
编者按:提起李宏毅老师,熟悉 AI 的读者朋友一定不会陌生。在 GPT-3 推出之后,李宏毅老师专门讲解了这个非同凡响的模型,称之为 “来自猎人暗黑大陆的模型”。
出于知识传播目的,“数据实战派” 根据该讲解视频将李宏毅老师的见解整理成文,有基于原意的删改:
OpenAI 发表了新的巨大的 language model,在此之前 OpenAI 已经发表了 GPT,还有轰动一时的 GPT-2,现在到了 GPT-3(GPT-3 的论文题目为 Language Models are Few-Shot Learners)。
那么,GPT-3 跟 GPT-2 有什么不同呢?基本上没有什么不同,它们都是 language model。GPT-3 神奇的地方是什么呢?神奇的地方是它太过巨大。
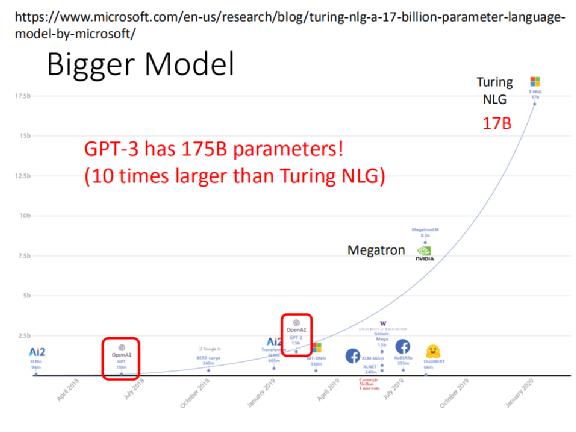 在它之前,最大的 model 是 Turing NLG,在之前已经给大家看过一个 model 大小的比较图,包括从最早的 ELMo 到后来的 Turing NLG 。Turing NLG 已经非常的巨大,它有 17 个 billion 的参数,远超之前 OpenAI 发表的 GPT-2 和最早的 GPT。
在它之前,最大的 model 是 Turing NLG,在之前已经给大家看过一个 model 大小的比较图,包括从最早的 ELMo 到后来的 Turing NLG 。Turing NLG 已经非常的巨大,它有 17 个 billion 的参数,远超之前 OpenAI 发表的 GPT-2 和最早的 GPT。
而第三代的 GPT 有多大?它是 Turing NLG 的 10 倍,它有 175 个 billion 的参数,也就是 1750 亿个参数,你根本没有办法把它画在这一张图上。

假设我们用长度来代表参数量,ELMO 的参数量是一个长 30 公分的尺,则 GPT-3 约是 ELMO 的 2000 倍。30 公分 ×2000 是多少?它比台北 101 还要高。
 2GPT-3 的神奇之处
2GPT-3 的神奇之处那么,GPT-3 这篇 paper 表现如何?硕大无朋的 GPT-3 表现如何?
上图是论文中所用的 42 个 task 的平均情况。数目正好是 42,这是个很巧的数字,我们知道 42 是生命的意义(《银河系漫游指南》中的计算机用了 N 久的时间得出的结果),不知道这里的 42 个任务是不是刻意选择出来的。
上图纵轴是正确率,横轴是 model 的大小,从 0.1 billion 一直到 175 billion。蓝色是 Zero Shot,绿色是 One Shot,橙色是 Few Shot。可以看到随着 model 越来越大,不管是 Few-shot Learning、One-shot Learning 还是 Zero-shot Learning 的正确率,都越来越高。
当然有人可能会质疑,为了增加这么一点点正确率,用了大概 10 倍的参数量到底值不值得?至少这个图显示,比较大的 model 确实是有好处的,至于大了 10 倍,只是增加这样的正确率,到底能不能够接受、划不划算,这是一个见仁见智的问题。

