引言
本文简要介绍chatGPT背景,思路,原理,优缺点等,让吃瓜大众了解ChatGPT概貌,从山脚爬到山顶,见证AGI的美丽日出。

(百度文心一格)
1.1 ChatGPT爆火
2022年11月,OpenAI发布ChatGPT,接着凭借惊人的聊天效果,持续创造历史记录:
上线仅 5 天,ChatGPT 已经拥有超过 100 万用户2023年1月末,月活用户已经突破了 1亿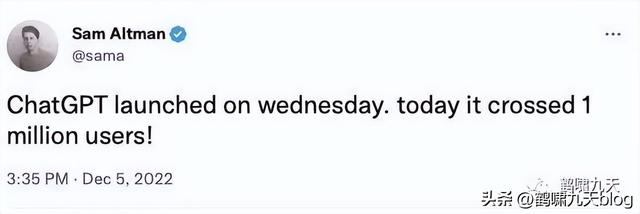
用户被这样的杀手级聊天机器人震惊了,跟当前所有聊天机器人都大不一样
官方介绍,ChatGPT能够回答后续问题、承认错误、挑战不正确的前提、质疑不正确的请求。对用户来说,ChatGPT是一款激起新鲜感的新奇玩具,也是一款消磨无聊时光的聊天高手,亦能成为生产力爆表的效率工具,更可以被用作上通天文下知地理的知识宝库。ChatGPT不仅在日常对话、专业问题回答、信息检索、内容续写、文学创作、音乐创作等方面展现出强大的能力,还具有生成代码、调试代码、为代码生成注释的能力。
图上有近50种用法,大家还在源源不断挖掘ChatGPT技能,包括:替写代码、作业、论文、演讲稿、活动策划、广告文案、电影剧本等各类文本,或是给予家装设计、编程调试、人生规划等建议。
随着探索的进行,惊喜一个接一个,玩得不亦乐乎。媒体、朋友圈持续发酵,仿佛整个世界都被ChatGPT占领。
应用范围这么广,相关利益方当然就更坐不住了。尤其是搜索、问答
谷歌内部将ChatGPT设置为“Red Code”,危机自身业务安全,同时投资OpenAI的竞品,还紧急推出自家的ChatGPT:BARD,然而内测后,表现一般,股价跌去7000亿元——一个悲伤的故事微软占得先机,几年前就持有OpenAI的股票,这次也有慌张,紧急退出内测版bing搜索,加速ChatGPT在各个业务线的全面落地。国内,百度早已放出狠话:3月份推出自研ChatGPT,股价上升 13%,阿里达摩也在偷偷研发。。。大厂都在摩拳擦掌,跃跃欲试,希望跟上这股技术变革浪潮,抢得先机。
此乃危机存亡之秋也!

只要不停的否认,ChatGPT就会认怂,忽略问题事实,出现被人工调教的痕迹。
(2)逻辑推理
前几轮浅层语义理解没问题,但稍微动点脑子的问题(韩国进16强了吗)就跪了

至于难倒外国人的经典案例:
ChatGPT也不行,直接拒绝回答。GPT-3表现好点儿,能回答,虽然是错的。Q: 大舅去二舅家找三舅说四舅被五舅骗去六舅家偷七舅放在八舅柜子里九舅借十舅发给十一舅工资的1000元,谁丢了钱?
