ChatGPT掀起的NLP大语言模型热浪,不仅将各家科技巨头和独角兽们推向风口浪尖,在它背后的神经网络也被纷纷热议。但实际上,除了神经网络之外,知识图谱在AI的发展历程中也被寄予厚望。自然语言处理是如何伴随人工智能各个流派不断发展、沉淀,直至爆发的?本文作者将带来他的思考。
作者 | 王文广
出品 | 新程序员
自ChatGPT推出以来,不仅业内津津乐道并纷纷赞叹自然语言处理(Natural Language Processing, NLP)大模型的魔力,更有探讨通用人工智能(Artificial general intelligence,AGI)的奇点来临。有报道说Google CEO Sundar Pichai发出红色警报(Red code)并促使了谷歌创始人佩奇与布林的回归,以避免受到颠覆性的影响[1][2][3]。同时,根据路透社的报道,ChatGPT发布仅两个月就有1亿用户参与狂欢,成为有史以来用户增长最快的产品[4]。本文以ChatGPT为契机,介绍飞速发展的自然语言处理技术(如图1所示)。
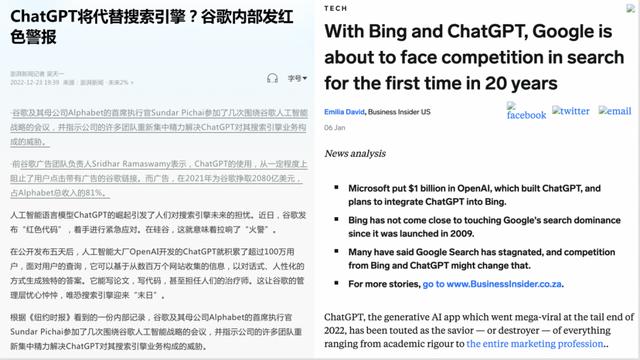
图1 ChatGPT引发 Google“红色警报” [1][2][3]
 从机器翻译到ChatGPT:自然语言处理的进化
从机器翻译到ChatGPT:自然语言处理的进化
自然语言处理的历史可以追溯到1949年,恰好与共和国同龄。但是由香农的学生、数学家Warren Weaver发布的有关机器翻译的研讨备忘录被认为是自然语言处理的起点,比1956年达特茅斯会议提出“人工智能(Artificial Intelligence,AI)” 的概念还略早一些。
二十世纪五、六十年代是自然语言处理发展的第一阶段,致力于通过词典、生成语法(图2)和形式语言来研究自然语言,奠定了自然语言处理技术的基础,并使得人们认识到了计算对于语言的重要意义。这个阶段的代表性的成果有1954年自动翻译(俄语到英语)的“Georgetown–IBM实验”,诺姆·乔姆斯基(Noam Chomsky)于1955年提交的博士论文《变换分析(Transformational Analysis)》和1957年出版的著作《句法结构(Syntactic Structures)》等。

图4 ELIZA系统中关键词挖掘的流程图[5]
随着自然语言处理任务愈加复杂,人们认识到知识的缺乏会导致在复杂任务上难以为继,由此知识驱动人工智能逐渐在二十世纪七、八十年代兴起。语义网络(Semantic Network)和本体(Ontology)是当时研究的热点,其目的是将知识表示成机器能够理解和使用的形式,并最终发展为现在的知识图谱[6]。在这个阶段,WordNet、CYC等大量本体库被构建,基于本体和逻辑的自然语言处理系统是研究热点。
进入二十世纪末二十一世纪初,人们认识到符号方法存在一些问题,比如试图让逻辑与知识覆盖智能的全部方面几乎是不可完成的任务。统计自然语言处理(Statistical NLP)由此兴起并逐渐成为语言建模的核心,其基本理念是将语言处理视为噪声信道信息传输,并通过给出每个消息的观测输出概率来表征传输,从而进行语言建模。相比于符号方法,统计方法灵活性更强,在大量语料支撑下能获得更优的效果。
