31位作者,72页论文,320万token(一个batch),1750亿参数……
OpenAI最新论文《Language Models are Few-Shot Learners》的发表,标志着暴力出奇迹的GPT家族又添新成员:GPT-3!
2019年初,GPT-2一经发布就刷新了7大数据集SOTA,并且能在未经预训练的情况下,直接跨任务完成阅读理解、问答、机器翻译、文本总结等多项不同的语言建模任务,GPT-2模型基于Transformer,是2018年OpenAI发布的无监督NLP模型GPT的直接拓展,新模型用到的参数和训练数据,都增长了超过10个数量级:拥有15亿参数,使用含有800万网页内容的数据集训练。
而刚刚发布的GPT-3,与GPT-2拥有相同的模型和架构,包括修改的初始化,预规范化(pre-normalization)和可逆记号化(reversible tokenization),不同之处在于,在transformer各层中使用了交替密集和局部带状稀疏注意力模式,类似于spare transformer。
为了研究ML性能对模型大小的依赖性,研究人员训练了8种不同大小的模型,范围从1.25亿个参数到1,750亿个参数,超过三个数量级,最后一个模型称为GPT-3。
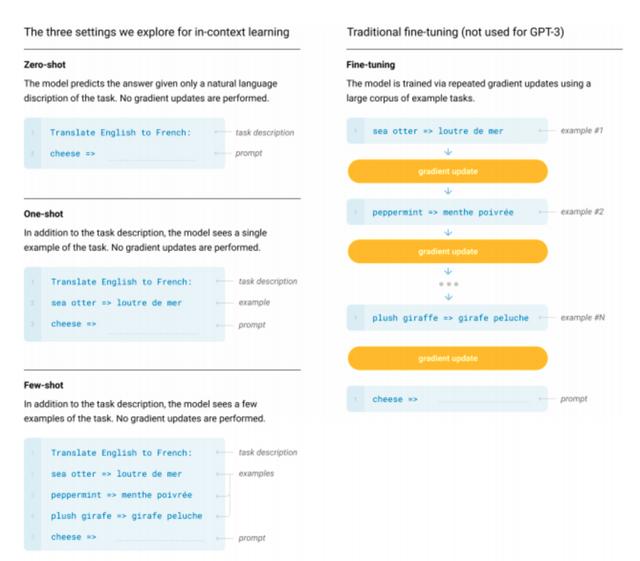
GPT-3模型在一系列基准测试和特定领域的自然语言处理任务(从语言翻译到生成新闻)中达到最新的SOTA结果。
有知乎网友评论道:
别说run 这个1700亿参数的预训练模型了,光是45TB的训练数据,我1/20都装不下了。还fine-tune个屁,有见过人用窜天猴去调试火箭发射井嘛?
最开始是research不动,后来是train不动,之后是finetune不动,现在练forward都搞不起来了,下一步是不是模型都save不下来了,没天理啊
论文:
https://arxiv.org/abs/2005.14165
Github:
https://github.com/openai/gpt-3
以下是论文摘要:
最近的工作证明了使用大量文本进行预训练,然后对特定任务进行微调(fine tuning),可以在许多NLP任务和基准方面的得到巨大的提升。
虽然在预训练过程中通常与任务无关,但该方法仍然需要针对特定任务的微调数据集。这样的微调数据集包含成千上万个示例。相比之下,人类通常只要通过几个示例或简单的指令来执行新的语言任务-当前的NLP系统在很大程度上仍难以做到这一点。
在这里,我们证明了规模更大的语言模型可以极大地提高无关任务和小样本的性能,有时甚至优于最新的基于微调的SOTA方法。具体来说,我们训练了GPT-3(一种具有1750亿个参数的自回归语言模型,参数量是以前的任何非稀疏语言模型的10倍),并在小样本设置下的测试中评估了它的性能。
对于所有任务,应用GPT-3无需进行任何梯度更新或微调,仅需要与模型文本交互为其指定任务和展示少量演示即可使其完成任务。GPT-3在许多NLP数据集上均具有出色的性能,包括翻译,问答和完形填空,以及一些需要即时推理或适应特定领域的任务,例如单词解密(unscrambling words),在句子中使用新单词或执行3位数的算术运算。
同时,我们还识别了一些GPT-3的小样本学习仍然困难重重的数据数据集,以及一些数据集,GPT-3面临大型Web语料库中训练的方法论问题。
最后,我们发现GPT-3可以生成新闻文章的样本,人类评估员很难将其与人类撰写的文章区分开。我们将讨论这一发现以及GPT-3对社会的广泛影响。
图灵社区:https://www.turingtopia.com/
还没看够?来群里获取更多新鲜事吧!
图灵学术交流群、技术交流群已成立,扫码添加小助手即可入群。
学术群,旨在交流顶会论文、顶刊写作与投稿事宜,还有不定期的算力与数据集等资源分享。
技术群,旨在分享NLP、目标检测、全景分割、人脸识别、活体检测、姿态估计、OCR、deepfake、自动驾驶、算法、芯片等多领域多行业的最新进展。
加小助手请备注:学校/公司 研究方向 昵称(如北航 AutoML 小灵),根据格式备注,可更快通过并被邀请入群。

▲长按加群

花粉社群VIP加油站
关于作者

猜你喜欢





