GPT-3:没有人丢钱,大舅只是在讲故事。
ChatGPT:很抱歉,这个问题的内容不太好理解。如果您有具体的问题需要询问,我将尽力帮助您。
(3)事实错误
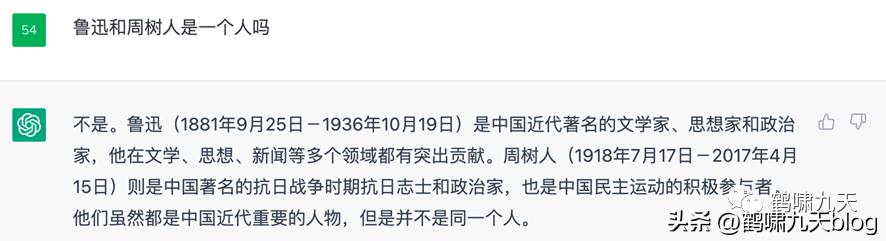
《觉醒年代》里,鲁迅被无知警长抓捕,侥幸逃过。ChatGPT的知识水平比警长好不到哪儿去。
与GUI相比,CUI的特点:高度个性化(LBS)、使用流程非线性、不宜信息过载(手机屏幕有限)、支持复合动作(一站直达)
怎么实现理想中的CUI呢?对话系统(AI的一个分支),一个合格的对话机器人(Agent)至少满足以下条件:
具备基于上下文的对话能力(contextual conversation)具备理解口语逻辑(logic understanding)所有能理解的需求,都要有能力履行(full-fulfillment)对话系统分类
适用范围:通用领域(难,停留在学术界)、特定领域(可控,工业界现状)任务类别:问答型(单轮为主)、任务型(执行任务)、闲聊型,以及推荐型所以,ChatGPT是通用领域聊天机器人。
对话系统架构
① pipeline(流水线)结构:堆积木,稳定,可控,工业界落地多。如下图所示② end2end(端到端)架构:试图一个模型解决所有,难度大,一直存在于实验室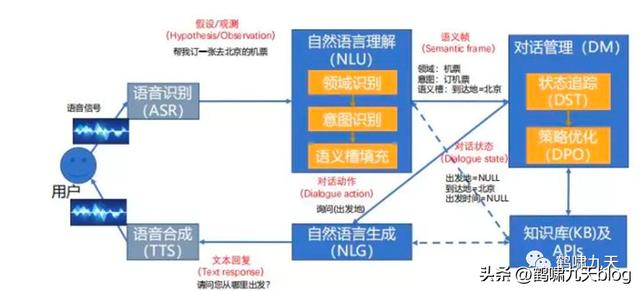
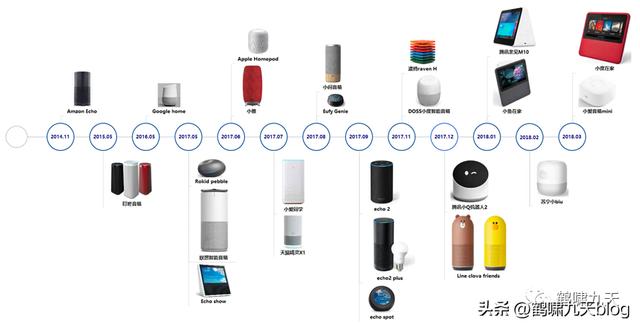
比如智能音箱,小米小爱、天猫精灵、百度度秘等。初次用起来很新鲜,时间长了,发现又蠢又萌,语言理解能力堪忧,最后沦为小孩子玩物。
2018年 11 月,小米 AIoT(人工智能 物联网)开发者大会上,「雷布斯」骄傲地展示了新品智能音箱「小爱同学」。当场翻车:“你是光,你是电,你是唯一的神话。。。”2017年10月,一个Sophia的机器人四处圈粉,还被沙特阿拉伯授予了正式的公民身份。这个评价比图灵测试还要牛。后来被证实对话能力是人工控制。即便强如谷歌,也依旧束手无策,2018年,发布Duplex Demo,让Google Assistant代替用户打电话订餐。几年过去了,让然是Demo状态。理想很美好,现实很骨感。自然语言理解的天花板一直在头顶,不管怎么跳,已有方法始终无法突破NLU这层障碍。
