AI自1956年提出以来一直呈渐进式发展,前期发展缓慢,但随着半导体工业技术的发展,芯片算力在近二十几年中的指数型增长,AI的发展也拥有了更好的载体。
众所周知AI的根本动力与核心资源是算力与数据。半导体芯片行业发展到如今3nm的制程工艺加之几十年的芯片设计经验积累,可以说算力的提升已经达到相当的水平,逐渐到了AI大展拳脚的时候了。

在谈到GPT3之前不得不提到一个名词OpenAI,这是一个由埃隆马斯克联合众多硅谷大佬们在2015年创立的“非盈利”人工智能领域的组织,宗旨为朝着人类最大化福祉的方向推动人工智能的发展。通过与世界知名大型公司苹果、谷歌、IBM等协同合作共同探索先进的计算机技术,主要解决面部识别、语言翻译等问题,而GPT3所擅长的NPL自然语言处理正是由这一组织所开发的(NPL研究计算机处理、理解以及运用人类语言最终实现人与计算机的有效通讯)。

GTP代表的是生成式预训练Transformer,最初在2018年OpenAI(硅谷大佬们2015年创立的“非盈利”组织)的研究人员(微软提供算力、资金、openai提供技术)尝试将炙手可热的生成式深度学习架构与无监督预训练(自监督学习)相结合最终得到GPT模型。其本质也可以说就是一个自然语言处理(NPL)模型,也是人工智能领域的重要研究方向,目的是让机器听懂人话实现人与计算机间的有效通讯。
 GPT3所在NPL领域的广泛应用
GPT3所在NPL领域的广泛应用其实NPL早已应用于我们生活的方方面面,并非今天才出现,GPT3只是将这一过程直观化并显现出十分惊喜的效果罢了。
包括我们每天都在刷的抖音、微博、淘宝、新闻等平台的首页都是机器算法推荐给用户的。该页面便是NPL自然语言处理,该技术收集用户搜索、发布、购买过的东西进行处理分类构建人物画像,识别并推送你喜欢或者可能感兴趣的东西,甚至能潜移默化引导你,这时你会觉得机器能理解你。而各大公司都是通过识别用户的自然语言来推动精准营销增加收入,据数据统计世界电商巨头亚马逊通过精准推送增加了35%左右的收入,当然类似的还有各类电商平台、类容分发平台以及各类工具类APP。
