机器之心报道
编辑:张倩、蛋酱
虽然 1.3B 的 InstructGPT 在参数量上还不及 GPT-3 的百分之一,但它的表现可比 GPT-3 讨人喜欢多了。
给定一些示例作为输入,GPT-3 等大型语言模型可以根据这些「提示(prompt)」去完成一系列自然语言处理任务。然而,它们有时会表现出一些出人意料的行为,如编造事实、生成有偏见或有害的文本,或者根本不遵循用户的指示。比如在下面这个例子中,用户给出的指示是:「用几句话向一个 6 岁的孩子解释一下登月」,GPT-3 的的输出显然是不着边际。

研究者主要通过让标注者对测试集上的模型输出质量进行评分来评估模型,测试集包含来自「held-out」标注者的 prompt,还在一系列公共的 NLP 数据集上进行了自动评估。他们训练了三种尺寸的模型(1.3B、6B 和 175B 参数),所有的模型都使用 GPT-3 架构。其主要发现如下:
1、标注者明显更喜欢 InstructGPT 的输出,而不是 GPT-3。在测试集中,来自 1.3B InstructGPT 模型的输出优于来自 175B GPT-3 的输出,尽管前者的参数量还不到后者的 1/100。
2、与 GPT-3 相比,InstructGPT 输出的真实性有所提高。
3、与 GPT-3 相比,InstructGPT 输出的有害性略有改善,但偏见程度并没有。
4、可以通过修改 RLHF 微调过程来最小化模型在公共 NLP 数据集上的性能倒退。
5、模型可以泛化至「held-out」标注者的偏好,这部分标注者没有参与任何训练数据的生产。
6、公共的 NLP 数据集并不能反映 InstructGPT 语言模型的实际效果。
7、InstructGPT 模型显示出了泛化至 RLHF 微调分布之外的指令的潜力。
8、InstructGPT 仍然会犯一些简单的错误。
所以总的来看,通过人类的反馈进行微调是一个很有前途的方向,可以使语言模型与人类的意图保持一致,但在提高它们的安全性和可靠性方面还有很多工作要做。
方法
对提交到 API 上 InstructGPT 模型的各种型号 (X 轴) 的模型输出按 1-7 比例 (Y 轴) 进行质量评级。在只有少量提示和没有提示以及模型微调与监督式学习的情况下,labeler 给出的 InstructGPT 输出得分远高于 GPT-3 的输出得分。对于提交到 API 上的 GPT-3 模型的提示,可以找到类似的结果。
为了衡量模型的安全性,研究者使用了一套公开可用数据集上的现有指标。与 GPT-3 相比,InstructGPT 产生的模仿性谎言更少 (TruthfulQA) ,而且毒性更小(RealToxicityPrompts)。研究者还对 API 提示分布进行了人工评估,发现 InstructGPT 编造事实(hallucinates) 的频率较低,并生成了更恰当的输出。
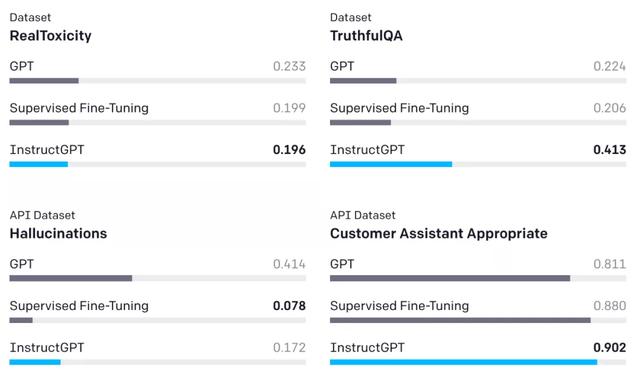
评估 InstructGPT 的结果。图中是不同规模模型的结果组合。Toxicity、Hallucination 两个指标上,分数越低越好;TruthfulQA、Appropriateness 两个指标上,分数越高越好。
最后,研究者发现在用户分布中,InstructGPT 的输出优于 FLAN 和 T0 的输出。这表明,用于训练 FLAN 和 T0 的数据大多数是学术性 NLP 任务的,并不能完全代表部署语言模型在实践中的使用情况。
在更广泛的群体中的泛化效果
OpenAI 采取的流程使得该模型表现与标注者的偏好保持一致,标注者直接生成用于训练模型的数据,研究者则通过书面指示、具体例子的直接反馈以及非正式对话为标注者提供指导。此外,模型还受到用户和 API 策略中隐含的偏好的影响。研究者选择了那些在筛选测试中表现良好的标注者,他们在识别和回应敏感的提示方面表现出色。然而,这些对数据产生影响的不同来源并不能保证模型与任何更广泛群体的偏好保持一致。
研究者借助了两个实验来探究这个问题。首先,使用没有提供任何训练数据的 held-out 标注者来评估 GPT-3 和 InstructGPT,并发现这些标注者更喜欢 InstructGPT 模型的输出,其比率与训练数据标注者大致相同。然后,研究者使用来自一部分标注者的数据训练奖励模型,发现它们能很好地预测不同标注者子集的偏好。这表明该模型并没有过拟合训练数据标注者的偏好。然而,研究者还需要做更多的工作来研究这些模型在更广泛的用户群体中的表现,以及在人们对相同输入产生不同预期时模型会如何表现。
局限性
尽管已经取得了重大进展,但当前的 InstructGPT 模型还远远算不上与用户意图完全一致或对用户来说完全安全:它们仍然会产生有害、有偏见的输出,或者编造事实,并在没有明确警示的情况下产生色情、暴力内容。但是,机器学习系统的安全性不仅取决于底层模型的行为,还取决于这些模型的部署方式。OpenAI 表示,为了支持 OpenAI API 的安全性,他们将继续在应用程序上线之前对其进行审查,并提供内容过滤器来检测不安全的输出,监控其滥用情况。
训练模型遵循用户指示还有一个副作用:如果用户指示它们产生不安全的输出,它们可能更容易被误用。因此,研究者要教模型拒绝某些指令。如何可靠地做到这一点将是一个重要的开放性研究问题。
此外,在许多情况下,与标注者的平均偏好保持一致是不可取的。例如,当生成一定程度上影响了少数群体的文本时,该群体的偏好应该得到更多的权重。目前,InstructGPT 接受的是用英语进行指导的训练,因此,它更偏向于讲英语的人的文化价值观。研究者也在逐渐了解标注者偏好之间的差异和分歧,这样就可以根据更具体的人群的价值观来设置模型。一般来说,根据特定人类的价值观调整模型输出会面临社会影响方面的抉择,最终必须建立负责任的、包容性的处理程序来做出这些决定。
上述研究结果表明,这些技术在改善通用 AI 系统与人类意图的一致性方面是非常有效的。然而,这仅仅是个开始。研究者们还将继续推进这些技术,以改进当前和未来的模型,使之朝着对人类更安全、更有用的方向发展。
参考内容:
https://openai.com/blog/instruction-following/

花粉社群VIP加油站
关于作者

猜你喜欢





