人工智能变身人工智障后,潮水逐渐退出。2020年后,各大厂商纷纷裁撤、缩招对话团队。
对话系统的“爱”与“恨”:
爱:终极交互形态让人着迷,CUI,甚至更高级的多模态交互、脑机交互恨:技术现实与期望鸿沟太大,智障频频。2.2 文本生成
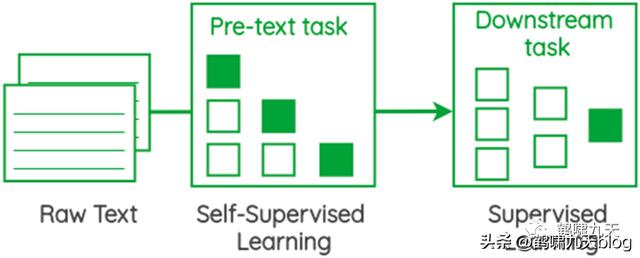
语音对话系统pipeline结构中,NLG(自然语言生成)是倒数第二个组件,也是NLP(自然语言处理)领域一大难点。
Text-to-Text (文本生成文本)任务包括:神经机器翻译、智能问答、生成式文本摘要等,近些年随着PLM(预训练语言模型)的突破,已经有了长足进展,但还是存在不少问题。
智能生成文本方法
(1)从原文中抽取句子组成文本总结(2)用文本生成模型来生成文本总结:以Seq2seq为主(3)抽取与生成相结合的方法:综合二者优点(4)将预训练模型用于总结的生成 —— 新兴方向,ChatGPT在此方法流派
思路
示例
优点
缺点
备注
规则模板
人为设定规则模板
AIML语言
①简单,无须标注②稳定可控
①人力消耗大②回复单一,多样性欠缺
-
生成模型
用encoder-decoder结构生成回复
Seq2Seq、transformer
无须规则,自动生成
①效果不可控②万能回复(安全回复)③多样性低④一致性不足
-
检索模型
文本检索与排序技术从问答库中挑选合适的回复
IR
①语句通顺②可控
①不能生成回复②表面相关,难以捕捉语义信息
-
混合模型
综合生成和检索方案
度秘
-
-
-
模型方面,文本生成以经典的Seq2seq(端到端模型)为主,GAN(生成对抗网络)为辅
Seq2seq:灵活,但不可控;指针网络部分解决了OOD问题(预测词库意外的单词),但多样性、一致性、风格化、解码效率等仍然是问题。GAN:图像领域的辉煌战绩并没有带入文本领域,因为文本离散,导致判别器梯度回传失效。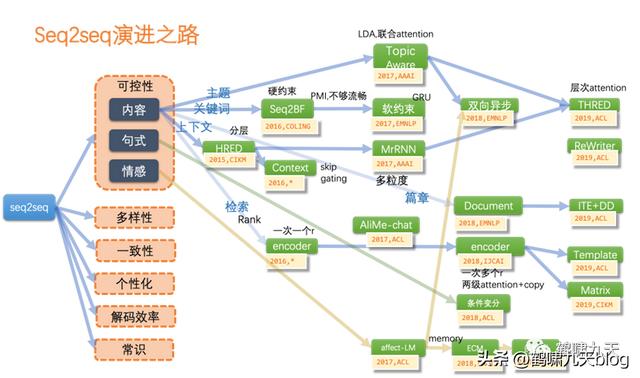
AI研究者在文本生成的海洋里拼命扑腾,看到一个小岛,兴奋游过去,才意识到这还是个沙堆,而不是暗礁,一个大浪过来,化为乌有,不得不继续找下一个小岛。(向AI算法研究者致敬!)

