
上图中,标黄的模型均为开源模型。
语料
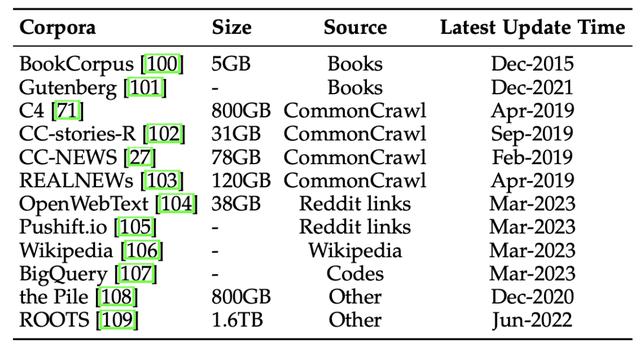
训练大规模语言模型,训练语料不可或缺。主要的开源语料可以分成5类:书籍、网页爬取、社交媒体平台、百科、代码。
书籍语料包括:BookCorpus[16] 和 Project Gutenberg[17],分别包含1.1万和7万本书籍。前者在GPT-2等小模型中使用较多,而MT-NLG 和 LLaMA等大模型均使用了后者作为训练语料。
最常用的网页爬取语料是CommonCrawl[18]。不过该语料虽然很大,但质量较差。大模型大多采用从其中筛选得到的子集用于训练。常用的4个子集包括:C4[19], CC-Stories, CC-News[20], 和 RealNews[21]。
CC-Stories的原版现在已不提供下载,一个替代选项是CC-Stories-R[22]。
社交媒体平台语料主要获取自Reddit平台。WebText包含了Reddit平台上的高赞内容,然而现在已经不提供下载,现在可以用OpenWebText[23]替代。此外,PushShift.io[24]提供了一个实时更新的Reddit的全部内容。
百科语料就是维基百科(Wikipedia[25])的下载数据。该语料被广泛地用于多种大语言模型(GPT-3, LaMDA, LLaMA 等),且提供多种语言版本,可用于支持跨语言模型训练。
代码语料主要来自于GitHub中的项目,或代码问答社区。开源的代码语料有谷歌的BigQuery[26]。大语言模型CodeGen在训练时就使用了BigQuery的一个子集。
除了这些单一内容来源的语料,还有一些语料集。比如 the Pile[27]合并了22个子集,构建了800GB规模的混合语料。而 ROOTS[28]整合了59种语言的语料,包含1.61TB的文本内容。

花粉社群VIP加油站
关于作者

猜你喜欢





