而如今的GPT3已经不是在后台默默地收集用户信息,根据其对应行为分析模型构建人物画像。其无论是在语言精准识别、对话以及各类强大的功能性应用上都崭露头角。并且已经在写作领域通过了图灵测试,也就是说从其创作的文章中你已经分不清哪个是GPT3创作哪个是人工创作,在多次测试中甚至认为AI的文章更加像人类创作的。下面让我们来了解其强大的功能。
GPT3众多强大的功能应用自从GPT3问世以,不少申请其API接口的人们获得了“门票”同时也将GPT3玩出花样,并相继在网上发表自己的成果,在一个GitHub项目的托管平台的项目中展出了整整50种GPT3的玩法,包括编程、程序员面试、回复邮件、UI设计、回答数学问题、法律语言转化、总结中心思想、推理等。
1、编程
如今的GPT3已经可以实现功能强大的无代码开发了,例如你告诉它你想要什么样的网页或者APP,只要你描述得足够详细它就能准确理解并生成代码。国外已经有人用GPT3编写了开发代码的应用,你在文本框中输入你想开发的前端的样子,代码与成品预览便能准确无误的立即生成。
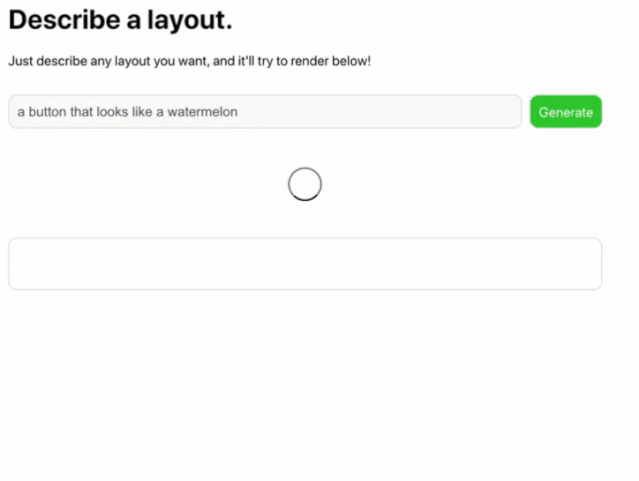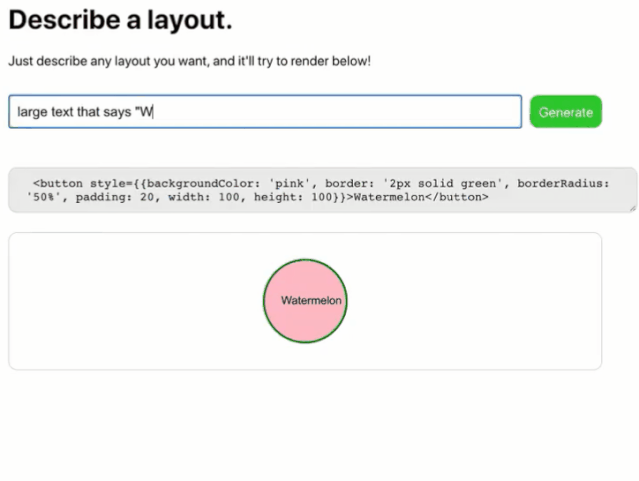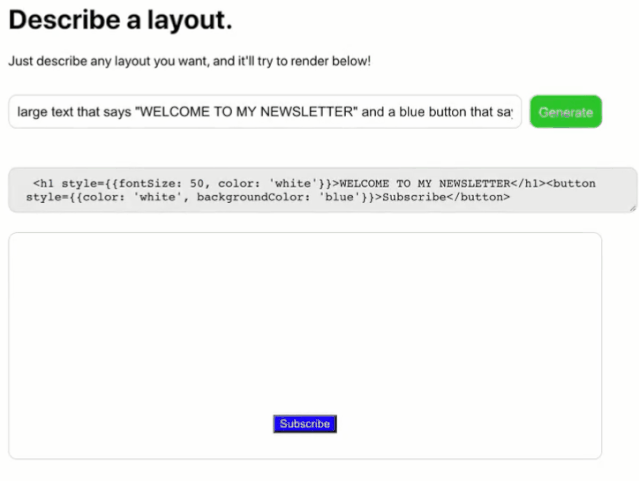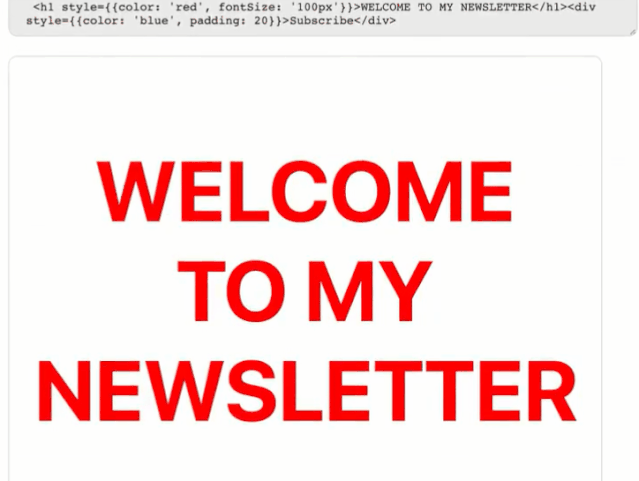
上图中显示了用GPT3开发的一款UI设计软件,在创建框中输入:“创建一个带照相机图标、Photo为标题、信息图标的导航栏,在应用中发送照片,每张照片有一个用户图标、一个点赞图标,和一个聊天泡泡图标”得到如下视图的UI设计。
