1894年,一位名叫珀西维尔·洛厄尔(Percivel Lowell)的波士顿天文学家在火星上发现了智慧生命。
通过私人天文台的望远镜,他观察到火星表面有黑色的直线。他认为这些线路是一个先进但挣扎的外星文明试图从极地冰盖中自来水的证据。
他花了数年时间绘制这些线条的复杂图画,他的发现引起了当时公众的想象力。但你从来没有听说过他,因为他被证明是大错特错的。
在1960年代,美国宇航局的水手任务捕获了火星的高分辨率图像,揭示了这些“运河”只不过是由火星表面陨石坑分布引起的视错觉。由于当时他的望远镜分辨率很低,这些陨石坑在洛厄尔看来就像直线一样,通过一系列推理,他推测这是由智慧生命建造的运河。
洛厄尔的故事表明,思维至少有两个重要的组成部分:推理和知识。没有推理的知识是惰性的——你不能用它做任何事情。但是,没有知识的推理可以变成令人信服的、自信的捏造。
有趣的是,这种二分法并不局限于人类认知。这也是人们从根本上错过人工智能的一个关键因素:
尽管我们的人工智能模型是通过阅读整个互联网来训练的,但这种训练主要增强了它的推理能力——而不是它知道多少。因此,当今人工智能的性能受到缺乏知识的限制。
上周,我看到Sam Altman在旧金山的一个小型红杉活动中发言,他强调了这一点:GPT模型实际上是推理引擎,而不是知识数据库。
理解这一点至关重要,因为它预测人工智能有用性的进步将来自其在正确的时间获取正确知识的能力的进步,而不仅仅是推理能力的进步。
GPT 模型中的知识和推理这里有一个例子来说明这一点。GPT-4 是当今市场上最先进的型号。它的推理能力非常好,可以在AP Bio考试中获得5分。但是如果我问它我是谁,它会说以下内容:
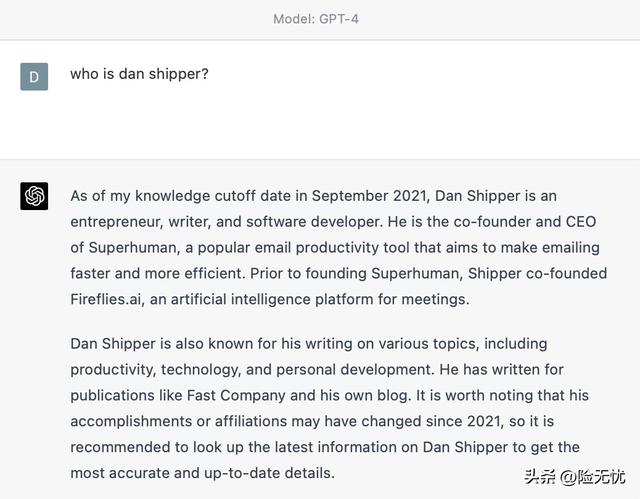
这几乎是对的,除了一个大问题......我是几家公司的联合创始人,但他们都不是Superhuman或Reify。
人工智能批评者很快就会说,这证明了GPT-4只不过是一只随机鹦鹉,它的结果应该被立即驳回。但他们错了。当它能够访问正确的信息时,它的性能就会显著提高。
例如,我可以访问一个版本的 ChatGPT,该版本可以使用网络搜索将其答案与它在互联网上找到的内容联系起来。
换句话说,它不是利用其推理能力来提出理论上合理的答案,而是进行网络研究以为自己创建知识库。然后,它会分析收集到的信息并提炼出更准确的答案:
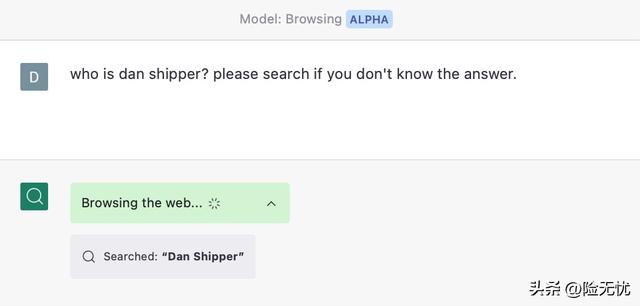
现在,这很好!基础模型是相同的,但答案显着提高,因为它具有正确的信息来推理。
这是怎么回事?GPT-4 的架构不是公开的,但我们可以根据以前发布的模型做出一些有根据的猜测。
当 GPT-4 被训练时,它被喂食了互联网上的大部分可用材料。训练将这些数据转换为一个统计模型,该模型非常擅长,给定一串单词,知道哪些单词应该从中跟随 - 这称为下一个令牌预测。
然而,这个统计模型所包含的那种“知识”是模糊和莫名其妙的。该模型没有任何长期记忆或方法来查找它所看到的信息——它只以统计模型的形式记住它在训练集中遇到的东西。
当它遇到我的名字时,它使用这个模型来对我是谁进行有根据的猜测。它得出的结论大致是正确的,但在细节上是完全错误的,因为它没有任何明确的方式来查找答案。
但是当 GPT-4 连接到互联网(或任何类似数据库的东西)时,它不必依赖其模糊的统计理解。相反,它可以检索明确的事实,例如“Dan Shipper是Every的联合创始人”,并使用它来创建答案。
那么,这对未来意味着什么?我认为至少有两个有趣的结论:
知识数据库对人工智能进步的重要性与基础模型一样重要组织、存储和编目自己的思维和阅读的人将在人工智能驱动的世界中占有一席之地。他们可以将这些资源提供给模型,并使用它来增强其响应的智能和相关性。让我们一次拿一个。
知识数据库的重要性令人惊讶当涉及到知识时,您希望能够存储大量知识,并且希望能够在正确的时间找到正确的知识。在人工智能中,这通常是通过矢量数据库完成的。
矢量数据库允许您轻松索引和存储大量信息,然后在需要时快速查询要提供给模型的类似信息片段。它们在 AI 应用程序中非常常见,以至于您在过去几个月中尝试的几乎每个演示都包含其某些部分功能的矢量数据库。
