虽然GPT-3已经发布了很长一段时间,因为它在编写类似人类的故事和诗歌方面的卓越能力而受到广泛关注,但我从来没有想到它附带的API能够为构建具有广泛应用程序的数据产品提供如此大的灵活性和方便性。
在本文中,我试图探索一些与我在就业市场中看到的问题相关的用例,并试图理解构建基于语言的数据产品在未来可能只是围绕着“即时工程”。
与此同时,本文并不试图解释GPT-3是如何工作的,也不试图解释它如何能够完成它正在做的事情。关于这些话题的更多细节已经在Jay Alammar[1]和Max Woolf[2]等文章中写得很详细。GPT-3论文本身可以在[3]中引用。

在下面的例子中,我们试图测试属于完全不同类别的招聘广告,从原始提示(即。会计/财务和销售/营销”)。虽然测试样本很小,但结果响应也是积极的。
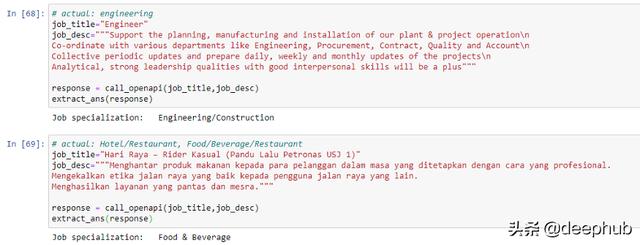
关于最后一个例子,让我惊讶的是,模型本身能够处理马来语输入,而不需要首先将文本翻译成英语。
案例2:工作的搜索排序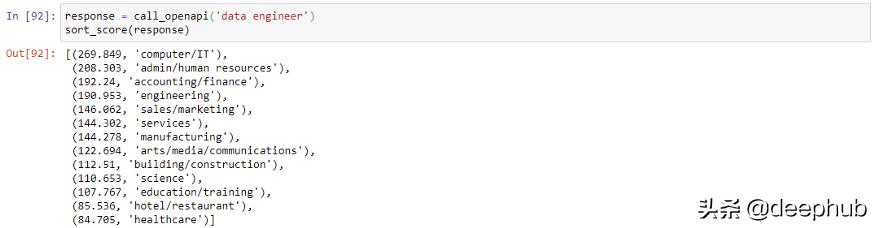
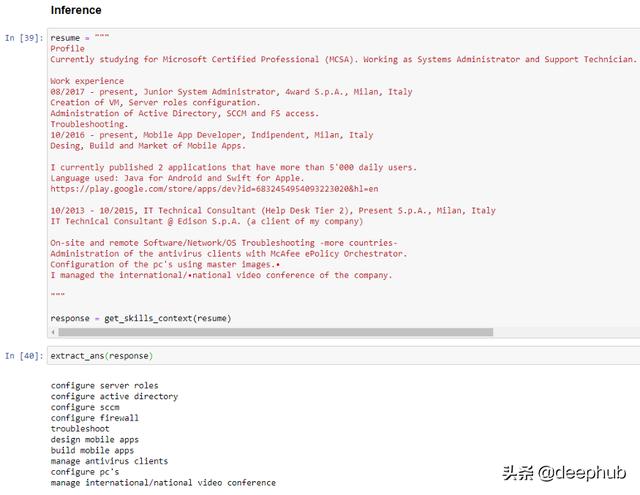
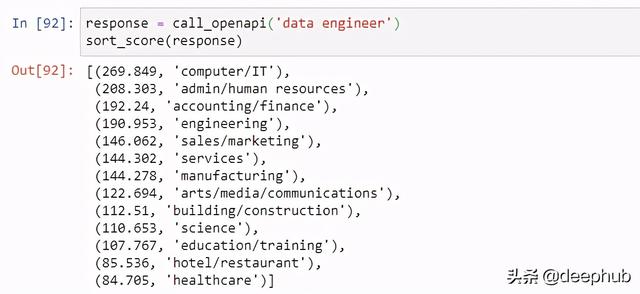 案例3:从简历中解析技能上下文
案例3:从简历中解析技能上下文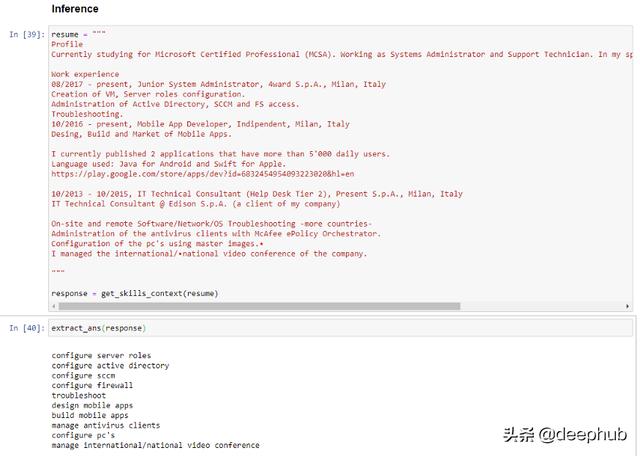
问题
我们希望在提供的招聘广告或简历的基础上,能够从中提取出某些信息,以帮助我们更好地匹配求职者和招聘广告。
虽然我们可以从一份简历/广告中提取很多信息(比如技术技能、工作经历、过去的教育经历等),但在这个用例中,我们将专注于提取软技能。
解决方案
解决这个问题最简单的方法是依靠一个软技能字典,并基于精确匹配或某种形式的字符串相似度算法在一组阈值内提取关键字。虽然一开始很有效,但很快就会被这些问题包围:
所提取的软技能与我们想要的内容并不匹配(这并不是一种真正的技能,因此存在精确度问题)。我们无法用很多方式来描述他们的软技能(回忆问题)。
在我们提出的解决方案中,我们的目标是通过一些简历中典型的经历部分的例子来解决这个问题,并向它提供一些提取的软技能的例子。