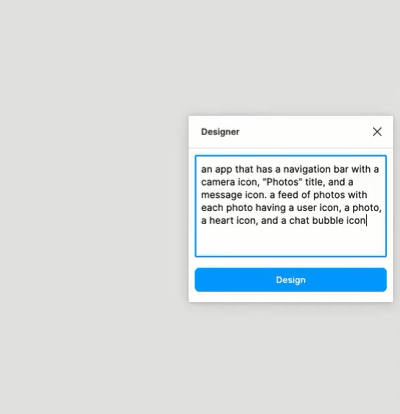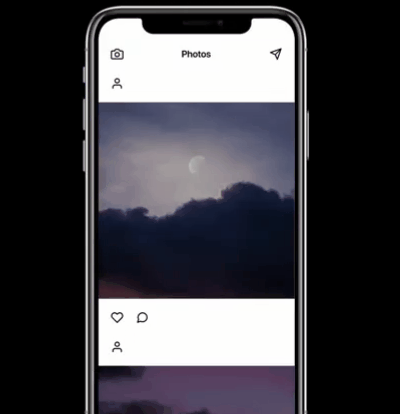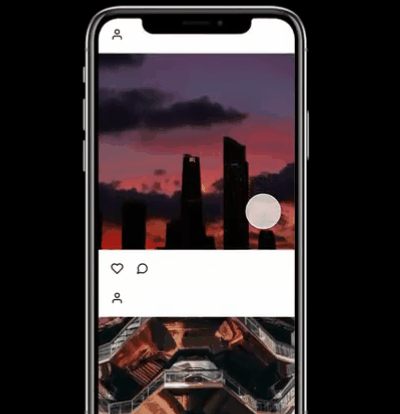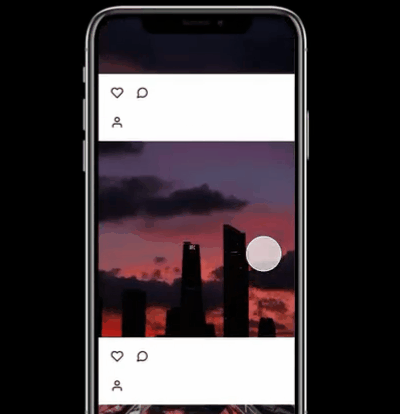
可以说已经十分惊艳了。
3、内容创作与新闻资讯编辑
GPT3出现之前小生只知道很多村里的大妈大爷被聚集起来写网文的情况,一少部分机器写的文章很容易被辨识出来,而如今GPT3的文章不可谓强悍。

一位来自美国加州大学计算机系名叫Liam Porr的小哥已经用GPT3写博客做自媒体,其文章已经登上了新闻平台技术板块热门榜第一。你没看错就是热榜第一,这得益于其巨量的数据库训练及与独特的注意力模式。优秀的关联模式注意力算法使得其擅长编写漂亮的辞藻加上众多专业书籍知识的数据集,很容易迷惑一大批非专业人士。但其实并不擅长逻辑关系,翻译过来便是借鉴的东西太多,单独一段辞藻华丽看似很有道理,不过联系前后文逻辑关系不能太复杂。该特性恰好适合很多不需要严格逻辑论证的文章,例如鸡汤文,GPT3尤其擅长。
不过这也不能影响GPT3写作十分强悍的结论,国外甚至已经有好事者在《权力的游戏》烂尾后使用当时的GPT2重写剧本,剧情精彩,很多网友表示AI剧本比原著写得更好。
4、搜索与数据分析
就如Google或百度搜索一样,GPT3同样拥有强大的搜索能力。不同之处在于由于大量数据集的训练与注意力算法,其回答更加人性化。
搜索:
最明显的区别便是你用Siri时如果遇到稍微刁钻一点的问题它便不能明白你说什么甚至直接打开浏览器搜索了,而GPT-3能理解你说的什么进而像与人交流一般回答你的问题。例如你问他馒头为什么软乎乎的,它能充分理解软乎乎的意义并会详细回答你那是因为酵母菌无氧呼吸产生二氧化碳、二氧化碳受热会使馒头膨胀等等,并非生硬的给你一个百度百科链接之类(虽然他的知识也来自于数据集),而是亲口给你诉说,总之你能感受到很像与人在交流。

数据分析:
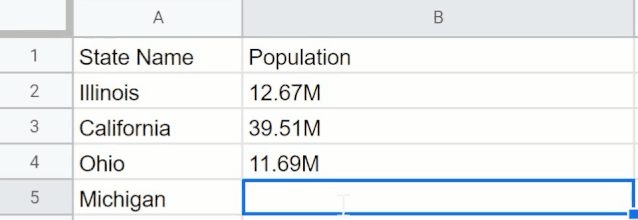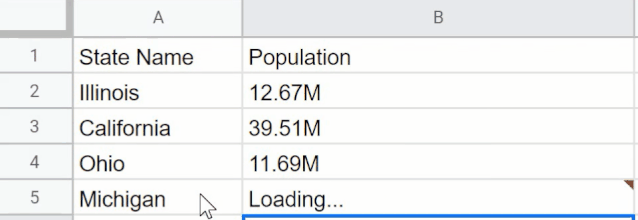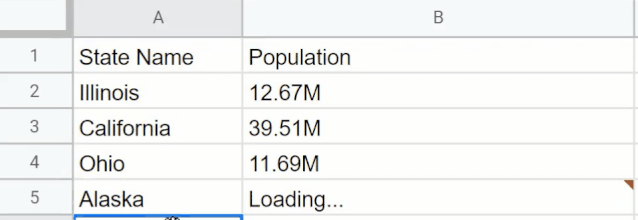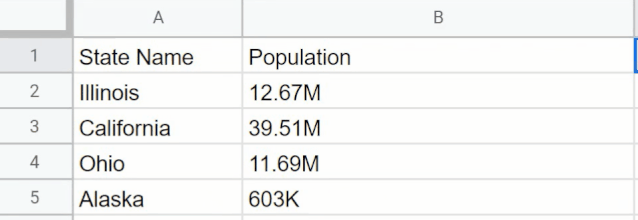
GPT3还能扩充如Excel之类表格中的信息,也就是能识别已有的数据展示模式,当地输入另一个名称时自动给出数据(本地没有数据的自动联网查询),省去繁杂的数据查询步凑。
同样它能根据输入的描述信息创建图形列表(柱状图之类)以及对应的python代码(最近较火的编程语言,拥有简洁方便的特点多用于人工智能领域)。
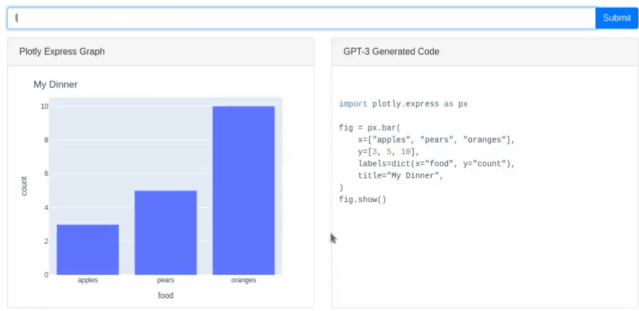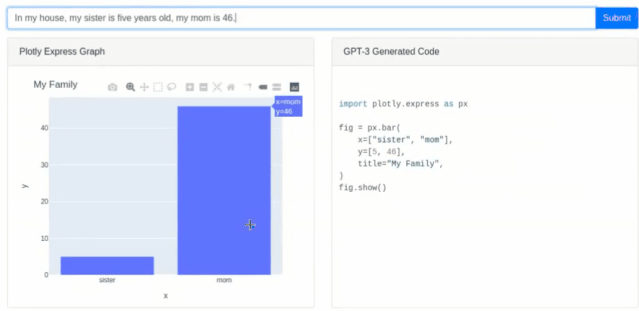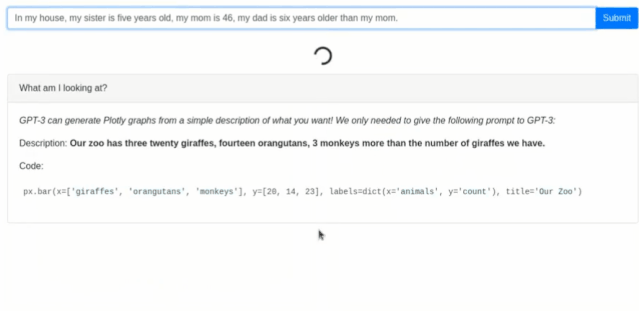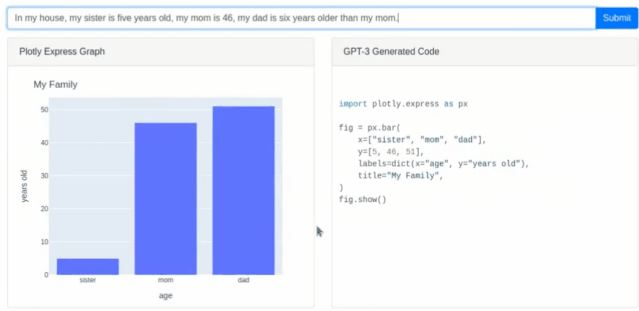
5、创意性工作灵感支持
在诸如谱曲、绘画等艺术性创作公众中,GPT-3能充分理解你的需求,你描述得越详细便能创作出更符合你心意的作品,虽然可能离你理想中的作品还有差距,但至少能给与你创作上的灵感支持,毕竟它是汇总了整个互联网的数据库依靠独特的算法创作出的作品。
6、与人聊天
