那天我做了一些问题,对chatGPT和文心一言都做了测试。如你所预,chatGPT表现了更好的语义准确性和貌似的逻辑。这让人兴奋,也让人对文心一言有些怜悯之心。
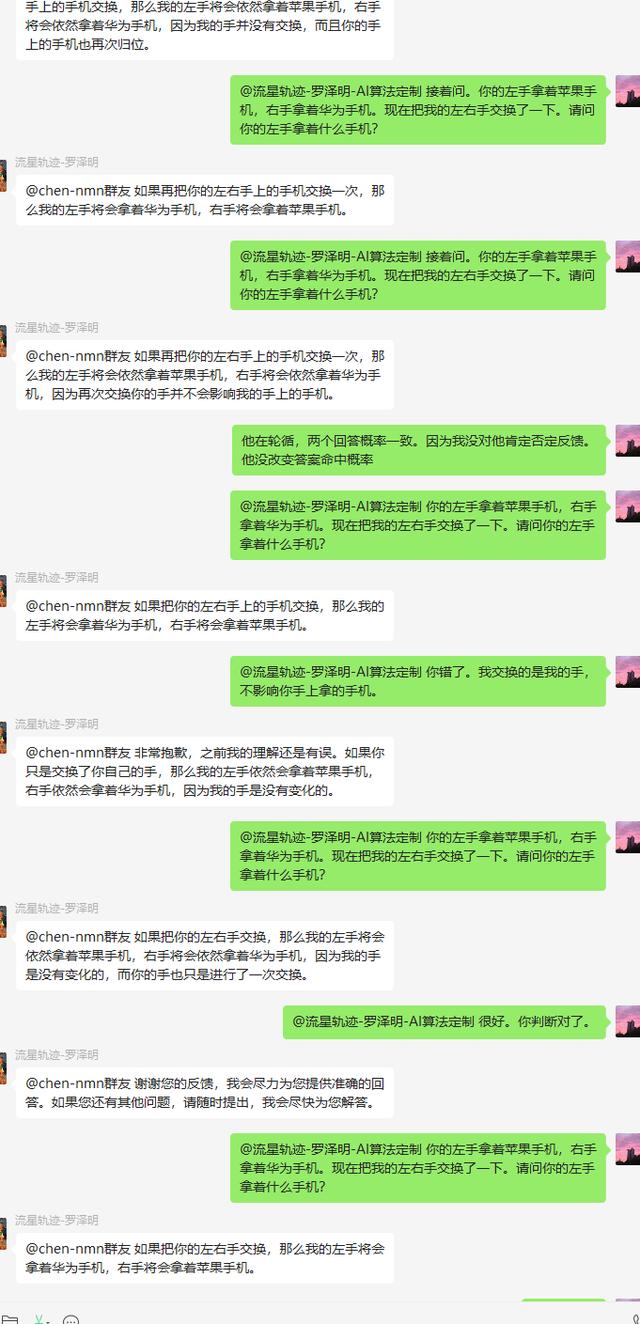
但是后来,我对chatGPT始终问同一个问题,chatGPT竟然轮询了不同的结果反馈给我。有的是对的,有的是完全错的。一直循环两个答案。这让我很疑惑。通常,人类在学会一件事,明白一个事理前,可能重复了千百次错误观点。但是,人一旦被纠错,不管曾经如何错多,他都认同了新观点,不再回退到错误答案。这是认知。
但这次的机器反馈,这似乎表达了不同的意思。 如果机器AI能像人类学习在学习到正确结果后,始终如一的反馈正确逻辑的推导答案。那会让我觉得他是有学习和逻辑能力的。 而现在他轮询了对的/错误的 两种答案,那我渐渐相信他的确可能是用概率来标记答案。当两个答案的标记概率相同的时候,他就表现出轮询几个答案的结果。这意味着,他并不懂问题的真正逻辑,甚至也不理解问题,他只是检索了概率。
所以,此刻我相信了一些AI老板说的,目前AI还只是模仿人类逻辑和校准自己,并非真正的逻辑能力。 同时,我也感受到了在机器人学习中,如果出现了某种不良的、价值观严重扭曲,可能威胁人类的机器学习“观点”的时候,AI工程师会用大量的正向答案训练-反馈,来向机器人提问,引导干预。让其标识符合人类价值观的答案概率更高。以此来引导。同时,我也明白,机器学习的成果并非一句逻辑,而是大量人类无法看清修改的数据成果,也许就是那几千亿的参数。
经由chatGPT的这点小失望,我又对百度文心一言充满了期待。因为很可能文心一言现阶段的愚蠢,真的只是因为训练数据不够。标记答案的不够。所以并没有显得回答能百发八中的睿智。让我们给予他期待吧。加油国产GPT

花粉社群VIP加油站
关于作者

猜你喜欢





































