在 4 月 14 日,OpenAI Five 代表人工智能拿下了与人类的竞争史上又一个里程碑:以 2 比 0 的绝对优势击败了 Dota 2 TI8 冠军 OG 战队。其中甚至以碾压之势拿下第二盘,仅用 22 分钟就“打卡下班”。比赛 4 天后,OpenAI 宣布将开放为期 3 天的 Arena 竞技场模式,邀请所有 Dota 2 玩家挑战OpenAI Five。
这场“人机大战”的竞技场于北京时间 4 月 22 日正式落幕。AI 在 Dota 2 竞技场上获得的最终成绩为 7215 : 42,胜率高达 99.4%,足以看出 OG 的败北并不是偶然事件。

图 | OpenAI Five 的战绩(来源:OpenAI Arena)
相比较 8 个多月前 TI8 上的表现,我们能明显看到 AI 的进步。比赛中有很多亮眼和极限操作,比如死血冰女果断开大反杀两人,家常便饭一样的吹风/BKB 躲先手,走走停停的暗影护符卡视野等等,顶级人类玩家都未必能保证 100% 做到。
除了惊讶于 AI 的进步速度,Dota 社区有很多声音认为 OG 只是“随便玩玩,没认真打”,而 OpenAI 随后推出的竞技场模式,就像是一封 AI 递给人类的战书,上书四个大字:You Can You Up。
笔者作为 Dota 老玩家,必然不能错过这千载难逢的机会,但由于找不到足够的人手对抗 AI,只能自己带 4 个 AI 娱乐一下。在连输两局之后基本摸清了 AI 队友的脾气(从不听话)和制裁 AI 的套路(隐身等于无敌),通过疯狂带线和毒瘤发育连赢三场“膀胱局”(指游戏时间特别长的对局),总算是勉强保住了 5000 分的尊严。

(来源:OpenAI)
AI 称霸,但人类大神达成十连胜竞技场有两种模式,一种是五名人类玩家组队对抗 AI,另一种是人类 AI 的合作模式。
目前竞技场已经关闭,OpenAI 还未放出详细的比赛录像和结果解析,不过根据排行榜数据和社区反馈,我们可以挖掘出很多关于 OpenAI Five 的特征。
值得注意的是,AI 的 99% 胜率看似恐怖,其实里面有很多“水分”,比如组队娱乐的玩家。最有分析价值的还是人类获胜的比赛。
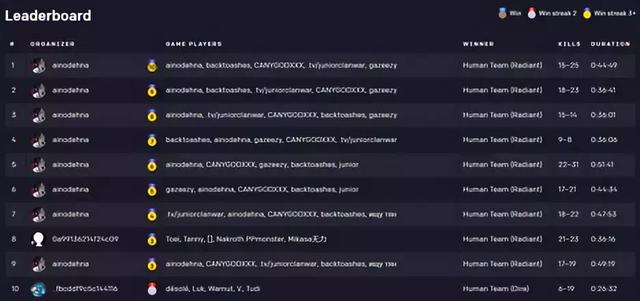
图 | 队伍中单 junior 的 DotaBuff 资料(来源:DotaBuff)
热心网友教你识破 AI 套路即便如此,想要获得十连胜也绝对不是一件容易的事。哪怕是两支水平相近的人类队伍对战,也很少有这样的连胜,他们所用的技巧因此引发了热议。
由于这些比赛会在 Twitch 上直播,也会有人将人类胜利的视频放到 YouTube 上,所以很快就有热心网友在 Reddit 论坛上整理出了“如何打败 AI”的帖子。
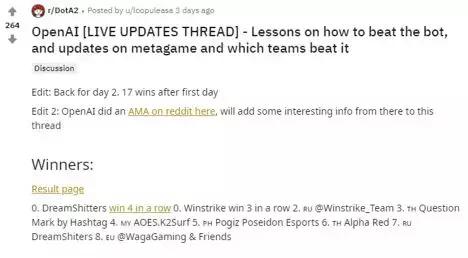
图 | 网友总结如何打败 AI 的帖子(来源:Reddit)
最开始的 1000 局比赛里,人类队伍只赢了 3 局。但随着时间的推移,OpenAI 的弱点逐渐暴露。就像所有游戏的 AI 一样,如果你足够强,击败 AI 总有套路可寻。
AI 的 5V5 团战和遭遇战都很强,但却不擅长应对带线和分推战术,不擅长插眼和反眼,对信使的保护也很糟糕。它们在逆风局的时候大多窝在家里「打麻将」,不爱主动出击,甚至还会顶着偷塔保护强拆兵营和基地,直到自己的高地建筑几乎被拆光了才回家。
最致命的是,AI 非常不擅长应对隐身单位,隐身等于无敌。
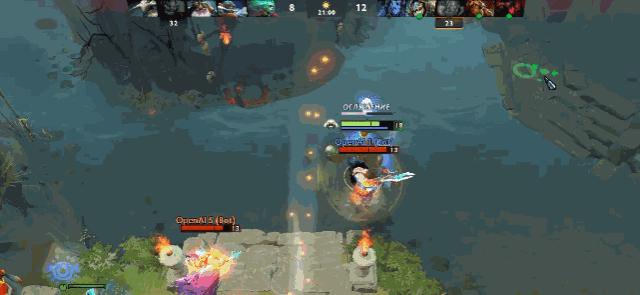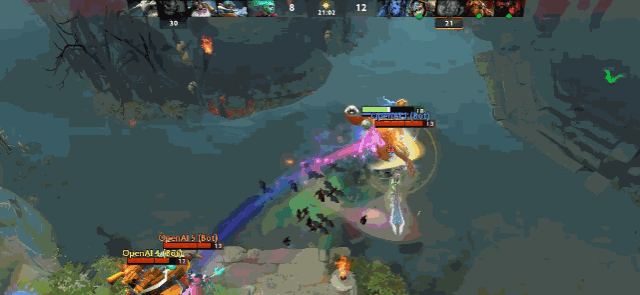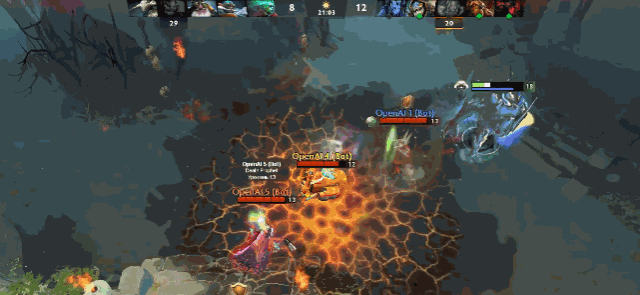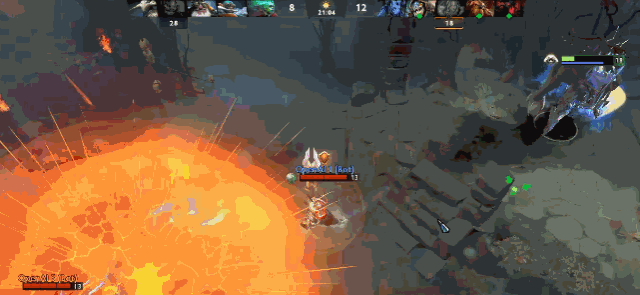
图 | 双大哥隐刀 BKB 拆家
从大数据到小数据现代机器学习领域最热门的莫过于深度学习(AlphaGo)和强化学习(OpenAI Five)等人工神经网络。当 AI 系统一次次在围棋、电子游戏、图像识别、自然语言处理等多个应用领域追上、甚至超越人类后,很多人都在使用这些技术探索可以应用于多个领域的 AGI 的可能性。
但是,这些技术都依赖于海量数据和计算资源,比如训练 AI 识别医疗影像,进行中英翻译或听懂你说的话,均需要数十万份训练数据才能训练出表现出色的模型。但它们也只能在特定场景下才能使用。因此,相对于被称之为“强人工智能”的 AGI,这类 AI 系统普遍被称为“弱”或“窄人工智能”(Narrow AI)。
如果想再更进一步,进军 AGI,首先要攻克的就是在冷门应用场景下,训练数据稀少的问题。