接下来就讲 GPT-3 的几个神奇之处。首先,它可以做 Closed Book QA。在 question answering 中,有一个 knowledge source,有一个 question,然后要找出 answer。如果机器在回答问题的时候可以看 knowledge source,就是 open book QA,而 Closed Book QA 则是没有 knowledge source,直接问一个问题看看能不能得到答案。比如直接问你,喜马拉雅山有多高,看机器的参数里面会不会有喜马拉雅山高度的资讯,会不会不需要读任何文章,它就知道喜马拉雅山的高度是 8848 公尺。
而 GPT-3 的表现就是这个样子,蓝色的线是 Zero Shot,绿色的线 One Shot,橙子色的线是 Few Shot。神奇的事情是, Few-shot Learning 居然超过了在 TriviaQA 上 fine-tune 最好的 SOTA model。
所以,在这里,巨大的 model 展现了奇迹。如果是只有 13 个 billion,没有办法超越 SOTA,但约 10 倍大,达到 175 个 billion,可以超越 SOTA。
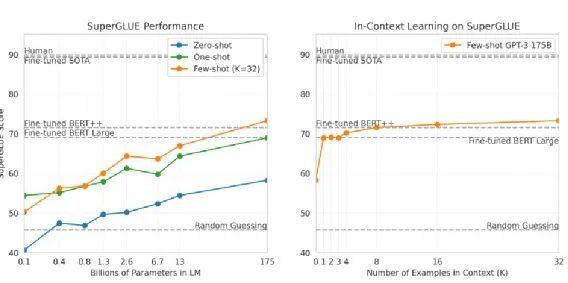
上图是 SuperGLUE 的部分,同样显示 Zero-shot Learning 、One-shot Learning 、Few-shot Learning 的 performance,谁的参数量越来越多,performance 当然越来越好。如果看最大的 model 的话,它可以超越 Fine-tuned BERT Large model。
右边这张图显示,在做 Few-shot Learning 时,training example 对 performance 所造成的影响。
如果没有给任何 example,也就是 Zero-shot Learning,当然有点差。但随着 example 越来越多,如果只给 1、2、3、4 个,那与 Fine-tuned BERT 的 performance 差不多;如果给到 32 个,就可以超越 Fine-tuned BERT。
GPT-3 是一个 language model,所以它可以生成文本。在 GPT-3 论文中,作者也用 GPT-3 来产生文章。他们给 GPT-3 新闻的标题,然后希望 GPT-3 自己把新闻写出来。
有一个神奇的小发现是:如果不给 GPT-3 任何 example,只给它一则新闻的标题,它会以为这则新闻的标题是推特的一句话,然后接下来它就会自己去回忆想象。
所以在生成文本的时候,GPT-3 不会是 Zero-shot 的,你需要给它几个 example,告诉它有一个标题,下面会接一篇新闻,然后接下来再给他一个标题,希望它可以根据这个标题阐述。 有一个人说,她男朋友跟她交往 8 个月,然后有一天她男朋友要给她一个生日礼物,她男朋友就把所有的朋友都找齐,然后秀出了他的背,他的背上有一个他女朋友的脸的刺青,而这个女生会觉得不太行,问怎么办,期待网友给一些建议。
有一个人说,她男朋友跟她交往 8 个月,然后有一天她男朋友要给她一个生日礼物,她男朋友就把所有的朋友都找齐,然后秀出了他的背,他的背上有一个他女朋友的脸的刺青,而这个女生会觉得不太行,问怎么办,期待网友给一些建议。
在这个问题上,GPT 建议分手。

对机器而言,要给出像样的建议不太容易。
再举个例子,有人问了一个问题,说他要上高中解剖课,但是他很害怕死掉的动物,那怎么办?有一个人给了一个建议,他建议说你可以越级上报,提问者也觉得这个建议有用。我其实有点不太确定这个建议有没有用,不过至少这个问问题的人觉得是有用的。
那么,机器怎么学会给建议呢?你训练一个 model,这个 model “吃” 下 reddit 上的一个 point,然后它会想办法去模仿 point 下面的回复。
这个比赛提供了 600k 训练数据,也就是 600k 个 reddit 上的 point 及 point 下的回应,而期待机器可以学会正确的回应。
这里以 T5 当作例子,那个时候还没有 GPT-3。T5 答案是这样,你去和你的老师说,你想要一个 project,然后这个 project 可以看到死的动物。
这个回答显然就是不知所云,看起来是合理的句子,看起来像在讲些什么,但实际上没有什么作用。今天,这些巨大的 language model,它往往能得到的表现就是样子。
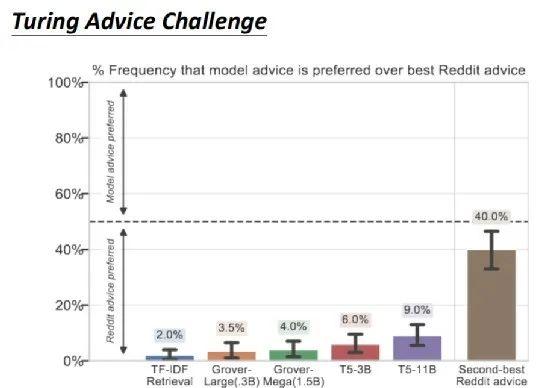
上图是一些真正的实验结果。在 Turing Advice Challenge 中,包括 Grover、T5 等各式各样的模型。结果是,就算是 T5,人们也只有在 9% 的情况下,才觉得 T5 提出来的建议比人提出来的建议有效。
如果现在比较 reddit 上评分第一高的建议与第二高的建议,其实评分第二高的建议还有 40% 的人是觉得有用的,但 T5 只有 9% 的人是觉得有用。
这说明了,用这种巨大的 language model 帮助机器产生的文字,和人类对语言使用的能力仍相差甚远。

由于微信公众号试行乱序推送,您可能不再能准时收到AI科技评论的推送。为了第一时间收到AI科技评论的报道, 请将“AI科技评论”设为星标账号在看”。

花粉社群VIP加油站
关于作者

猜你喜欢





