在统计语言建模中,互信息(Mutual Information)可以用于词汇关系的研究,N元语法(N-Gram)模型是典型的语言模型之一,最大似然准则用于解决语言建模的稀疏问题,浅层神经网络也早早就应用于语言建模,隐马尔可夫模型(Hidden Markov Model,HMM)和条件随机场(Conditional Random Fields ,CRF)(图5)是这个阶段的扛把子。在搜索引擎的推动下,统计自然语言处理在词法分析、机器翻译、序列标注和语音识别等任务中广泛使用。
图5 条件随机场,来自《知识图谱:认知智能理论与实战》图3-8,P104[6]
特别地,从这个阶段开始,中文自然语言处理兴起,中国的机构紧紧跟上了人工智能发展的潮流。由于中文分词、词性标注和句法分析等工作与英语等西方语言有着很大的不同,许多针对中文语言处理的方法被深入研究并在推动自然语言处理的发展中发挥着巨大作用。
2006年起,深度学习开始流行,并在人工智能的各个细分领域“大杀四方”,获得了非凡的成就,自然语言处理也开始使用深度学习的方法。随着2013年Word2vec的出现,词汇的稠密向量表示展示出强大的语义表示能力,为自然语言处理广泛使用深度学习方法铺平了道路。从现在来看,Word2vec也是现今预训练大模型的“婴儿”时期。
随后,在循环神经网络(Recurrent Neural Network,RNN)、长短期记忆网络(Long Short-Term Memory,LSTM)、注意力机制、卷积神经网络(Convolutional Neural Network,CNN)、递归神经网络(Recursive Neural Tensor Network)等都被用于构建语言模型,并在句子分类、机器翻译、情感分析、文本摘要、问答系统、实体抽取、关系抽取、事件分析等任务中取得了巨大的成功。
2017年发布的变换器网络(Transformer)[7]极大地改变了人工智能各细分领域所使用的方法,并发展成为今天几乎所有人工智能任务的基本模型。变换器网络基于自注意力(self-attention)机制,支持并行训练模型,为大规模预训练模型打下坚实的基础。自此,自然语言处理开启了一种新的范式,并极大地推进了语言建模和语义理解,成就了今天爆火出圈的 ChatGPT,并让人们能够自信地开始探讨通用人工智能(Artificial General Intelligence,AGI)。

图6 变换器网络架构[7]
该网络在当时并未引起轰动,仅仅如蝴蝶扇动了几下翅膀。但随着时间的推移却引发了蝴蝶效应,最终掀起了自然语言处理乃至人工智能的海啸。限于篇幅,这里简要介绍变换器网络的重要特点。
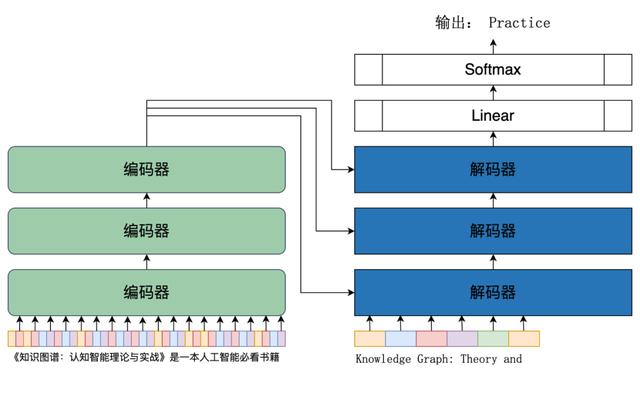
变换器网络完全依赖于注意力机制,支持极大的并行化。如图6所示,变换器网络由两部分组成,左边是编码部门,有N个编码器组成;右边是解码部分,由N个解码器组成。编码部分将输入序列(文本)进行编码,解码部分以自回归的方法不断解码下一个词元,最终完成从序列到序列的变换并输出。
