 席卷全球的新风口
席卷全球的新风口OpenAI去年发布了聊天机器人模型ChatGPT,它能够理解和生成人类语言,并在许多自然语言处理任务中表现非常出色。据统计,上线仅两个月,ChatGPT活跃用户已经超亿,打破了由TikTok创造的9个月实现亿级用户注册的纪录,引起了各行各业人们的强烈关注。就连埃隆·马斯克也忍不住发推表示,ChatGPT厉害得吓人,我们距离危险而强大的AI不远了。当然,在一顿痛批ChatGPT之后,马斯克也准备亲自下场,成立研究实验室,开发ChatGPT的竞品。
类ChatGPT模型的开发与应用,在国内也迅速成为资本市场关注、创业者纷纷入场的赛道。阿里、百度等互联网大厂,科大讯飞等语音类AI企业,以及众多创业者都希望乘着最新的风口迅速“起飞”。创业者大军中不乏像前美团联合创始人王慧文、出门问问CEO李志飞、搜狗前CEO王小川、前京东技术掌门人周伯文等行业大佬。开发出“中国的ChatGPT”俨然成了国内科技圈“All in”的方向。
然而,我们真的能迅速见到一个“中国的ChatGPT”吗?谁又能拔下头筹,成为这个细分赛道的领头羊呢?
这个众多大佬都挤进来“淘金”的赛道,一定不是简简单单就能搞定的。
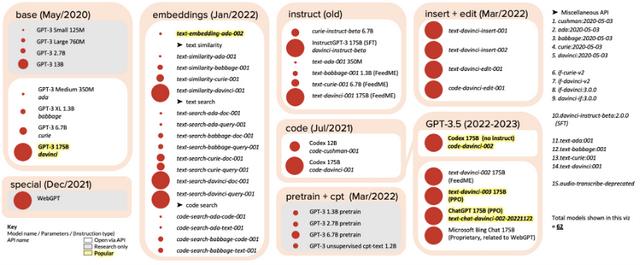
OpenAI的GPT“家族”在深入了解开发出比肩ChatGPT的模型需要面临哪些挑战之前,让我们先看下ChatGPT所属的GPT模型家族都有哪些成员。
GPT-1发布于2018年6月,包含117M个参数。这是第一个采用基于Transformer的模型架构进行预训练的模型。它在语言模型和单词类比任务上表现出色。GPT-2发布于2019年2月,包含1.5B个参数。这个模型在自然语言生成任务上表现出色,可以生成高质量的文章、新闻报道和诗歌等文本。GPT-3发布于2020年6月,包含175B个参数。具有出色的通用性和创造性,可以在各种 NLP任务上表现出色,包括文本生成、问答、机器翻译等任务。到这就结束了?完全不是。
在GPT-3系列模型(注意,是一系列模型哦)发布之后,OpenAI继续基于原始的GPT-3进行了不断地完善。我们熟知的InstructGPT和ChatGPT实际的内部代号是text-davinci-003 175B和text-chat-davinci-002-20221122,是基于GPT-3.5的改良版。
 数据量:需要大量的数据集来进行训练。这些数据集需要是大规模的、多样化的、真实的,并且要涵盖各种不同的语言和语境。这需要花费大量的时间和资源来收集、整理和标注。计算能力:需要非常强大的计算资源。这些模型需要在大规模的数据集上进行训练,并且需要进行大量的参数优化和调整。这些计算需要高性能的计算机和高效的分布式计算框架。算法优化:需要对算法进行不断的优化和改进。这包括优化网络结构、调整超参数、使用更好的优化算法等。这需要对深度学习算法有深入的了解和经验。
数据量:需要大量的数据集来进行训练。这些数据集需要是大规模的、多样化的、真实的,并且要涵盖各种不同的语言和语境。这需要花费大量的时间和资源来收集、整理和标注。计算能力:需要非常强大的计算资源。这些模型需要在大规模的数据集上进行训练,并且需要进行大量的参数优化和调整。这些计算需要高性能的计算机和高效的分布式计算框架。算法优化:需要对算法进行不断的优化和改进。这包括优化网络结构、调整超参数、使用更好的优化算法等。这需要对深度学习算法有深入的了解和经验。可以发现,这是一个涉及到多个领域和技术的复杂系统工程。只有同时在底层的基础设施、针对性优化和大模型技术积淀都达到一定水平的情况下,才能够研发出高质量的模型,并应用于各种场景中。
让我们详细看看这三类技术挑战具体都意味着什么。