经历过大量数字化训练的GPT-3无疑是非常博学多才的,由于其吸收了大量不同领域乃至哲学相关的知识,这意味着当你与之交谈时它能调用众多知识以理服人。无论你有专业知识、情感咨询诉说、哲学探讨相关需求。你都能与GPT-3聊得非常开心,就算不能给出理想答案但也能通过与其相关的其它答案获得灵感。此外我们都知道人与人间需要交流,如此人性化的AI加上私人性格定制,相信定会拥有广泛的市场。

以上可知GPT3类型的AI拥有极其广泛的应用场景,也正是如此OpenAI在其发布第二代产品GPT2不久之后便宣布开始商业化实践,并且微软也如对待亲儿子般带着10亿美元与云计算服务入局。也许正是由于其强大的潜力,之前一直号称非盈利开放的OpenAI便反悔不再开源完整GPT模型仅开放一部分。而在如今的GPT3中甚至直接不开源仅仅开放一些API接口供个人开发者、学校以及研究机构使用,企业要想使用不好意思得付费。在这条道路中我们看到原本开放的AI行业正逐渐被资本所裹挟与控制。
GPT3是如何变得强大的?就如战胜人类世界冠军棋手的Alpha Go一样,一个AI要变得智能首先要对大量数据进行学习,一般采用的是如今炙手可热的深度学习,在该模型中只需给机器输入一个明确的目的让其与自己对弈,在该学习中当然是数据越多目的越准确。然后在学习一段时间后通过外部的引导与查漏补缺让其在某一领域专精,而GPT3在以下方面的改变使得其脱颖而出。
1、注意力模式
GPT3与GPT2使用的模型与构架基本相同,提升点在于transformer的各层上都使用了交替密集和局部带状稀疏的注意力模式。
就如我们阅读文章的时候,通常会联系上下文,将注意力放在最相关重要的信息上来理解其真正意义。而如果将注意力放在不相关的片段上对整个阅读理解将会产生负面影响。所以理解需要准确有效的注意力。
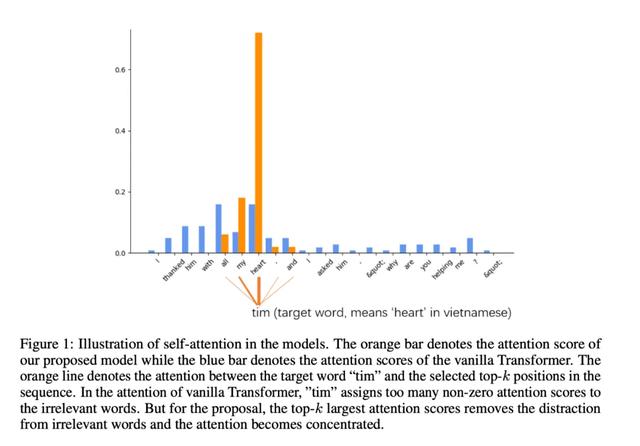
