编辑:编辑部
【新智元导读】GPT-4 32K还没用上,ChatGPT最强竞品已经秒读「了不起的盖茨比」了。在GPT-4 32K还在内测阶段,OpenAI的劲敌直接把上下文长度打了上去。
就在今天,初创公司Anthropic宣布,Claude已经能够支持100K的上下文token长度,也就是大约75,000个单词。
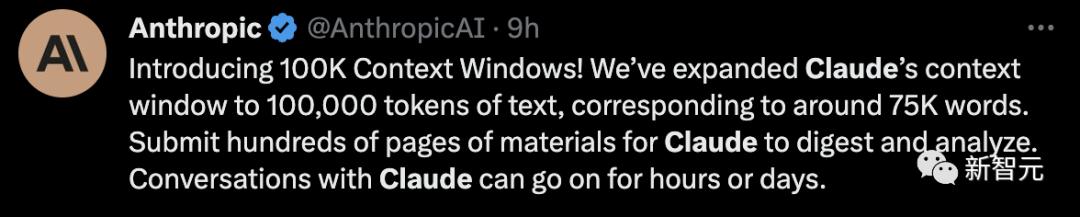
而且,不少GPT-4的用户已经可以在自己的PlayGround上看到GPT-4 32k的选项。
已经解锁这一版本的网友,让其访问了数百个来自卸载HyperWrite用户的数据点,GPT-4便准确地告诉他接下来该做怎样的改进。
他称赞道,GPT-4 32k是世界上最好的产品经理。
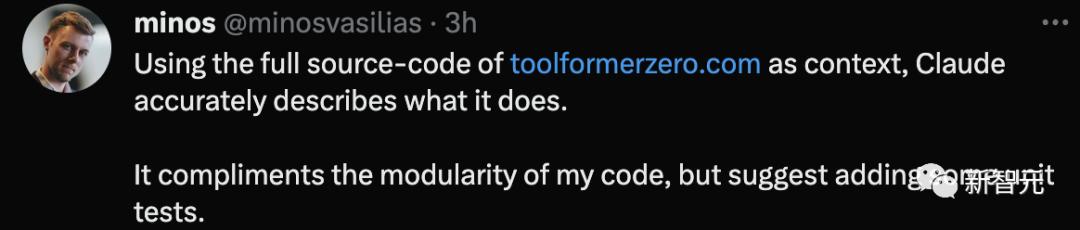
一位网友用100页的「GPT-4技术报告」测试,结果只能用amazing来形容。


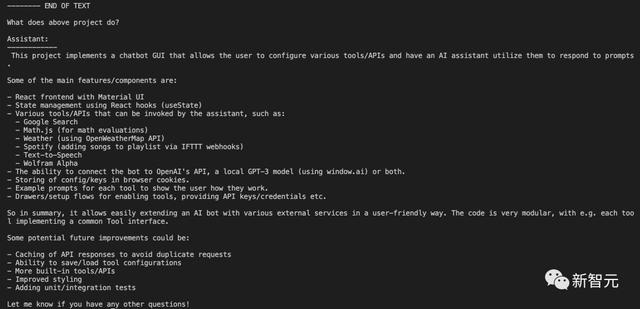
同时,这位网友把自己开发的Toolformer Zero完整源代码丢给它,Claude精准描述出这是用来做什么。
并且,Claude还称赞了代码的模块化,提供增加一些单元测试的建议。
英伟达科学家Jim Fan表示,这是Anthropic抛出的杀手锏。未来在上下文长度的军备赛正快速升温。

其实,不仅是32k,现在100k都实现了,百万token也不远了。
「绝对太野了!几年后,支持100万的token上下文长度会不会成为可能?」

前段时间,来自DeepPavlov、AIRI、伦敦数学科学研究所的研究人员发布了一篇技术报告,使用循环记忆Transformer(RMT)将BERT的有效上下文长度提升到「前所未有的200万tokens」,同时保持了很高的记忆检索准确性。

论文地址:https://arxiv.org/abs/2304.11062
该方法可以存储和处理局部和全局信息,并通过使用循环让信息在输入序列的各segment之间流动。
不过,虽然RMT可以不增加内存消耗,可以扩展到近乎无限的序列长度,但仍然存在RNN中的记忆衰减问题,并且需要更长的推理时间。
实际上,RMT背后是一个全新的记忆机制。
具体操作方法是,在不改变原始Transformer模型的前提下,通过在输入或输出序列中添加一个特殊的memory token,然后对模型进行训练以控制记忆操作和序列表征处理。
与Transformer-XL相比,RMT需要的内存更少,并可以处理更长序列的任务。
当然,在最终实现百万token之前,Claude 100k已经是相当大的起步了。
参考资料:
https://www.anthropic.com/index/100k-context-windows

花粉社群VIP加油站
关于作者

猜你喜欢





































