三月中旬,OpenAI 正式发布了 GPT-4,并向我们展示了其所具备的非凡的多模态能力:基于手写文本指令构建网站、生成详细准确的图像描述、解释丰富有趣的视觉现象……不过,需要说明的是,OpenAI 并未公开任何与 GPT-4 有关的技术细节。
来自沙特阿卜杜拉国王科技大学的研究团队认为,GPT-4 拥有卓越的多模态生成能力的主要原因在于,其使用了更为先进的大型语言模型。并且,为了验证他们提出的这个假设,其还构建了一个新模型,并将其命名为“MiniGPT-4”。
2023 年 4 月 20 日,相关论文以《MiniGPT-4:使用高级大型语言模型增强视觉-语言理解》(MiniGPT-4: Enhancing Vision-language Understanding with Advanced Large Language Models)为题在预印本网站 arXiv 上发表[1]。

图丨MiniGPT-4 的架构(来源:arXiv)
他们起初在 4 个 A100 GPU 上,对该模型进行了第一阶段的传统训练,后来发现简单地对齐视觉模型和语言模型,并不能训练出像聊天机器人这样的、具有视觉对话能力的高性能模型。
与此同时,他们也发现,在对原始的图像-文本进行预训练的过程中,模型所生成的语言输出会缺乏连贯性。为了解决该问题,他们在第二阶段的训练中,构建了一个小型数据库,用 3500 个高质量的、对齐良好的图像-文本对,来提高模型的稳定性和生成语言的可用性。
“在第二阶段,我们只用了 3500 个数据,也只训练了七分钟,效果就有了大幅度提升,这是让我和团队感到很惊喜的一点。”朱德尧表示。
不仅如此,他们还在 MiniGPT-4 中,做了一些 GPT-4 演示中并未展示出的其他有趣能力。例如,MiniGPT-4 可以通过观察植物生病的照片,判断植物的病情并提出解决方案;可以通过观察食物照片,直接生成详细的食谱;可以受图像的启发为产品写广告等等。
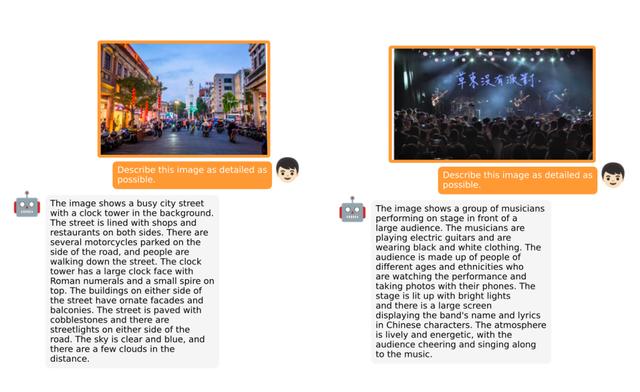
图丨详细图像描述(来源:arXiv)
总地来说,该研究证明了 MiniGPT-4 通过使用预训练的视觉编码器和大型语言模型,得到了很高的计算效率。并且,其能够处理像 GPT-4 演示中所展示出的那些能力。
“现在只要给我们一个比较先进的纯文本式的大型语言模型,就能在 10 小时之内让其‘看见’图片。”朱德尧说。
作为该论文的主要作者,朱德尧和陈军过往的求学经历有些不同。前者本科时所学的专业是机械电子工程,硕士转为电子信息工程,博士阶段才来到阿卜杜拉国王科技大学攻读计算机科学。而后者自本科开始就专注于计算机科学专业,已经在多模态、语言生成模型等方向有了一定积累。
两人相识于阿卜杜拉国王科技大学,均属于埃尔霍西尼助理教授课题组的一员。
谈到为何选择开展这项研究,朱德尧表示:“此前我们曾对多模态相关的大模型做过深入研究,比较了解传统多模态大模型的能力边界。当 OpenAI 公布 GPT-4 的演示时,我们完全被震撼到了,没想到现在已经能做到这个地步,同时又很好奇他们到底是怎么做出来的。”
与此同时,他们又希望在以往研究的基础之上继续向前,让多模态大模型的能力实现进一步突破。上述原因是他们开启这项研究的主要动力。
据了解,该论文在发表后赢得了大量的关注和传播,并收到许多来自行业内外的合作邀约。他们的项目在 GitHub 上 三天内迅速斩获 10000 星。
同时,朱德尧和陈军也将在今年年底迎来博士毕业,因此接下来他们计划基于自己的研究成果,围绕创业、找工作等方向做出选择。
对于是否选择创业,陈军也有自己的看法。 “虽然现在这个领域发展得很快,但还是有很多基础的问题没有解决。我们接下来会在技术上继续耕耘,以后可能会选择一个合适的时机再进行创业。” 他这样说。
参考资料:
1.D., Zhu, J., Chen, X., Shen. et al. MiniGPT-4: Enhancing Vision-language Understanding with Advanced Large Language Models. arXiv:2304.10592.https://doi.org/10.48550/arXiv.2304.10592

花粉社群VIP加油站
关于作者

猜你喜欢





