该规则同样适用于NPL领域的GPT3,同理注意力一直是自然语言理解与语言模型生成的核心组成。GPT3的交替密集与局部带状稀疏的注意力模式只关注K个最大贡献的状态,其他相关度与查询度低的值被归为0,相比传统注意模式可能造成的负反馈识别更加高效与准确。
2、训练数据集大幅度增加
这里的领域包含多方面,可以是与人聊天、文学创作、数学计算、甚至是编程
其实GPT3与前代GPT2就逻辑算法层面其实大同小异,区别在于其学习的参数是前代的100多倍达到1750亿,而训练的数据集相比上一代的40GB增加到了45TB,据了解包含600万篇文章的英文维基百科全书仅占其学习总数据集的0.6%,其余还包含大量数字化书籍与网络链接,就结果来说它是一个包含文学、政治、医学、法律、宗教等知识的百科全书。最终导致训练出的模型本体达到700GB而上一代只有5GB。

这100多倍的差距直接带来如今GPT3优异的智能水平,而微软帝国的加入提供给GPT3自家全球顶级的云计算服务与世界排名前五的超级计算机使得其能实现如此大规模的计算(运算一次GPT3模型成本约1200万美元),算力与数据的加持最终成就了GPT3优异的智能水准。
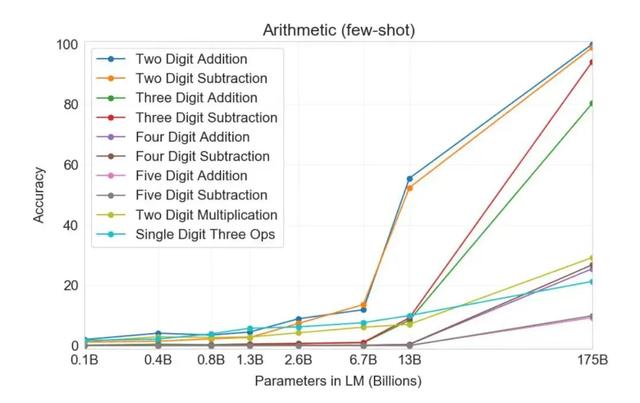
通过上图可以知道可以知道,机器训练的模型规模越大,识别率也随之增加。尤其是当样本数量达到13亿后,GPT3的准确率增强速度更加显著增强,可以说训练模型的数量是非常重要的。
GPT3存在的不足之处不过智能如GPT3也并非在每个领域都通过了图灵测试,并非完美,还远达不到通用人工智能AGI的标准(人工智能专家们梦寐以求的圣地,一个如人类一般思考与行事的多用途AI)。
例如对一些无意义的问题,GPT3照样也能给出不明所以的回答。
问:一个地球上有多少个绯想天?
答:一个地球上有3个绯想天。
问:从北京到华盛顿需要多少个太阳?
答:从北京到华盛顿需要2个太阳。
问:头有几只手?