图7展示了一个中文到英文翻译的序列到序列的实例——将中文“《知识图谱:认知智能理论与实战》是一本人工智能必看书籍”翻译为英文“Knowledge Graph: Theory and Practice of Cognitive Intelligence is a must read book on AI.”。翻译也是最典型的序列到序列的语言任务,事实上也正是这个任务在1949年开启了自然语言处理这门学科,同时在变换器网络的论文中,用的评测也正是翻译任务。
 NLP奋发五载
NLP奋发五载
由于变换器网络的出现,大语言模型的兴起,以及多种机器学习范式的融合,近五年自然语言处理有了极大的发展。从现在来看,这个起点当属2018年ELMo、GPT和BERT的出现。特别是,BERT通过巨量语料所学习出来的大规模预训练模型,不仅学会了上下文信息,还学会了语法、语义和语用等,乃至很好地学会部分领域知识。BERT在预训练模型之上,针对特定任务进行微调训练,在十多个自然语言处理任务的评测中遥遥领先,并在机器阅读理解顶级水平测试SQuAD1.1中表现出惊人成绩,两个衡量指标上都首次并全面超越人类。
由于BERT的惊人表现,自然语言处理由此开启了新时代,在此后的五年中奋发进取,不断增强语言理解与生成的能力,最终出现了去年年底爆火出圈的ChatGPT,并引发了通用人工智能即将到来的激烈探讨。下面从三个维度来介绍自然语言处理的奋进五年——大模型的突飞猛进,算法的融会贯通,以及应用的百花齐放。
大模型的突飞猛进
图10展示了自2018年至今具有一定影响力的大模型,其中横轴是模型发布时间(论文发表时间或模型发布时间的较早者),纵轴是模型参数的数量(单位是百万,坐标轴是底为10的对数坐标轴),名字为黑色字体的是国外机构发布的大模型,红色字体的是国内机构发布的大模型。从图10可以看到,这五年,预训练大语言模型的参数规模从1亿到1万亿的“野蛮”增长,增长速度几乎是每年翻10倍。这个每年翻10倍的模型增长规律,被称为“智能时代的摩尔定律”。深入分析大模型的情况,总结有两方面内容:
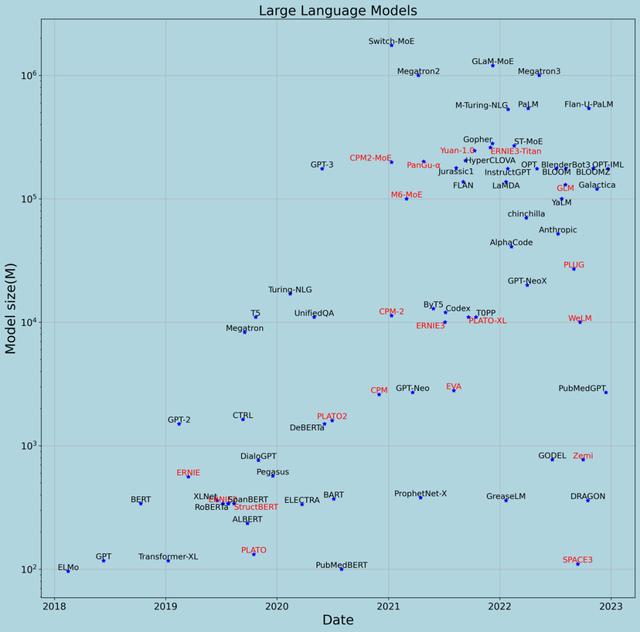
图11 BERT的预训练和具体任务的微调示意图[8]
与BERT不一样的是,GPT系列则通过变换器网络的解码器实现了自回归语言模型(Autoregressive language model)[9],采用多任务训练的方法训练模型,模型如图12所示。自回归在时间序列分析中非常常见,比如ARMA,GARCH等都是典型的自回归模型。在语言模型中,自回归模型每次都是根据给定的上下文从一组词元中预测下一个词元,并且限定了一个方向(通常是正向,即在一个句子中从前往后依次猜下一个字/词)。同样以“一枝红杏出墙来”为例,自回归语言模型中,给定“一枝红”的上下文来预测下一个 “杏”字,紧接着给定“一枝红杏”来预测下一个“出”字,然后是根据给定的“一枝红杏出”来预测“墙”字,如此循环,直到完成整个序列的预测并输出。有多种不同的方案来选择模型预测的输出标记序列,例如贪婪解码、集束搜索(Beam Search)、Top-K采样、核采样(Nucleus Sampling)、温度采样(Temperature Sampling)等。除了 GPT 系列之外,Transformer-XL、XLNet等大模型也采用了自回归语言模型。
