迄今为止,OpenAI 的 GPT-3是有史以来最大的语言模型之一,有1750亿个参数。

他们表示,1.6万亿参数模型是迄今为止最大的,并比之前最大的、由google开发的语言模型T5-XXL足足快了4倍。
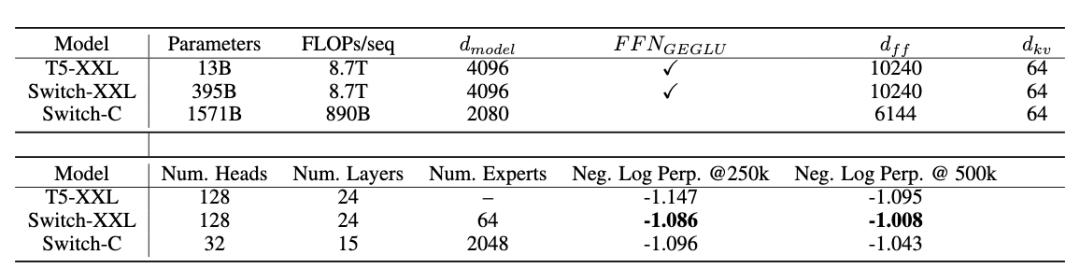
图:Switch Transformer编码块
Switch Transformer使用了一种叫做稀疏激活(sparsely activated)的技术,这个技术只使用了模型权重的子集,或者是转换模型内输入数据的参数,即可达成相同的效果。
此外,Switch Transformer还主要建立在混合专家(Mix of Expert)的基础上。
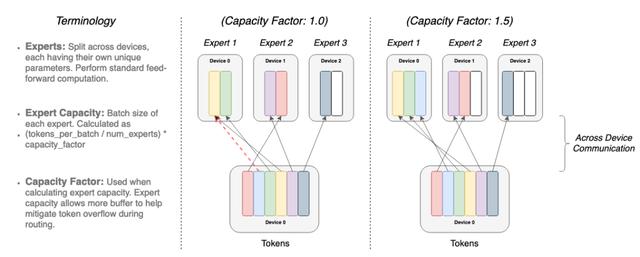
图:Token动态路由示例
什么是“混合专家”呢?
混合专家(Mix of Expert,MoE)是90年代初首次提出的人工智能模型范式。
在MoE中,对于不同的输入,会选择不同的参数。多个专家(或者专门从事不同任务的模型)被保留在一个更大的模型中,针对任何给定的数据,由一个“门控网络”来选择咨询哪些专家。
其结果是一个稀疏激活的模型——具有数量惊人的参数,但计算成本不变。然而,尽管MoE取得了一些显著的成功,但其广泛采用仍然受到复杂性、通信成本和训练不稳定性的阻碍。而Switch Transformer则解决了这些问题。
Switch Transformer的新颖之处,在于它有效地利用了为密集矩阵乘法(广泛应用于语言模型的数学运算)设计的硬件,如GPU和谷歌的TPU。
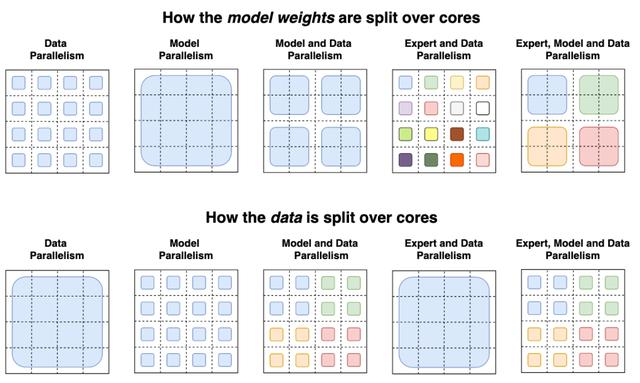
图:数据和权重划分策略
在研究人员的分布式训练设置中,他们的模型将不同的权重分配到不同的设备上,因此,虽然权重会随着设备数量的增加而增加,但是每个设备却可以保持可管理的内存和计算足迹。
在一项实验中,研究人员使用了32个TPU核,在“Colossal Clean Crawled Corpus”,也就是 C4 数据集上,预先训练了几种不同的Switch Transformer模型。
C4是一个750gb大小的数据集,包含从Reddit、Wikipedia和其他web资源上获取的文本。