(来源:Pixabay)
目前已有类似的努力,比如“仅需”数千个数据就能生效的生成模型(Generative Models)、数据需求进一步降低至数百的迁移学习(Transfer Learning),可以从零开始的单样本学习(one-shot learning)和自我对战 (Self-Play),这都是近几年的新兴概念。
生成模型的基础思想为“训练算法来生成自己的训练数据”,通过生成一个能够抽取出基类数据的模型,根据少量的训练数据,凭空“想”出大量的训练数据。对于图像来说,迄今最成功的生成模型是生成对抗网络(GAN)。正如生成对抗网络的发明人 Ian Goodfellow 所说的,生成模型给机器带来了“想象力”。
但是,有些应用场景连训练生成模型的数据都凑不够。因此,由人类儿童学习方式启发的迁移学习诞生了。
迁移学习是深度学习领域为了解决其海量数据需求而开发的一种手段。其基础在于先用一个有着大量训练数据的场景训练模型。完成训练后,该模型的特征将适用于所有跟这个应用场景相关或类似的具体场景。
换句话说,这个模型“学会”的特征可以被“迁移”到另外一个应用场景。比如用具有 1400 万张照片的 ImageNet 去训练一个图像识别模型(通用特征),然后再训练这个模型去具体地识别医疗成像中的肿瘤(具体应用)。
但迁移学习的基础也限制了它的应用场景:如果一个任务的所有相关任务都缺少数据(比如打 Dota 2),就无法训练迁移学习所需的“通用模型”(生成模型因此也不适用)。这也是将深度学习扩散到新的(少数据)应用领域时所面临的最大挑战。
在计算机视觉任务领域,为了减少对训练数据的依赖,研究人员正在努力研发单样本学习。单样本,指的是借助元学习(Meta Learning)技术的支持,只用展示一张图片或者一段演示,就可以让 AI 认识某个物品,学会某种技能,从而具备一种“触类旁通”的能力。
而在其他从零开始的应用场景中,AI 可以根据规则在自我对战中进行学习,这也正是 OpenAI Five 和 DeepMind 的 AlphaGo Zero 所使用的技术。自我对战最大的优势在于可以“从零开始”,在大量的对战中进行优化,用大量的计算力和训练时间来掌握一个技能。
无论哪种方法,我们都能看出类似的趋势:减少数据需求。但是,从 OpenAI Five 竞技场的表现来看,虽然现有的技术手段能够有效地减少对数据的依赖,却依然无法有效地提高模型训练的速度。
所幸,提升学习速度也是当下机器学习领域的一个大热门。可以预见的是,从 AI 到 AGI,将是一个漫长的发展历程,而只借助少量数据就能迅速学习新技能的能力,将是发展过程中的最大难题之一。

花粉社群VIP加油站
关于作者

猜你喜欢





