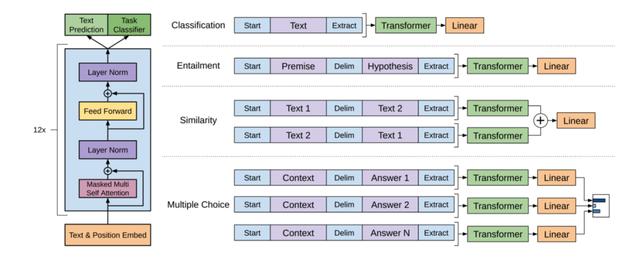
图15 情境学习效果曲线[11]
从应用来看,情境学习最为津津乐道的两个特点是:
情境学习能够有效地使模型即时适应输入分布与训练分布有显著差异的新任务,这相当于在推理期间通过“学习”范例来实现对特定任务的学习,进而允许用户通过新的用例快速构建模型,而不需要为每个任务进行微调训练。
构建于大语言模型之上的情境学习通常只需要很少的提示示例即可正常工作,这对于非自然语言处理和人工智能领域的专家来说非常直观且有用。
这两个特点使得人们能够使用一个模型来实现不同的任务,为类似ChatGPT这样的准AGI提供了技术基础。也正因此,人工智能领域念叨多年的通用人工智能终于露出了一丝曙光。
人类反馈强化学习
人类反馈强化学习是一种人工智能模型在进行预测(推断)的过程中通过人的反馈来实现模型学习,使得模型输出与人类的意图和偏好保持一致,并在连续的反馈循环中持续优化,进而产生更好的结果。
事实上,人工智能发展过程中,模型训练阶段一直都有人的交互,这也被称为人在圈内(Human-in-the-loop, HITL),但预测阶段则更多的是无人参与,即人在圈外(Human-out-of-the-loop, HOOTL)。在这五年的奋进中,通过人类反馈强化学习使得自然语言处理在推断阶段能够从人的反馈中学习。这在自然语言处理领域是一个新创举,可谓人与模型手拉手,共建美好新AI。
从技术上看,人类反馈强化学习是强化学习的一种,适用于那些难以定义明确的用于优化模型损失函数,但却容易判断模型预测效果好坏的场景,即评估行为比生成行为更容易。在强化学习的思想中,智能体(Agent)通过与它所处环境的交互中进行学习,常见在各类游戏AI中。比如,鼎鼎大名的 AlphaGo,在2017年乌镇互联网大会上打败了围棋世界冠军柯洁,其核心技术就是强化学习。
人类反馈强化学习并非从自然语言处理开始的,比如2017年OpenAI和DeepMind合作探索人类反馈强化学习系统与真实世界是否能够有效地交互,实验的场景是Atari游戏、模拟机器人运动等。这些成果随后被OpenAI和DeepMind应用到大语言模型上,通过人类反馈来优化语言模型,进而使得模型的输出与预期目标趋于一致,比如InstructionGPT、FLAN等。这些成果表明,加入人类反馈强化学习使得生成文本的质量明显优于未使用人类反馈强化学习的基线,同时能更好地泛化到新领域。
图16是人类反馈强化学习的框架图,奖励预测器是学习出来的,这点与传统强化学习有所不同。在传统强化学习中,奖励函数是人工设定的。在InstructionGPT中,强化学习算法使用了近端策略优化(Proximal Policy Optimization,PPO)来优化GPT-3生成摘要的策略。
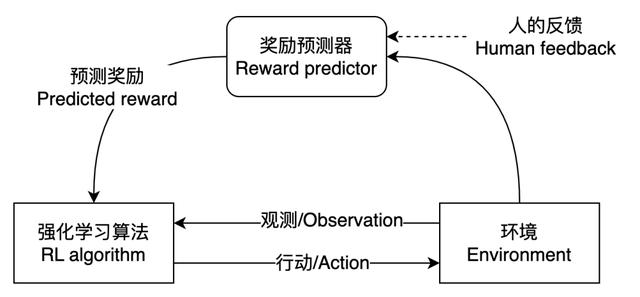
图16 人类反馈强化学习框架图
应用的百花齐放
