender等人合著了「On the Dangers of Stochastic Parrots」一文中指出,这是大型语言模型急切关注的问题,因为它表明,如果技术在社会中普及,边缘群体可能会经历不正当手法引诱。

一个明显的解决偏见的方法是从训练前的数据中剔除有害的文字,但是这就提出了排除哪些内容的问题。
研究人员还表示,他们可以提取用于训练大型语言模型的敏感数据。
通过提出细致的问题,他们找到了GPT-2能够逐字记忆的个人联系信息,发现较大的模型比较小的模型更容易受到这种探测。
他们写道,最好的防御措施就仅是限制训练数据中的敏感信息。
拯救没常识的GPT-3
从根本上说,GPT-3和其他大型语言模型仍然缺乏常识,即对世界在物理和社会上如何运作的理解。
更大的模型可能会做得更好,这就意味着参数更多、训练数据更多、学习时间更长。

但这种情况训练一个超大模型将变得越来越昂贵,而且不可能无限期地持续下去。
语言模型的非透明复杂性造成了另一个局限。
如果一个模型有一个偏见或者不正确的想法,就很难打开黑盒子去修复它。
未来的路径之一是将语言模型与知识库结合起来,即事实性管理数据库。
在去年的美国计算机语言学协会会议上,研究人员对 GPT-2进行了微调,使其能够从常识概要中清晰地陈述事实和推论。

因此,它写出了更有逻辑性的短篇小说。
OpenAI 正在寻求另一种引导语言模型的方式: 微调过程中的人工反馈。
在去年12月举行的 NeurIPS 会议上发表的一篇论文中,论文描述了两个较小版本的 GPT-3的工作情况,这两个版本在如何汇总社交新闻网站 Reddit 上的帖子方面进行了微调。
研究小组首先要求人们对一组现有的摘要进行打分。然后训练一个评价模型来再现这种人的判断。

最后,该团队微调了GPT-3模型,以生成总结取悦这个人工智能法官。
结果是,一组单独的人类评判员甚至更喜欢比人类编写模型的总结。
只要语言模型仅停留在语言领域,它们可能永远无法达到人类的常识水平。
语言之所以对我们有意义,仅仅是因为我们把它建立在纸上的字母之外的东西上; 人们不会通过统计单词的使用频率来吸收一本小说。
Bowman预见了三种可能的方法来获得语言模型的常识。对于一个模型来说,使用所有已经编写的文本就足够了。
参考资料:
https://www.nature.com/articles/d41586-021-00530-0

花粉社群VIP加油站
关于作者

猜你喜欢





































