2019 年,GPT-2 凭借将近 30 亿条参数的规模拿下来“最强 NLP 模型”的称号;2020 年,1750 亿条参数的 GPT-3 震撼发布,并同时在工业界与学术界掀起了各种争论。随着时间的推移,争论的焦点也发生了变化,人们逐渐发现:GPT-3 似乎不仅仅是“越来越大”这么简单。
GPT-3 不仅庞大,还很强大?照例先放地址: https://github.com/openai/gpt-3
然后就要解答一个重要的问题:GPT-3 是什么?
按照官方介绍:GPT-3 是由人工智能研发公司 OpenAI 开发的一种用于文本生成的自然语言处理(NLP)模型。它的前作 GPT-2 曾被赋予“最强 NLP 模型”的称号,一个重要的原因就是 GPT-2 拥有着非常庞大的规模(见下注)。
注:OpenAI 已经于 2019 年发布了三种 GPT-2 模型:“小型的”1.24 亿参数模型(有 500MB 在磁盘上 ),“中型的”3.55 亿参数模型(有 1.5GB 在磁盘上 ),以及 7.74 亿参数模型(有 3GB 在磁盘上 )。作为 GPT-2 分段发布中的最后一轮,2019 年 11 月,OpenAI 公开了完整 GPT-2 包含 15 亿条参数,其中包含用于检测 GPT-2 模型输出的全部代码及模型权重。
2020 年 5 月,GPT-3 的论文一经发表就引发了业内的轰动,因为这一版本的模型有着巨大的 1750 亿参数量。
熟悉人工智能的人应该知道,AI 三要素是:算力、算法、数据。在前两者基本固定的情况下,数据量的大小对 AI 模型的效果会起到非常关键的作用,GPT-3 如此庞大的规模能够带来的影响不言而喻。
为了对 GPT-3 有更进一步的了解,InfoQ 采访到了来自 小米公司 负责开放域对话和生成类任务的技术专家魏晨 ,作为对 GPT 有过实际应用的技术人,她也研究了 GPT-3 与 GPT-2 相比的一些主要变化:
两者模型和结构是相同的,包括修改的初始化 (modified initialization),预规范化 (pre-normalization) 和可逆记号化 (reversible tokenization)。不同之处在于,在 transformer 各层中使用了交替稠密(alternating dense)且局部带状稀疏注意力(locally banded sparse attention)模式,类似于 Spare Transformer。GPT-3 模型不仅超级大,且在超大数据集上进行了训练 (45TB,过滤筛选后大约 570GB)。这些使得 GPT-3 可以很好地做其他模型无法做的事情: 执行特定任务而无需任何特殊调整,可以做翻译,写程序,作诗,写文章,仅需要提供极少 / 几个的训练样本 。有了 pre-train 的 GPT-3 模型,应用到下游 NLP 任务时,无需执行微调步骤,基本无需训练样本就可以执行自定义自然语言任务。而其他的语言模型 (BERT) 需要精巧的微调步骤,需要准备几千个或者几万个训练数据。GPT-3 不包含主要的新技术,它基本上是去年 GPT-2 的放大版本 ,而 GPT-2 本身就是使用深度学习的其他语言模型的大号版本。所有这些都是在文本上训练的巨大人工神经网络,用于预测序列中的下一个单词可能是什么。 GPT-3 只是更大:更大 100 倍(96 层和 1,750 亿个参数),并且接受了更多数据的训练(CommonCrawl,一个包含大量 Internet 的数据库,以及一个庞大的图书库和所有 Wikipedia)。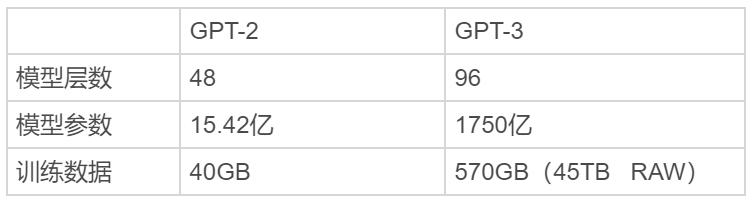
虽然有些 demo 目前还有些粗糙,但也足以看出 GPT-3 的能力是不容小觑的。作为出品方的 OpenAI 也在官网上放出了一些体验项目,比如常见的聊天机器人、智能客服等等,还有 AI 自动生成的文字闯关游戏,感兴趣的读者也可以在这里体验: https://beta.openai.com/
在这些 demo 当中,各种代码生成工具引发了不小的讨论,除了上面说的简单生成一个按钮之外,GPT-3 还可以完整生成一整个页面及代码:
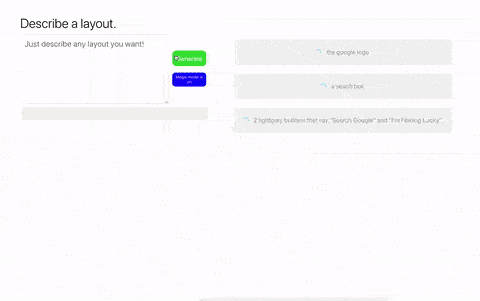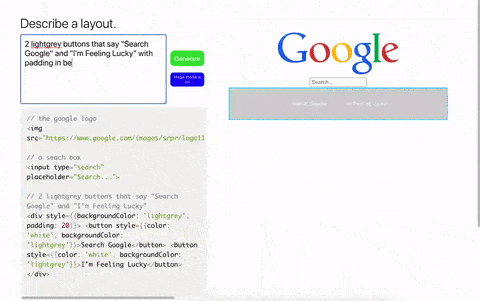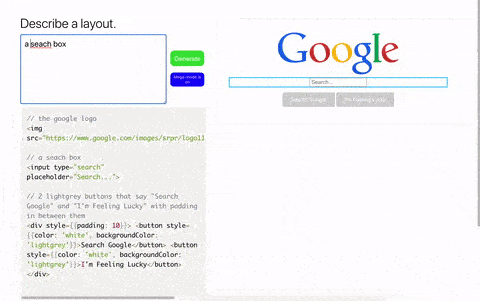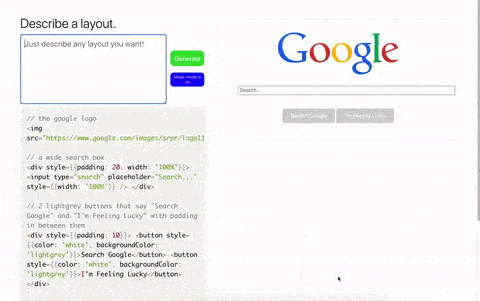
通过文字描述生成一个谷歌搜索界面
于是就有了一些声音认为,随着 GPT-3 这样强大的模型出现,一部分程序员的工作是可以交给 AI 来处理的;当然反对的声音也很大,认为前一种想法不切实际,AI 目前仍然没有替代人类的能力。
有意思的是,随着全球对 GPT-3 话题讨论热度的攀升,就连 OpenAI 联合创始人 Sam Altman 都站出来表示:“ (网络上的)这类说法过分夸大了 GPT-3 的能力 。”
我们也就这一话题请两位专家谈了谈自己的看法,来自小米的魏晨说:
首先,技术的发展进步令人兴奋,但是看问题仍然要回归到理性。 这些都是精心挑选的示例, 更多只显示有效的结果,而忽略无效的结果 。这意味着 GPT-3 的能力总体上比其细节更令人印象深刻。但是 GPT-3 也会出现简单的错误。也许我们可以检验比较一下 GPT、GPT-2 和 GPT-3 的低级错误率,看它们是否真正在避免低级错误(从一个角度讲,掌握基础知识)上有更多的进步。
她补充道,尽管 GPT-3 确实可以编写代码,但很难判断其总体用途 。比如,如何判断是整洁可执行的还是一般的代码?这样的代码上线后会不会给人类开发人员带来更多问题?没有详细的测试,这一切都很难说,即使是人类程序员也会犯错误。
其次,魏晨认为很难权衡这些错误的重要性和普遍性。如何判断几乎可以问任何问题的程序的准确性?如何创建 GPT-3 的“知识”的系统地图,然后如何对其进行标记?尽管 GPT-3 经常会出错,但有意思的是,通常可以通过微调所输入的文本(即提示)来解决这些问题。
在一个示例错误中,用户询问 GPT-3:“哪个更重,一个烤面包机或一支铅笔?”它回答说:“铅笔比烤面包机重。”学者 Branwen 指出,如果在问这个问题之前给机器喂食某些提示,告诉它水壶比猫重,海洋比尘土重,它会给出正确的响应。这可能是一个棘手的过程,但是它表明 GPT-3 有能力学习到正确的答案。
对于这类生成代码的 demo,苏海波则表示:“ GPT-3 对某些编程开发工作能够有一定的辅助作用,但完全替代是很困难的 。”他认为,目前这些通过输入文字直接生成代码的演示,对于一些逻辑很简单的代码,例如前端开发中的标准化组件生成代码,容易通过文字来描述的,可以采用 GPT-3 来实现,但是逻辑稍微复杂一些的后端开发代码,不好用文字来描述的,就难以通过 GPT-3 来实现了,例如现有的 NLP 产品或者项目的代码开发工作,是很难通过 GPT-3 来替代的。
结 语通过对 GPT-3 的介绍、优缺点分析以及生成代码实践的解析,相信读者对于 GPT-3 的情况已经有了一些了解,最后总结一下两位老师回答的重点:
1.GPT-3 参数庞大(约 1750 亿参数),能力较之前确实有所提升,但是宣传效果有夸张成分;
2. 受参数大小影响,GPT-3 并不是一款性价比很高的模型,训练成本较高;
3. 中文 GPT-3 的实践尚未出现;
4.GPT-3 确实可以通过文字输入生成代码,但是仅限于比较简单的情况;
5. 离 AI 真正替代程序员工作, 还有较长的路要走 。
是的,GPT-3 很庞大,但是离“翻天覆地”似乎仍有一段距离,但不可否认的是,它仍然是自然语言处理甚至人工智能发展史上重要的里程碑。正如那句行业“金句”所说:“ 新技术总是在质疑中成长 ”,真正有价值的技术会最终会被认可,相信随着全行业愈发理性地看待 AI 技术的进步,如深度学习一样颠覆性的技术在不久的将来就会出现。
关注我并转发此篇文章,私信我“领取资料”,即可免费获得InfoQ价值4999元迷你书!

花粉社群VIP加油站
关于作者

猜你喜欢





