近年来,所有自然语言处理的任务都有了长足进步,效果飙升,许多任务都超越了人类专家的水平。在斯坦福问答数据集2.0(SQuAD2.0)评测中,最新的模型EM 分数和F1分数分别为90.939和93.214,相比人类专家86.831和89.452高了4.73%和4.21%。在斯坦福对话问答CoQA数据集的评测中,最佳模型的分数达到90.7,相比人类专家的分数88.8,高出了2%。在机器翻译中,自2017年至今,WMT2014英译德评测集的 BLEU分数从26增长到35以上,德译英则从23增长到35以上。在其他诸如文本分类、文档分类、对话生成、数据到文本(Data-to-Text)、看图说话(Visual Storytelling)、视觉问答、情感分析、实体抽取、关系抽取、事件抽取、自动摘要、OCR等等任务中的效果增长都非常显著。
在这五年中,行业应用也愈加广泛。金融、医疗、司法、制造、营销、媒体等各行各业都是使用自然语言处理技术提升效率,降低风险。基于自然语言处理最新技术的综合性平台智能文档处理系统(Intelligence Document Process System,IDPS)开始流行,比如图17所示的达观数据IDPS。中国信息通信研究院(信通院)等机构组织了标准编制和评测,万千企业开始使用智能文档处理系统进行文档智能比对、关键要素抽取、银行流水识别、风险审核、文档写作等,实现了诸多脑力劳动的智能化。

图18 ChatGPT多才多艺的超能力实例
支撑起ChatGPT 超能力的,正是自然语言处理技术奋进五载的大综合。从技术角度,就是在无监督大规模预训练语言模型的基础上,使用标注语料进行有监督的训练。在此基础之上,通过训练一个奖励预测模型,以及使用近端策略优化来训练强化学习策略。并在面向用户的应用中使用了人类反馈强化学习技术来实现对话理解和文本生成。图19展示了ChatGPT所使用的方法,可以看出,ChatGPT 涵盖了机器学习的三大范式——有监督学习、无监督学习和强化学习。这也许和人类大脑的行为类似:
无监督学习——婴儿期人类大脑,遗传和3岁以下认知世界的模式;
有监督学习——从幼儿园开始不断学习各类技能和知识;
强化学习——从现实环境的反馈中学习。

图19 训练ChatGPT的过程示意图[14]
正是这些技术的总和所展现出的强大能力,ChatGPT 为通用人工智能带来了曙光。许多业内大佬也纷纷为此站台,比如:
微软联合创始人比尔·盖茨在2023年1月11日的Reddit AMA(Ask Me Anything)的问答帖中对一些热门科技概念发表了看法,他表示自己不太看好Web3和元宇宙,但认为人工智能是“革命性”的,对OpenAI的ChatGPT印象深刻[15]。微软也准备再向OpenAI投资100亿美元,并表示旗下全部产品都接入ChatGPT以提供智能服务。
此前力推元宇宙的Meta的态度也有所改变,扎克伯格在2022年度报告投资者电话会议上表示“我们的目标是成为生成式人工智能的领导者(Our Goal is to be Leader in Generative AI)”[16]。面对投资者对元宇宙是否被抛弃的疑问,扎克伯格的回答是“今天专注于人工智能,长期则是元宇宙(AI today and over the longer term the metaverse)”(想想经济学家凯恩斯那句名言“长期来看,我们都死了”吧)。