答:头有两只手。
之类无意义的答案有很多,甚至在一些物理问题上GPT3也显得捉襟见肘,对问题原理的理解还停留在数据训练的层面。就目前来说它还仅仅是一个语言模型根据输入的文本推理字符的概率分布进而挑选出一个,其实根本没有理解你说的是什么。就如今所展现出的喜人成就也许存在精心挑选的成功案例。
与人类的差距:
GPT3目前还无法执行复杂的逻辑推理,就算将同一句话换一种说法后,它也会立刻出错,说明其理解能力还未达到AGI通用阶段,仅停留在语言层面,不能实现对物理场景的理解。目前GPT3的宽度仅为2048个token,代表其理解上下文的数量,而人类通过学习可以记住大量知识并将其上下文相关联。

对于AI而言就如“聪明的汉斯”一样,通过观察人类的反应来做算术题。GPT3也通过学习大量数据集了解人类语言的表达,将学习到的词汇转化为其维度中的节点,不断寻找通往通往下一个关联节点的捷径。但却并不像人一样拥有人类的各类感官认知的维度真正理解事物的本来面目,也许这正是目前AI的局限性,无论增加多少模型数据集也不能感知到其表达出事物的本来意义,是因为GPT3无法突破其感官认知的维度,进而永远也无法超越数据本身。
未来NPL人工智能展望感知便是力量
上文中说到,GPT3由于其连接参数(联结整合上下文)与神经感知(理解事物的信息来源)不全所限,并不能理解事物本来的模样。

在今年10月30日开幕的第三届世界顶尖科学家论坛上,被称为“硅谷教父”的美国计算机科学家约翰.轩尼斯发表的《AI,赋能美好生活》中也指出大脑是有史以来最伟大的学习机器,人类能理解什么是猫什么是狗,而AI只能通过数据学习分清其区别而并不能认识其本质告诉你为什么。这便涉及到机器感知的领域了,并且单一感知是很难实现性能大幅度提升必须多源信息融合,例如你看到一个东西便知道闻起来什么味道,抓起来什么声音,摸起来什么感觉,吃起来什么味道。正是这一系列的感官信息的融合促成了你对该事物较为全面的理解。不是简单抠字眼的GPT3所能实现的。
未来展望
算力无疑是AI的核心,随着摩尔定律的到来科学家们也在另辟蹊径探索大规模神经网络数据中心来突破进而实现更加智能的AI。

最近世界顶尖科学家论坛上大家也都在关注人脑相关的领域,研究不同行为大脑神经的反应与应答机制。借此如有实质性突破的话当然对AI的发展也是革命性的。
我们的大脑拥有约860亿个神经元与1000万亿个神经突触也就是连接参数,而GPT3的连接参数仅有1750万个,从数量上比还差了几个数量级,不过正如对比GPT2的进步,GPT4的连接参数至少又会扩大十几倍,也许不久AI的连接参数也将进入人脑的万亿级别。
届时其不仅能处理文字语言也能处理图片、声音、视频甚至人类的五感信息也未可知,最终赶上人类的大脑。
GPT3巨大的商业价值
综上所述,GPT3在各类应用场景中拥有巨大的潜力,这也是微软愿意与OpenAI合作耗巨资并提供世界顶级超级计算机与云计算服务器的原因。其在众多应用场景中都能实现直接替代或强大的支持。今后我们的搜索也不是像如今在搜索框中输入较为准确的关键词,而是直接人与人交流的大白话,例如你问女朋友为什么黏人,它会直接文字或语音回答你,依据感情的培养原理、年龄、性格等方面给你分析得头头是道,甚至在拥有你的个性人物画像后针对个人做出针对性的回答,你会觉得机器是如此的懂你,而不像如今搜索出的各类人工的文章以及回答(虽然其学习源数据也来源于各类资料)。

我们知道人工智能的核心动力是数据与算力,从某种程度上来说数据越多越智能,有人设想如果将整个互联网的数据喂给一个AI再加上强劲的算力与神经感知系统,那么其是否可以无限接近甚至超越人类?该想法似乎不无道理,只是计算能力的突破似乎来到了近年来炙手可热的量子计算机上,那便是另一个话题了。
总之虽然GPT-3展现出的惊人天赋使我们眼前一亮,让我们意识到其蕴藏的巨大价值与潜力,但也意识到其不足之处,不仅数据训练的数量,对多方面信息的感知与融合同样决定了其是否理解事物的本质,同时我们还得研究人脑的结构与运行机制,演化了几十亿年的人脑可没那么简单。如此也许AGI通用人工智能的时代才能真正到来。

花粉社群VIP加油站
关于作者

猜你喜欢





































