Prompt-Tuning起源于GPT-3的提出《Language Models are Few-Shot Learners》(NIPS2020),其认为超大规模的模型只要配合好合适的模板就可以极大化地发挥其推理和理解能力。其开创性提出in-context learning概念,即无须修改模型即可实现few-shot/zero-shot learning。同时引入了demonstrate learning,即让模型知道与标签相似的语义描述,提升推理能力。今天就来简单了解一下吧!

不过以GPT-3为首的这类方法有一个明显的缺陷是—— 其建立在超大规模的预训练语言模型上 ,此时的模型参数数量通常超过100亿, 在真实场景中很难应用 ,因此众多研究者开始探索GPT-3的这套思路在小规模的语言模型(BERT)上还是否适用?
事实上,这套方法在小规模的语言模型上是可行的,但是需要注意几点:
1、模型参数规模小了,Prompt直接用在Zero-shot上效果会下降,因此需要考虑将in-context learning和demonstrate learning应用在Fine-tuning阶段;
2、GPT-3中提供的提示(Natural Language Prompt)过于简单,并不难使用在一些具体的任务场景,因此需要单独设计一套组件实现。
因此,大名鼎鼎的PET模型问世,PET(Pattern-Exploiting Training)出自《Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference》,根据论文题目则可以猜出,Prompt-Tuning启发于文本分类任务,并且试图将所有的分类任务转换为与MLM一致的完形填空。
因此基于PVP的训练目标可以形式化描述:给定一个句子 ,以及对应的标签 ,给定定义的PVP组件 ,则有:
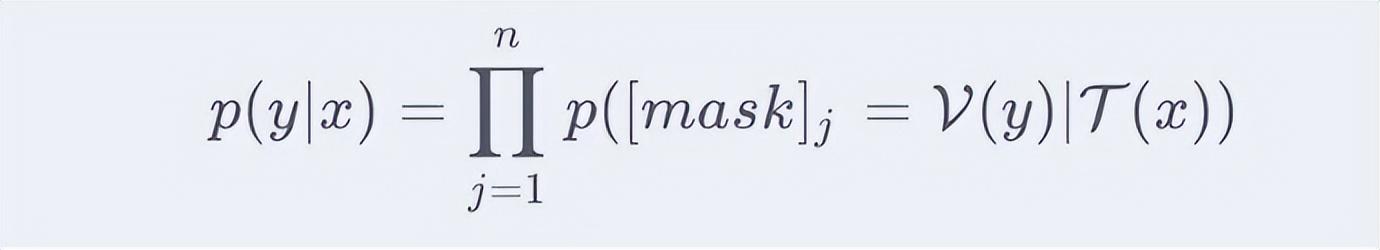
iPET旨在先从预训练模型开始,初始化多个不同的模型,在有标注的少量样本上进行Prompt-Tuning,然后通过多个不同的PVP训练得到多个不同的模型,每个模型在无标注数据上进行推理打标,并根据置信度筛选,根据新标注的数据与原始标注数据融合后,再重新进行Prompt-Tuning,重复abc三个步骤多次后,获得每个模型后,在测试时进行集成投票。
因此可以说,PET提供Prompt-Tuning比较成熟的框架。

花粉社群VIP加油站
关于作者

猜你喜欢





