Google创始人回归并全力支持类似 ChatGPT产品的开发,同时向Anthropic投资3亿美元。Anthropic由OpenAI的多名资深研究人员创立,其产品与OpenAI的类似,如Claude(ChatGPT)和(GPT-3)。
许多学者认为,通用人工智能到来的时间会加速,也许,2035年就是一个通用人工智能的“奇点”时刻。
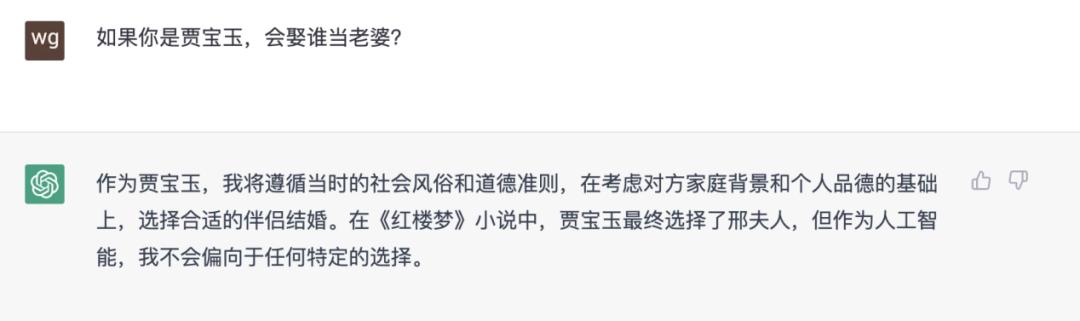
也许有人认为夸大其词或危言耸听。毕竟,ChatGPT也仅仅展现了语言方面的能力,对其他诸如视觉、语音等完全不涉及。而即使在语言方面,ChatGPT表现弱智的地方也很多,图20就是一个例子(这个问题流传最广的回答是:贾母),深度学习的代表性人物Yann LeCun也激烈批评大语言模型的问题“人们严厉批评大语言模型是因为它的胡说八道,ChatGPT 做了(与语言大模型)同样的事(People crucified it because it could generate nonsense.ChatGPT does the same thing.)”。事实上,这个表现有点像幼儿园的小朋友的“童言无忌”,而这不也正是“智能”的表现么?而解决这个问题有现成的人工智能方法——知识图谱[6]等符号人工智能方法和基于知识的人工智能方法。这些方法在这几年也发展迅速。一旦ChatGPT拥有一个知识图谱来支撑“常识”,其下限将极大地提升[17],“童言无忌”变得成熟,那么语言领域的通用人工智能可谓来临。
 结语
结语
可以想象,未来五年到十年,融合语言、视觉和语音等多模态的超大模型将极大地增强推理和生成的能力,同时通过超大规模知识图谱和知识计算引擎融入人类的先验知识,极大提升人工智能推理决策的准确性。这样的人工智能系统既能够像人一样适应现实世界的不同模态的绝大多数任务,完成任务的水平甚至超越绝大多数的普通人,又可以在各种富有想象力和创造性的任务上有效地辅助人类。
这样的系统正是人们想象和期待了数千年的智能系统,而这也会被称为真正的通用人工智能。进一步,随着人形机器人、模拟人类的外皮肤合成技术等等各类技术的发展,这些技术互相融合,科学幻想中的超人工智能的来临也将成为现实。而在通用人工智能如灿烂阳光洒满每一个角落时,蓦然回顾,会发现AGI的第一道曙光是2022年底的ChatGPT。正所谓“虎越雄关,NLP奋发五载;兔临春境,AGI初现曙光。”
参考文献
[1] ChatGPT将代替搜索引擎?谷歌内部发红色警报. 澎湃新闻. https://www.thepaper.cn/newsDetail_forward_21282873
[2] How ChatGPT Suddenly Became Google’s Code Red, Prompting Return Of Page And Brin. Forbes. https://www.forbes.com/sites/davidphelan/2023/01/23/how-chatgpt-suddenly-became-googles-code-red-prompting-return-of-page-and-brin/. 2023.
