机器之心报道
机器之心编辑部
为什么仿佛一夜之间,自然语言处理(NLP)领域就突然突飞猛进,摸到了通用人工智能的门槛?如今的大语言模型(LLM)发展到了什么程度?未来短时间内,AGI 的发展路线又将如何?
自 20 世纪 50 年代图灵测试提出以来,人们始终在探索机器处理语言智能的能力。语言本质上是一个错综复杂的人类表达系统,受到语法规则的约束。因此,开发能够理解和精通语言的强大 AI 算法面临着巨大挑战。过去二十年,语言建模方法被广泛用于语言理解和生成,包括统计语言模型和神经语言模型。
近些年,研究人员通过在大规模语料库上预训练 Transformer 模型产生了预训练语言模型(PLMs),并在解决各类 NLP 任务上展现出了强大的能力。并且研究人员发现模型缩放可以带来性能提升,因此他们通过将模型规模增大进一步研究缩放的效果。有趣的是,当参数规模超过一定水平时,这个更大的语言模型实现了显著的性能提升,并出现了小模型中不存在的能力,比如上下文学习。为了区别于 PLM,这类模型被称为大型语言模型(LLMs)。
从 2019 年的谷歌 T5 到 OpenAI GPT 系列,参数量爆炸的大模型不断涌现。可以说,LLMs 的研究在学界和业界都得到了很大的推进,尤其去年 11 月底对话大模型 ChatGPT 的出现更是引起了社会各界的广泛关注。LLMs 的技术进展对整个 AI 社区产生了重要影响,并将彻底改变人们开发和使用 AI 算法的方式。
考虑到 LLMs 的快速技术进步,中国人民大学的二十几位研究者通过背景知识、关键发现和主流技术等三方面回顾了 LLMs 的最新进展,尤其关注 LLMs 的预训练、自适应调优、使用和能力评估。此外他们还总结和开发 LLMs 的可用资源,讨论了未来发展方向等问题。对于领域内研究人员和工程师而言,这份综述是一份极其有用的学习资源。

论文链接:https://arxiv.org/abs/2303.18223
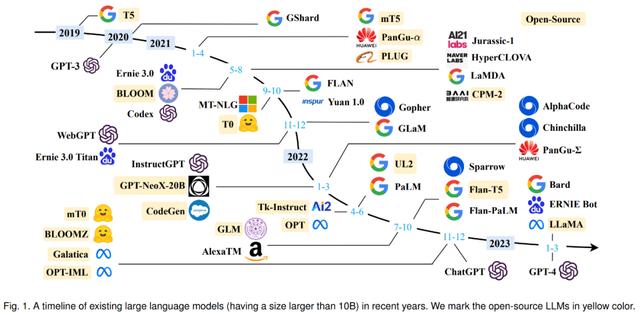
在进入正文前,我们先来看 2019 年以来出现的各种大语言模型(百亿参数以上)时间轴,其中标黄的大模型已开源。
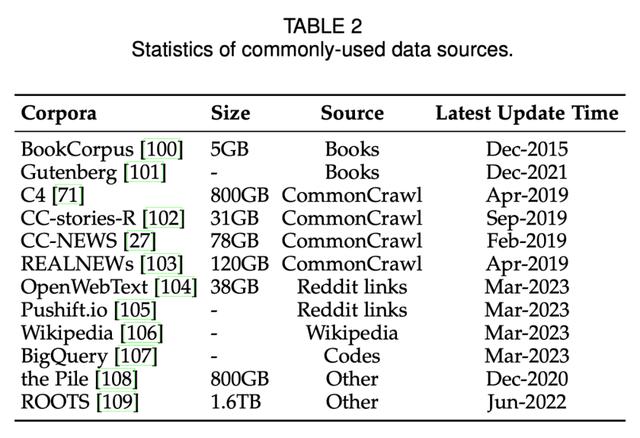
下表 2 列出了常用的数据源。
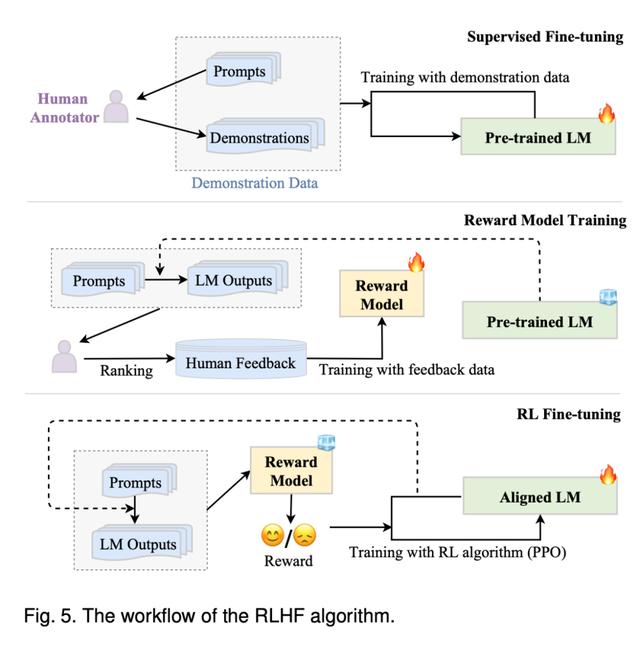
对齐调优
这部分首先介绍了对齐的背景及其定义和标准,然后重点介绍了用于对齐 LLMs 的人类反馈数据的收集,最后讨论了用于对齐调整的人类反馈强化学习的关键技术。
作为一种特殊的 prompt 形式,上下文学习(ICL)是 GPT-3 首次提出的,它已经成为利用 LLMs 的一种典型方法。
思维链 prompt
思维链(CoT)是一种改进的 prompt 策略,可以提高 LLM 在复杂推理任务中的表现,如算术推理、常识推理和符号推理。CoT 不是像 ICL 那样简单地用输入 - 输出对来构建 prompt,而是将能够导致最终输出的中间推理步骤纳入 prompt。在第 6.2 节中,研究者详细说明了 CoT 与 ICL 的用法,并讨论 CoT 何时有效以及为何有效。
能力评估
为了研究 LLMs 的有效性和优越性,研究者利用了大量的任务和基准来进行实证评估和分析。第七节首先介绍了三种用于语言生成和理解的 LLMs 的基本评估任务,然后介绍几种具有更复杂设置或目标的 LLMs 的高级任务,最后讨论了现有的基准和实证分析。
基本评估任务

