机器之心报道
编辑:梓文
开源模型真的超过 ChatGPT了吗?
大模型火了起来,每天我们都能看到各种「大」新闻。
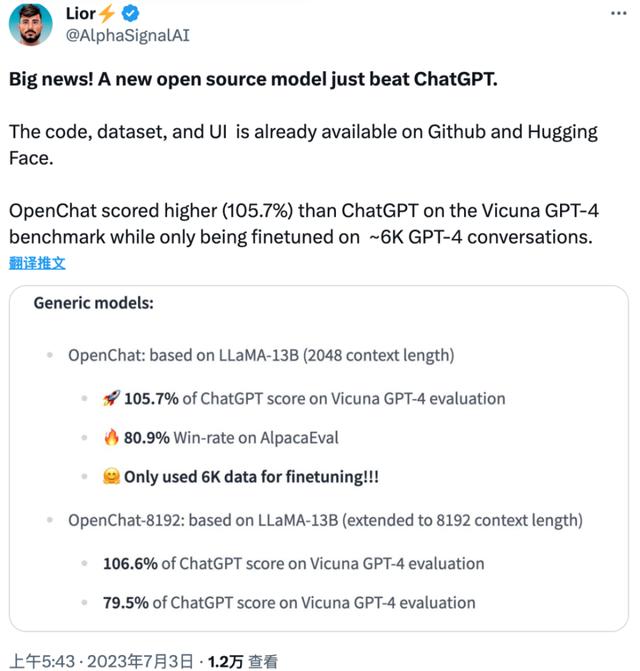
也就是上面推特截图中,两位博主宣称的开源模型超越 ChatGPT/GPT-3.5。
OpenLLM 的特色是基于 LLaMA 开源模型,在只有 6,000 个 gpt4 对话的数据集上进行微调,从而达到非常好的效果。
此次更新的模型型号与评审结果如下:
OpenChat:基于 LLaMA-13B,上下文长度为 2048。
在Vicuna GPT-4 评估中达到 ChatGPT 分数的 105.7% 。
在 AlpacaEval 上达到 80.9% 的胜率。
OpenChat-8192:基于 LLaMA-13B,扩展上下文长度为 8192。
在 Vicuna GPT-4 评估中达到 ChatGPT 分数的 106.6% 。
在 AlpacaEval 上实现 79.5% 的胜率。
也就是说,两个模型在 Vicuna GPT-4 评估榜单上结果都超越了 ChatGPT。
但这种评审 宣传的方式似乎并不被大家认可。
网友:夸张
在 Twitter 讨论中,有网友表明,这就是夸张的说法。

在此「大」新闻公布后,Vicuna 官方也迅速做出了回应。
实际上,Vicuna 的测试基准已被弃用,现在使用的是更高级的 MT-bench 基准。该基准的测试,有着更加具有挑战性的任务,并且解决了 gpt4 评估中的偏差以及限制。
在 MT-bench 上,OpenChat 性能表现与 wizardlm-13b 相似。也就是说,开源模型与 GPT-3.5 仍然有着一定差距。这也正是 MT-bench 所强调的内容 —— 开源模型不是完美无缺的,但是这将迈向更好的聊天机器人评估。

前几日,机器之心报道内容《「羊驼」们走到哪一步了?研究表明:最好的能达到 GPT-4 性能的 68%》,也对开源模型的性能进行了评估。
评估还表明,在任何给定的评估中,最佳模型的平均性能达到 ChatGPT 的 83%、GPT-4 的 68%,这表明需要进一步构建更好的基础模型和指令调优数据以缩小差距。

花粉社群VIP加油站
关于作者

猜你喜欢





