事实上,如果你想进行一项投资,将整个人工智能公司的成功指数化,一个明智的举动是投资一个矢量数据库提供商,或者一篮子。(替代方案可能是投资OpenAI,或者像微软和谷歌这样构建AI的一篮子大型软件公司,或者像NVIDIA这样的芯片制造商来构建AI运行的GPU。
比我更聪明的投资者似乎同意这一点。最受欢迎的矢量数据库Pinecone刚刚以700亿美元的估值筹集了资金。像Weaviate和Chroma这样的小型替代品也不甘落后,据报道,他们也在以高估值筹集资金。
有趣的是,这些矢量数据库中的大多数最初都是在大型语言模型(LLM)热潮之前建立的。向量对于各种上一代机器学习算法(如推荐系统)非常重要。因此,像Pinecone这样的提供商提供的数据库工具并不是专门为像ChatGPT这样的大型语言模型而构建的。
我们已经看到新的替代方案如雨后春笋般涌现,它们将一些业务逻辑包裹在数据库层周围,使AI开发人员更容易完成常见任务。其中一些是开发人员库,如Langchain和LlamaIndex。有些似乎是功能更齐全的开发人员工具,如Metal和Baseplate。就像松果一样,也有可能筹集到很多钱或已经有了!人工智能的进步是一场雨舞,从穿着天使的巴塔哥尼亚背心中召唤出资本。
我觉得这非常令人兴奋,因为它将使制作AI应用程序变得更加容易。有大量的样板代码被编写来获取,比如,一个PDF或一个网页,上面有有趣的信息,解析它,把它分解成块,存储它,并检索它以用于人工智能应用程序。只需一两行代码就可以发生的越多越好。
当我和人们谈论矢量数据库时——即使是那些一直密切关注人工智能的人——他们通常会说,“那是什么?我认为,随着时间的推移,随着我们开始了解这些模型获得它们所包含的知识的重要性,这种情况将发生重大变化。
矢量数据库是信息存储和提供给 AI 应用程序的方式。我认为他们会从中获得大量有价值的信息的一个地方是私人的个人知识库。
私人知识库将非常有价值长期以来,人们一直在说数据是新的石油。但我确实认为,在这种情况下,如果你花了很多时间收集和策划你自己的笔记、文章、书籍和亮点,这相当于在欧佩克危机期间在你的卧室里放了一个加满油桶。
为什么?查找与您所考虑的事物相关的信息既昂贵又耗时。即使你让人工智能访问搜索引擎,这样它就可以进行查询以找到正确的信息——这也会花费你的金钱和时间。
相反,如果你花了一辈子的时间收集和整理对你很重要的信息,你可以自定义你的人工智能体验,这样它对你更有用。
像Readwise Reader或Pocket或Instapaper这样的应用程序,允许你存储你读过的文章(或你想读的文章),它们将成为一座金矿,因为它们与人工智能工具挂钩。它们将非常有用,因为它们记录了您明确添加书签和阅读的文章,这将使人工智能工具更容易知道在他们的回复中要权衡哪些信息。
但是个人知识数据库的使用将变得比这更奇怪和更先进。
例如,倒带是一个位于计算机上的工具,可以记录您看到的所有内容以及键入的所有内容。出于隐私目的,它都存储在本地,您已经可以将其连接到 ChatGPT。
在他们的一个演示中,他们展示了一个用户问:“我上周做了什么?AI能够总结他们在计算机上完成的所有任务:
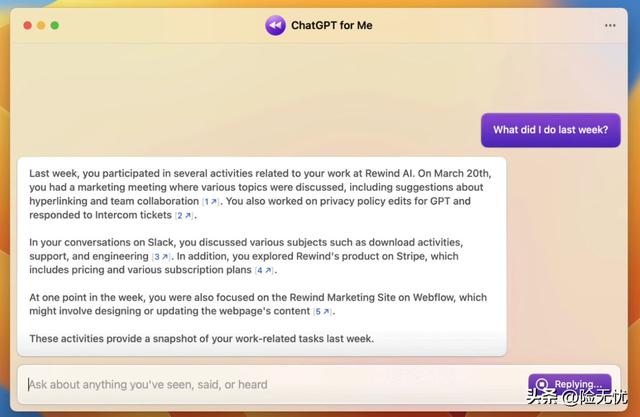
就我而言,我已经安装了Rewind,并且我一直在尝试构建一些小工具来保存我在网上遇到的更多内容。我做了一个我称之为Tend的小应用程序,它整天在我的浏览器上打开,我可以向它提供任何有趣的信息,以便索引和存储。稍后,我将构建一个小的 ChatGPT 插件,让我可以访问我用它保存的所有信息。
总结当我们谈论人工智能的未来时,我们倾向于关注它的输出。只要得到提示,它就可以思考一个复杂的问题,撰写一篇文章,或者在没有太多人类参与的情况下创造新的科学突破。
我们倾向于低估输入的重要性——我们向它提供什么信息来产生这些结果。它的答案在很大程度上取决于我们提供给它进行分析的信息。它的强大程度取决于它的起点。
我们没有足够关注其知识的局限性——有多少信息被锁定,这些系统无法访问。我们也忘记了爬行信息源并找到相关事实是多么昂贵(在时间和计算方面)。最后,我们低估了在关键时刻为模型呈现相关信息的难度。

花粉社群VIP加油站
关于作者
猜你喜欢





