数据量
我们经常听到“有多少数据,就有多少智能”,数据对于模型训练的重要性不言而喻。类ChatGPT模型的训练,更需要超大规模的,经过清洗的数据。以GPT-3的训练为例,需要300B tokens的数据。大家如果对这个数字不敏感的话,可以参考整个英文的维基百科的数据量,只有“相对可怜”的3B tokens,是训练GPT-3所需的百分之一。并且,要训练出类ChatGPT模型,势必需要数倍于当年训练GPT-3的数据量的中文语料数据,这对于大部分企业或科研机构来说都是难以翻越的大山。有效的中文数据量,一定程度上决定了模型性能的上限。
计算能力
类ChatGPT模型的训练,除了需要非常多的训练数据外,也离不开庞大的算力支撑。根据北京智源人工智能研究院公布的数据,使用300B tokens的数据训练175B参数规模(与GPT-3规模相同)的模型,如果使用96台通过200Gb IB网卡互联的DGX-A100节点,需要约50天。要是使用更大规模的训练数据集,训练时长还会进一步增加。
对于计算集群来说,不仅需要能够提供海量的算力资源,还需要具备高速网络和高容量存储,以便支持大规模的数据访问和模型传输。整套基础设施,连同软件平台,还需要结合集群的拓扑结构针对分布式训练进行优化,通过调整并行策略等方式,提升硬件利用率与通讯效率,缩短整体训练时间。
算法优化
算法优化和模型的训练效率和效果息息相关。每一个算法研究员,都希望模型在训练过程中快速收敛,这恰恰也是算法研究人员经验与企业长年技术积累的体现。通常情况下,在训练的过程中需要不断调整学习率、批量大小、层数等超参数,或使用自动调参的技巧和经验,才能快速、稳定的实现模型收敛。就像中餐大厨们用“少许、适量”的调料制作美味佳肴一样,里面包含着的是大厨们几十年的手艺,不是一朝一夕就能被批量复制的。
前途是光明的,道路是曲折的想必,这是最适合送给现在想要开发出“中国的ChatGPT”的各路大佬们的一句话了。在美国去年对中国限制了高端GPU的销售之后,为规避未来的技术风险,不少厂商、科研机构也开始探索在国产算力服务平台上训练的可行性。北京智源人工智能研究院作为国内顶尖的人工智能领域研究机构,早早就探索了使用国产算力服务平台的可能性。同样是使用300B tokens的数据训练175B参数规模的模型,通过曙光提供的算力服务,训练周期只需29.10天,在节点规模接近的情况下,训练效率是其他算力平台的300%。
基于国产算力服务平台进行训练,不可避免的会带来更多的移植与调优工作。曙光智算强大的硬件与算法优化团队,在集群、并行策略、算子、工具包等方面的优化上与智源开展了深入的合作。首先,为保证程序能够正常运行,需要完成包括DeepSpeed/Megatron/Colossal-AI/apex等必要组件的适配工作。其次,超大规模集群的顺利调度通常也需要调整调整操作系统配置及tcp协议参数等。训练的优化工作则主要包含以下三个方面:
算子层面:使用算子融合/算子优化等技术,深度挖掘硬件性能,提升硬件使用率;策略层面:采用模型并行、数据并行、流水线并行、Zero等多级并行策略,实现超大规模训练;集群层面:针对硬件集群的拓扑结构,对分布式训练通信、并行分组配比等进行定制优化,提升训练扩展比。通过一系列的优化方法,最终也证明了我们可以在国产算力服务平台上,以能够对标国际水平的效率实现大模型的开发工作,这无疑为“中国的ChatGPT”的开发工作喂了一颗定心丸。希望在不久的将来,我们可以看到真正在国产算力平台上训练的,能与ChatGPT比肩的中文模型。
前途一定是光明的。
— 完 —

花粉社群VIP加油站
关于作者

猜你喜欢





