def get_skills_context(resume):response = openai.Completion.create(engine="davinci",prompt="""This is a resume parser that extracts skills context from resume.resume: {resume1}parsed_contextual_skills: {extract1}###resume: {resume2}parsed_contextual_skills: {extract2}###resume: {resume3}parsed_contextual_skills: """.format(resume1 = resume_1, extract1 = extract_1,resume2 = resume_2,extract2 = extract_2,resume3 = resume),temperature=0.2,max_tokens=60,top_p=1.0,frequency_penalty=0.0,presence_penalty=0.0,stop=["###"])return responsedef extract_ans(response):return print(response.choices[0].text)
从高层次的角度来看,它似乎能够提炼出简历中提到的大部分技能。特别有趣的是标准化“配置”而不是使用“管理”(源自“管理”)的能力。它还能在列表中添加“配置防火墙”——这是一项在简历中根本没有提到的技能,但可能从F5、McAfee等其他工具的存在中有所暗示。
之前不得不构建一些类似的东西(使用Spacy、Databricks和许多手动维护的字典等工具的组合),解决方案构建的简单性(比如。记事处理)结合输出导出的质量-使我更欣赏GPT-3。
总结本文首先简要介绍了即时工程,然后快速转移到可能适用于GPT-3的就业市场行业中的一些相关用例。
每个数据产品构建的简易性(通过提示),以及我们从中得到的结果——证明了GPT-3在成为解决基于语言的任务的通用工具方面具有巨大的潜力。
话虽如此,与构建任何数据产品一样,仍然需要更彻底和全面的验证测试来确定GPT-3可能存在的差距和错误。然而,这不是本文的范围。
本文中使用的代码可以在我的git repo[6]中找到。
作者:Hafidz Zulkifli

花粉社群VIP加油站
关于作者
猜你喜欢





