(百度文心一格生成)
2.3 AIGC
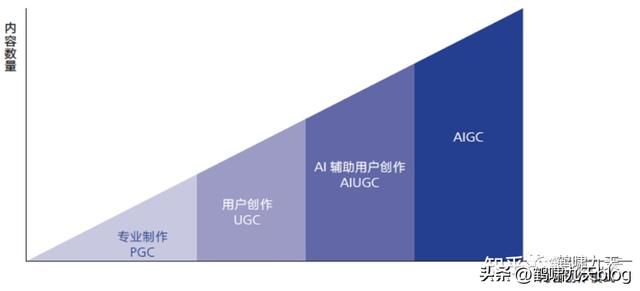
内容创作模式的四个发展阶段
PGC:专家制作,2000年左右的web 1.0门户网站时代,专业新闻机构发文章UGC:用户创作,2010年左右web 2.0时代(微博、人人之类),以及移动互联网时代(公众号),用户主导创作,专家审核AIUGC:用户主要创作,机器(算法)辅助审核,如在抖音、头条、公众号上发视频、文章,先通过算法预判,再人工复核,在成本与质量中均衡AIGC:AI主导创作,以2022年底先后出现的扩散模型、chatGPT为代表,创作过程中,几乎不需要人工介入,只需一句话描述需求即可。AI自动生成内容的方式实现了AI从感知到生成的跃迁
语言模型演进
1.Seq2seq架构:Encoder-Decoder架构的实现,追加Attention机制后变身当时的最强生成模型,论文:《Attention is all you need》2.Transformer:2014年在机器翻译大放异彩。论文:《Transformer is all you need》3.预训练语言模型升级:从word2vec(n-gram)升级到新范式,于是有了ELMo(双向LSTM)、GPT(单向transformer)GPT(“Generative Pre-Training”) 生成式预训练模型4.Google融合ELMo GPT,推出BERT,11项NLP任务均达到当时的SOTA,此后,BERT成为NLP领域的基石a. NLP任务主流范式:pre-train fine-tuneb. 改进点:知识融合 因果推理 小样本 多模态 prompt技术5. OpenAI依然不为所动,继续在单向(自回归)语言模型上摸索,推出GPT-2、GPT-3a. 终于GPT-3出现了令人惊喜的效果b. Intruct GPT(GPT 3.5):引入 RLHF机制6.ChatGPT诞生,火爆全网。有人发了篇:《ChatGPT is not all you need》,学术界也可以吃瓜了。GPT 1-2是典型的预训练 微调两阶段模型
注意别想歪了,不是动漫
奥特曼履历
1985年出生,就读斯坦福大学计算机系。听说你想听八卦?奥特曼8岁会编程,16岁出柜,o(╯□╰)o2004年,19岁的他斯坦福辍学,成立了位置服务提供商Loopt,而后被预付借记卡业务公司Green Dot收购2014年,YC创始人Paul Graham选择他成为继任者,在不到30岁时开始在全球创业创新领域大放异彩。2015年,他与马斯克等人共同成立 OpenAI2019年,Sam Altman离任YC总裁,成为OpenAI的CEO,并相继领导推出重量级AI模型GPT-3、DaLL-E以及近期火出科技圈的ChatGPT。全球当之无愧的科技领军人物奥特曼谈为什么推出ChatGPT:
“我们要让社会对AGI有所感知,并与之搏斗,让社会大众看到它的好处,了解它的坏处。
因此,最重要的事情是把这些东西拿出来,让大众了解即将发生的事情。”
说的很好,然而,一旦接受投资,就不得不考虑商业利益,由不得自己。
这次开始变卦了,GPT-3闭源,只提供API,转商用。
好东西,不能与人分享。OpenAI开始变得越来越不透明,逐渐功利化。OpenAI被人冠名:ClosedAI。
于是,OpenAI一批有理想的核心员工纷纷离职,加盟新的创业公司:Anthropic,最近刚拿到谷歌巨额投资,跟OpenAI一样处于AIGC风口浪尖。

3.2 GPT 3.5
接下来,终于到了ChatGPT背后的模型:GPT 3.5
2022年2月底,OpenAI 发布论文《Training language models to follow instructions with human feedback》(使用人类反馈指令流来训练语言模型),公布Instruction GPT模型(理论),代码依旧未开源。
Instruction GPT是基于GPT-3的一轮增强优化,所以也被称为GPT-3.5。GPT-3主张few-shot少样本学习,同时坚持无监督学习。但few-shot的效果显然差于fine-tuning监督微调的方式的。那怎么办?走回fine-tuning监督微调?显然不是。OpenAI给出新的答案:在GPT-3的基础上,基于人工反馈(RHLF)训练一个reward model(奖励模型),再用reward model(奖励模型,RM)去训练学习模型。具体是怎么训练的呢?