图 7:一个公开 LLM 的内在和外在幻觉的例子(访问日期:2023 年 3 月 19 日)。作为内在幻觉的例子,LLM 对 Cindy 和 Amy 之间的关系给出了一个与输入相矛盾的判断。对于外在幻觉,在这个例子中,LLM 似乎对 RLHF(从人类反馈中强化学习)的含义有不正确的理解,尽管它能正确理解 LLM 的含义。
高级任务评估
除了上述基本评估任务,LLMs 还表现出一些高级能力,需要特别评估。在第 7.2 节中,研究者讨论了几个有代表性的高级能力和相应的评价方法,包括人工对齐、与外部环境的交互以及工具的操作。
总结与未来方向
在最后一节中,研究者总结了这次调查的讨论,并从以下几个方面介绍了 LLMs 的挑战和未来发展方向。
理论和原理:为了理解 LLM 的基本工作机制,最大的谜团之一是信息如何通过非常大的深度神经网络进行分配、组织和利用。揭示建立 LLMs 能力基础的基本原则或元素是很重要的。特别是,缩放似乎在提高 LLMs 的能力方面发挥了重要作用。已有研究表明,当语言模型的参数规模增加到一个临界点(如 10B)时,一些新兴能力会以一种意想不到的方式出现(性能的突然飞跃),典型的包括上下文学习、指令跟随和分步推理。这些「涌现」的能力令人着迷,但也令人困惑:LLMs 何时以及如何获得这些能力?最近的一些研究要么是进行广泛的体验,调查新兴能力的效果和这些能力的促成因素,要么是用现有的理论框架解释一些特定的能力。一个有见地的技术帖子将 GPT 系列模型作为目标也专门讨论了这个话题,然而仍然缺少更正式的理论和原则来理解、描述和解释 LLM 的能力或行为。由于涌现能力与自然界中的相变有着密切的相似性,跨学科的理论或原则(例如 LLMs 是否可以被视为某种复杂系统)可能对解释和理解 LLMs 的行为有帮助。这些基本问题值得研究界探索,对于开发下一代的 LLMs 很重要。
模型架构:由于可扩展性和有效性,由堆叠的多头自注意力层组成的 Transformer 已经成为构建 LLMs 的普遍架构。人们提出了各种策略来提高这个架构的性能,如神经网络配置和可扩展的并行训练(见 4.2.2 节讨论)。为了进一步提高模型的容量(如多轮对话能力),现有的 LLMs 通常保持较长的上下文长度,例如,GPT-4-32k 具有 32768 个 token 的超大上下文长度。因此,一个实际的考虑是减少标准的自注意力机制所产生的时间复杂性(原始的二次成本)。
此外,研究更高效的 Transformer 变体对构建 LLMs 的影响是很重要的,例如稀疏注意力已经被用于 GPT-3。灾难性遗忘也一直是神经网络的挑战,这也对 LLMs 产生了负面影响。当用新的数据调整 LLMs 时,原先学到的知识很可能被破坏,例如根据一些特定的任务对 LLMs 进行微调会影响它们的通用能力。当 LLMs 与人类的价值观相一致时,也会出现类似的情况,这被称为对齐税(alignment tax)。因此有必要考虑用更灵活的机制或模块来扩展现有的架构,以有效支持数据更新和任务专业化。
模型训练:在实践中,由于巨大的计算量以及对数据质量和训练技巧的敏感性,预训练可用的 LLMs 非常困难。因此,考虑到模型有效性、效率优化和训练稳定性等因素,开发更系统、更经济的预训练方法来优化 LLMs 变得尤为重要。开发更多的模型检查或性能诊断方法(例如 GPT-4 中的可预测缩放),便于在训练中发现早期的异常问题。此外,它还要求有更灵活的硬件支持或资源调度机制,以便更好地组织和利用计算集群中的资源。由于从头开始预训练 LLMs 的成本很高,因此必须设计一个合适的机制,根据公开的模型检查点(例如 LLaMA 和 Flan-T5)不断地预训练或微调 LLMs。为此,必须解决一些技术问题,包括数据不一致、灾难性遗忘和任务专业化。到目前为止,仍然缺乏具有完整的预处理和训练日志(例如准备预训练数据的脚本)的开源模型检查点以供重现的 LLM。为 LLMs 的研究提供更多的开源模型将是非常有价值的。此外,开发更多的改进调整策略和研究有效激发模型能力的机制也很重要。