图:C4数据集
研究人员让这些Switch Transformer模型去预测有15%的单词被掩盖的段落中遗漏的单词,除此之外,还为模型布置了许多其他挑战,如检索文本来回答一系列越来越难的问题等等。
研究人员声称,和包含3950亿个参数和64名专家的更小的模型(Switch-XXL)相比,他们发明的拥有2,048名专家的1.6万亿参数模型(Switch-C)则“完全没有训练不稳定性”。
然而,在SQuAD的基准测试上,Switch-C的得分却更低(87.7),而Switch-XXL的得分为89.6。
对此,研究人员将此归因于微调质量、计算要求和参数数量之间的不明确关系。
在这种情况下,Switch Transformer还是在许多下游任务上的效果有了提升。例如,根据研究人员的说法,在使用相同数量的计算资源的情况下,它可以使预训练的速度提高了7倍以上。
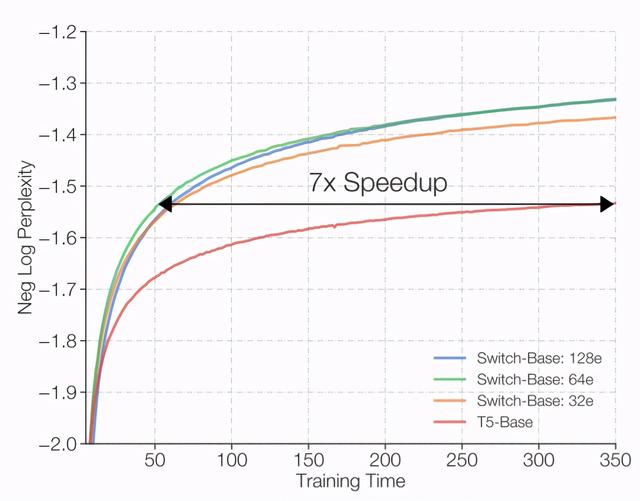
图:所有模型均在32个TPU上进行训练
同时研究人员证明,大型稀疏模型可以用来创建更小、更稠密的模型,这些模型可以对任务进行微调,其质量增益只有大型模型的30% 。
在一个测试中,一个 Switch Transformer 模型被训练在100多种不同的语言之间进行翻译,研究人员观察到其中101种语言都得到了“普遍的改善” ,91% 的语言受益于超过baseline模型4倍以上的速度。
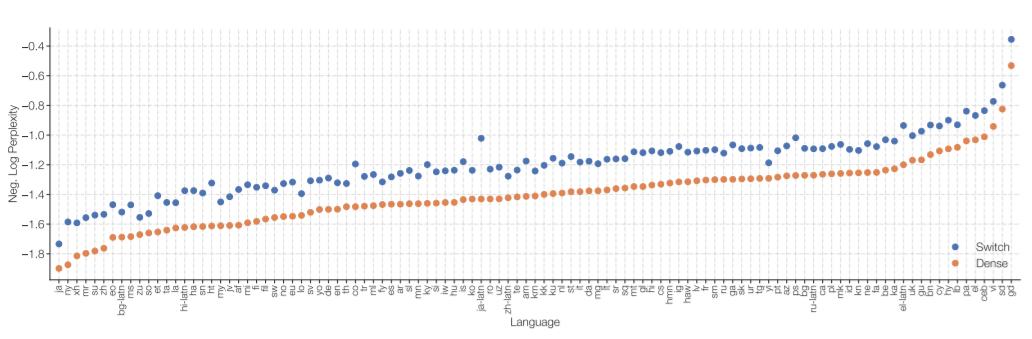
图:101种语言的多语言预训练
研究人员在论文中写道: “虽然这项工作主要集中在超大型模型上,但我们也发现,只有两个专家的模型能够提高性能,同时很容易适应常用 GPU 或 TPU 的内存约束。”
“我们不能完全保证模型的质量,但是通过将稀疏模型蒸馏成稠密模型,同时达到专家模型质量增益的30%的情况下 ,是可以达到10到100倍压缩率的。”
在未来的工作中,研究人员计划将Switch Transformer应用到新的和跨越不同的模态中去,包括图像和文本。他们认为,模型稀疏性可以赋予各种不同媒介以及多模态模型一些优势。
在论文的最后,Google的研究人员还表示:
总的来说,Switch Transformers是一个可扩展的,高效的自然语言学习模型。
通过简化MoE,得到了一个易于理解、易于训练的体系结构,该结构还比同等大小的密集模型具有更大的采样效率。
这些模型在一系列不同的自然语言任务和不同的训练机制中,包括预训练、微调和多任务训练,都表现出色。
这些进步使得使用数千亿到万亿参数训练模型成为可能,相对于密集的T5基准,这些模型可以实现显著的加速。
谷歌的研究人员表示,希望他们的工作能够激励稀疏模型成为一种有效的架构,并鼓励研究人员和实践者在自然语言任务中考虑这些灵活的模型。
参考链接:
https://arxiv.org/pdf/2101.03961.pdf
https://venturebeat.com/2021/01/12/google-trained-a-trillion-parameter-ai-language-model/

花粉社群VIP加油站
关于作者

猜你喜欢





