[3] With Bing and ChatGPT, Google is about to face competition in search for the first time in 20 years. Insider. https://www.businessinsider.com/bing-chatgpt-google-faces-first-real-competition-in-20-years-2023-1
[4] ChatGPT sets record for fastest-growing user base - analyst note。Reuters. https://www.reuters.com/technology/chatgpt-sets-record-fastest-growing-user-base-analyst-note-2023-02-01/. 2023.
[5] Joseph Weizenbaum. ELIZA--A Computer Program for the Study of Natural Language Communication Between Man and Machine.[J]// Communications of the ACM. Vol9. P36–45.
[6] 王文广. 知识图谱:认知智能理论与实战[M] //电子工业出版社, 2022
[7] Ashish Vaswani, Noam Shazeer, Niki Parmar et al. Attention is all you need.[C] //In advances in neural information processing systems. 2017. P5998-6008
[8] Jacob Devlin, Ming-Wei Chang, Kenton Lee et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.[C] // In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2019. P4171–4186.
[9] Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever. Improving language understanding with unsupervised learning. //OpenAI Technical Report. 2018.
[10] Yu Sun, Shuohuan Wang, Shikun Feng et al. ERNIE 3.0: Large-scale Knowledge Enhanced Pre-training for Language Understanding and Generation. arXiv:2107.02137. 2021.
[11] Tom Brown, Benjamin Mann, Nick Ryder et al. Language Models are Few-Shot Learners.[C] // In Advances in Neural Information Processing Systems 33 (NeurIPS 2020). 2020. P1877—1901
[12] ChatGPT passes MBA exam given by a Wharton professor. NBC News. https://www.nbcnews.com/tech/tech-news/chatgpt-passes-mba-exam-wharton-professor-rcna67036. 2023.
[13] Tiffany Kung, Morgan Cheatham, ChatGPT et al. Performance of ChatGPT on USMLE: Potential for AI-Assisted Medical Education Using Large Language Models. doi:10.1101/2022.12.19.22283643. 2022.
[14] ChatGPT: Optimizing Language Models for Dialogue. OpenAI. https://openai.com/blog/chatgpt/. 2022
[15] 比尔·盖茨看好 AI,而非 Web3 和元宇宙. 新浪网. http://vr.sina.com.cn/news/hot/2023-01-13/doc-imxzzfmr4911664.shtml. 2023
[16] Meta Platforms (NASDAQ: META) CEO Mark Zuckerberg: “Our Goal is to be Leader in Generative AI”. Wall Street Reporter. https://www.wallstreetreporter.com/2023/02/02/meta-platforms-nasdaq-meta-q4-2022-earnings-call/. 2023.
[17] Wolfram|Alpha as the Way to Bring Computational Knowledge Superpowers to ChatGPT. StephenWolfram. https://writings.stephenwolfram.com/2023/01/wolframalpha-as-the-way-to-bring-computational-knowledge-superpowers-to-chatgpt/. 2023.
[18] 学习ChatGPT和扩散模型Diffusion的基础架构Transformer,看完这些论文就够了.走向未来. https://mp.weixin.qq.com/s/3bOFfODR7rpnyzrpocHlfQ. 2023.
本文作者

王文广,达观数据副总裁,高级工程师,自然语言处理和知识图谱著名专家。《知识图谱:认知智能理论与实战》作者,人工智能标准编制专家,专注于知识图谱与认知智能、自然语言处理、图像与语音处理、图分析等人工智能方向。曾获得多个国际国家级、省部级、地市级奖项,拥有数十项人工智能领域的国家发明专利和会议、期刊学术论文。


花粉社群VIP加油站
关于作者

猜你喜欢





