模型的使用:由于微调在实际应用中的成本很高,prompt 已经成为使用 LLMs 的突出方法。通过将任务描述和演示例子结合到 prompt 中,上下文学习(prompt 的一种特殊形式)赋予了 LLMs 在新任务上良好的表现,甚至在某些情况下超过了全数据微调模型。此外,为了提高复杂推理的能力,人们提出了先进的 prompt 技术,例如思维链(CoT)策略,它将中间的推理步骤纳入 prompt。然而,现有的 prompt 方法仍然有以下几个不足之处。首先,它在设计 prompt 时需要大量的人力,因此为解决各种任务而自动生成有效的 prompt 将非常有用;其次,一些复杂的任务(如形式证明和数字计算)需要特定的知识或逻辑规则,而这些知识或规则可能无法用自然语言描述或用例子来证明,因此开发信息量更大、更灵活的任务格式化的 prompt 方法很重要;第三,现有的 prompt 策略主要集中在单圈的表现上,因此开发用于解决复杂任务的交互式 prompt 机制(如通过自然语言对话)非常有用,ChatGPT 已经证明了这一点。
安全和对齐:尽管 LLMs 具备相当的能力,但它的安全问题与小型语言模型相似。例如,LLMs 表现出产生幻觉文本的倾向,比如那些看似合理但可能与事实不符的文本。更糟糕的是,LLMs 可能被有意的指令激发,为恶意的系统产生有害的、有偏见的或有毒的文本,导致滥用的潜在风险。要详细讨论 LLMs 的其他安全问题(如隐私、过度依赖、虚假信息和影响操作),读者可以参考 GPT-3/4 技术报告。作为避免这些问题的主要方法,来自人类反馈的强化学习(RLHF)已被广泛使用,它将人类纳入训练循环,以发展良好的 LLMs。为了提高模型的安全性,在 RLHF 过程中加入安全相关的 prompt 也很重要,如 GPT-4 所示。然而,RLHF 在很大程度上依赖于专业标签人员的高质量的人类反馈数据,使得它很难在实践中得到正确的实施。因此,有必要改进 RLHF 框架,以减少人类标签员的工作,并寻求一种更有效的注释方法,保证数据质量,例如可以采用 LLMs 来协助标注工作。最近,红色团队被采用来提高 LLMs 的模型安全性,它利用收集的对抗性 prompt 来完善 LLMs(即避免红色团队的攻击)。此外,通过与人类交流建立 LLMs 的学习机制也很有意义,人类通过聊天给出的反馈可以直接被 LLMs 利用来进行自我完善。
应用和生态系统:由于 LLMs 在解决各种任务方面表现出强大的能力,它们可以被应用于广泛的现实世界的应用(例如,遵循特定的自然语言指令)。作为一个显著的进步,ChatGPT 已经潜在地改变了人类获取信息的方式,这带来了新必应的发布。在不久的将来,可以预见,LLMs 将对信息搜索技术产生重大影响,包括搜索引擎和识别系统。
此外,随着 LLMs 的技术升级,智能信息助理的发展和使用将得到极大的促进。在更广泛的范围内,这一波技术创新倾向于建立一个由 LLMs 授权的应用程序的生态系统(例如,ChatGPT 对插件的支持),这将与人类生活密切相关。最后,LLMs 的崛起为通用人工智能(AGI)的探索提供了启示。它有希望开发出比以往更多的智能系统(可能有多模态信号)。同时,在这个发展过程中,人工智能的安全性应该是首要关注的问题之一,也就是说,让人工智能为人类带来好处而不是坏处。

花粉社群VIP加油站
关于作者

猜你喜欢





