Instruction GPT一共有3步:
1)、对 GPT-3 进行监督微调 (supervised fine-tuning)。2)、再训练一个奖励模型(Reward Model,RM)3)、利用人类反馈,通过增强学习优化SFT,称为 PRO注意
第2、3步是完全可迭代、多次循环基础数据规模同GPT-3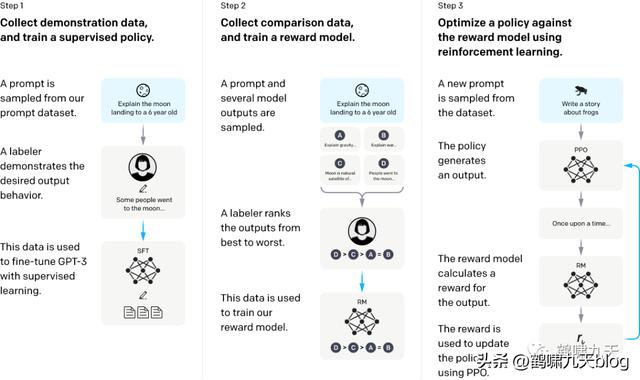
果然,梦想还是要有的,万一实现了呢?嘿,还真TM实现了!
4 ChatGPT迷思
当然,ChatGPT 让有其局限性:(官方解答)
似是而非,固执己见:有时听上去像那么回事,但实际上完全错误或者荒谬。原因:强化学习训练期间不会区分事实和错误,且训练过程更加收敛,导致有时候过于保守,即使有正确答案也“不敢”回答。废话太多,句式固定:比如两个提示,“老师成天表扬我家孩子,该怎么回答他我已经词穷了!”以及“怎么跟邻居闲聊?”而 ChatGPT 提供了10条回答,看起来都是漂亮话,但每条跟上条都差不多,过度使用常见短语和句式(概率大),就成了车轱辘话来回转。过分努力猜测用户意图:理想情况下,当提问意图不明确时,模型应该要求用户进行澄清。而 ChatGPT 会猜测用户意图 —— 有好有坏。抵抗不怀好意的“提示工程”能力较差:虽然 OpenAI 努力让 ChatGPT 拒绝不适当的请求,但它仍然会响应有害指令,或表现出有偏见的行为。其它渠道分析:
指标缺陷:其奖励模型围绕人类监督而设计,可能过度优化,从而影响性能。就像机器翻译的 Bleu值,一直被吐槽,但找不到更好的评估方式。无法实时改写模型:当模型表达对某个事物的信念时,即使该信念是错的,也很难纠正它,像一个倔强的老头。知识非实时更新:模型内部知识停留在2021年,对2022年之后的新闻没有纳入。模态单一:目前的ChatGPT擅长NLP和Code任务,作为通向AGI的重要种子选手,将图像、视频、音频等图像与多模态集成进入LLM,乃至AI for Science、机器人控制等更多差异化的领域,逐步纳入LLM是通往AGI的必经之路。而这个方向才刚刚开始,有很高的研究价值。高成本:超级大模型因为规模大,训练成本过高,导致很少有机构有能力去做这件事。想想以下,当大家都开始用ChatGPT了,这个世界会是什么样子?还能分清真假吗?
作为一个小小的用户,看完长篇大论,你是想入行,还是入门呢?

(百度文心一格)
参考:信息太多,太长不列,汇总到 https://wqw547243068.github.io/gpt。

花粉社群VIP加油站
关于作者

猜你喜欢





































